Hbase和hive 有什么区别
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL 的引擎,并且运行MapReduce 任务,Hbase 是一种在Hadoop之上的NoSQL的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google 来搜索,用FaceBook 进行社交一样,Hive 可以用来进行统计查询,HBase 可以用来进行实时查询,数据也可以从Hive 写到Hbase,设置再从Hbase 写回Hive。
Hive是一个构建在Hadoop 基础之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS 上的数据。
HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive 不能够进行交互查询,因为它只能够在Haoop上批量的执行Hadoop。
Hive 被分区为表格,表格又被进一步分割为列簇。列簇必须使用schema 定义,列簇将某一类型列集合起来(列不要求schema定义)。
限制 :
Hive 目前不支持更新操作。
另外,由于hive在hadoop上运行批量操作,它需要花费很长的时间,通常是几分钟到几个小时才可以获取到查询的结果。
Hive 适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。
Hive 不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
HBase 查询是通过特定的语言来编写的,这种语言需要重新学习。类SQL 的功能可以通过Apache Phonenix 实现,但这是以必须提供schema 为代价的。另外,Hbase 也并不是兼容所有的ACID 特性,虽然它支持某些特性。最后但不是最重要的--为了运行Hbase,Zookeeper是必须的,zookeeper 是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase 进行消息和实时的分析。它也可以用来统计Facebook的连接数。
HBase 是一种Key/Value 系统,它运行在HDFS 之上。和Hive 不一样,Hbase 的能够在
它的数据库上实时运行,而不是运行MapReduce 任务
描述Hbase的rowKey的设计原则.
Rowkey长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在10~100 个字节,
不过建议是越短越好,不要超过16 个字节。
原因如下:
(1)数据的持久化文件HFile 中是按照KeyValue 存储的,如果Rowkey 过长比如100 个
字节,1000 万列数据光Rowkey 就要占用100*1000 万=10 亿个字节,将近1G 数据,这会极
大影响HFile 的存储效率;
(2)MemStore 将缓存部分数据到内存,如果Rowkey 字段过长内存的有效利用率会降
低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey 的字节长度越短越好。
(3)目前操作系统是都是64 位系统,内存8 字节对齐。控制在16 个字节,8 字节的
整数倍利用操作系统的最佳特性。
Rowkey散列原则
如果Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey
的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个
Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有
新数据都在一个 RegionServer 上堆积的热点现象,这样在做数据检索的时候负载将会集中
在个别RegionServer,降低查询效率。
Rowkey唯一原则
必须在设计上保证其唯一性。
描述Hbase中scan和get的功能以及实现的异同.
HBase的查询实现只提供两种方式:
1、按指定RowKey 获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get)
Get 的方法处理分两种 : 设置了ClosestRowBefore 和没有设置的rowlock .主要是用来保证行的事务性,即每个get 是以一个row 来标记的.一个row中可以有很多family 和column.
2、按指定的条件获取一批记录,scan方法(org.apache.Hadoop.hbase.client.Scan)实现条件查询功能使用的就是scan 方式.
1)scan 可以通过setCaching 与setBatch 方法提高速度(以空间换时间);
2)scan 可以通过setStartRow 与setEndRow 来限定范围([start,end)start 是闭区间,
end 是开区间)。范围越小,性能越高。
3)、scan 可以通过setFilter 方法添加过滤器,这也是分页、多条件查询的基础。
请描述Hbase中scan对象的setCache和setBatch 方法的使用.
为设置获取记录的列个数,默认无限制,也就是返回所有的列.每次从服务器端读取的行数,默认为配置文件中设置的值.
23 请详细描述Hbase中一个Cell 的结构
HBase 中通过row 和columns 确定的为一个存贮单元称为cell。
Cell:由{row key, column(=<family> + <label>), version}唯一确定的单元。cell 中的数
据是没有类型的,全部是字节码形式存贮。
---------------------
作者:秉寒CHO
来源:CSDN
原文:https://blog.csdn.net/haohaixingyun/article/details/52819563
这里在介绍下《Column-Stores vs. Row-Stores: How Different Are They Really?》
这个本文的目的是要告诉你Column-Store在存储格式优势只是一方面,如果没有查询引擎上其它几个优化措施的配合,性能也不会太好的,这篇论文认为Column-Store在查询引擎层有以下几种大的优化手段:
- 块遍历(Block Iteration)
- 压缩(Compression)
- 延迟物化(Late Materialization)
块遍历
块遍历(Block Iteration)是相对于单记录遍历(per-tuple iteration)而言的,其实说白了就是一种批量化的操作。单记录遍历的问题在于对于每个条数据,我们都要从Row数据里面抽取出我们需要的column(针对Row-Store来说),然后调用相应的函数去处理,函数调用的次数跟数据的条数成是
1:1的,在大数据量的情况下这个开销非常可观。而块遍历,因为是一次性处理多条数据,函数调用次数被降下来,当然可以提高性能。
这种提高性能的方法在Row-Store里面是case-by-case实现的(不是一种共识), 而对于Column-Store来说已经形成共识,大家都是这么做的。而如果column的值是字节意义上等宽的,比如数字类型,Column-Store可以进一步提高性能,因为查询引擎要从一个Block里取出其中一个值进行处理的时候直接用数组下标就可以获取数据,进一步提升性能。而且以数组的方式对数据进行访问使得我们可以利用现代CPU的一些优化措施比如SIMD(Single Instruction Multiple Data)来实现并行化执行,进一步提高性能。
压缩
压缩这种优化的方法对于Column-Store比对Row-Store更有效,原因很简单,我个人对压缩的理解是:
对数据进行更高效的编码, 使得我们可以以更少的空间表达相同的意思。
而能够进行更高效编码的前提是这个数据肯定要有某种规律,比如有很多数据一样,或者数据的类型一样。而Column-Store正好符合这个特点,因为Column-Store是把同一个Column -- 也就是相同类型的数据保存在一起,当然比Row-Store把一条记录里面不同类型的字段值保存在一起更有规律,更有规律意味着可以有更高的压缩比。
但是为什么压缩就能带来查询的高效呢?压缩首先带来的硬盘上存储空间的降低,但是硬盘又不值钱。它的真正意义在于:数据占用的硬盘空间越小,查询引擎花在IO上的时间就越少(不管是从硬盘里面把数据读入内存,还是从内存里面把数据读入CPU)。同时要记住的是数据压缩之后,要进行处理很多时候要需要解压缩(不管是Column-Store还是Row-Store), 因此压缩比不是我们追求的唯一,因为后面解压也需要花时间,因此一般会在压缩比和解压速度之间做一个权衡。
高压缩比的典型如Lempel-Ziv, Huffman, 解压快的典型如: Snappy, Lz2
前面提到解压缩,有的场景下解压缩这个步骤可以彻底避免掉,比如对于采用Run-Length编码方式进行压缩的数据,我们可以直接在数据压缩的格式上进行一些计算:
Run-Length的大概意思是这样的, 对于一个数字序列: 1 1 1 1 2 2 2, 它可以表达成 1x4, 2x3
这样不管进行 count (4 + 3), sum (1 x 4 + 2 x 3) 等等都可以不对数据进行解压直接计算,而且因为扫描的数据比未压缩的要少,从而可以进一步的提升性能。文中还提到对于Column-Store应用压缩这种优化最好的场景是当数据是经过排序的,道理很简单,因为如果没有经过排序,那么数据就没那么“有规律”,也就达不到最好的压缩比。
延迟物化
要理解延迟物化(Late Materialization), 首先解释一下什么是物化:为了能够把底层存储格式(面向Column的), 跟用户查询表达的意思(Row)对应上,在一个查询的生命周期的某个时间点,一定要把数据转换成Row的形式,这在Column-Store里面被称为物化(Materization)。
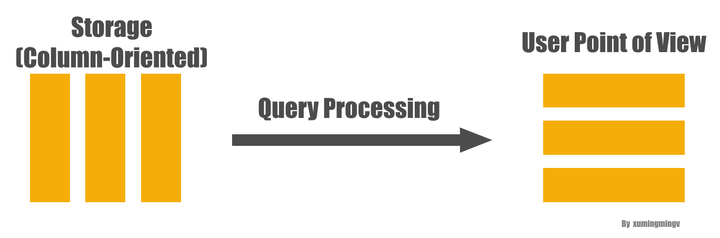
从列式存储到行式显示
理解了物化的概念之后,延迟物化就很好理解了,意思是把这个物化的时机尽量的拖延到整个查询生命周期的后期。延迟物化意味着在查询执行的前一段时间内,查询执行的模型不是关系代数,而是基于Column的(我也不知道怎么更好的表达这种“模型”,如果有知道的朋友欢迎告知)。下面看个例子, 比如下面的查询:
SELECT name
FROM person
WHERE id > 10
and age > 20一般(Naive)的做法是从文件系统读出三列的数据,马上物化成一行行的person数据,然后应用两个过滤条件: id > 10 和 age > 20 , 过滤完了之后从数据里面抽出 name 字段,作为最后的结果,大致转换过程如下图:
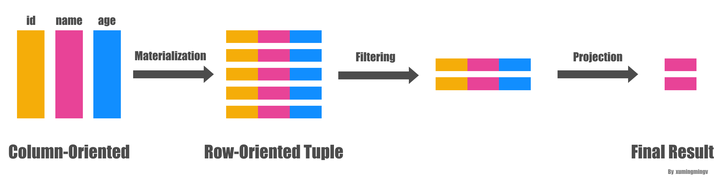
Early Materialization
而延迟物化的做法则会先不拼出行式数据,直接在Column数据上分别应用两个过滤条件,从而得到两个满足过滤条件的bitmap, 然后再把两个bitmap做位与(bitwise AND)的操作得到同时满足两个条件的所有的bitmap,因为最后用户需要的只是 name 字段而已,因此下一步我们拿着这些 position 对 name 字段的数据进行过滤就得到了最终的结果。如下图:

延迟物化
发现没有?整个过程中我们压根没有进行物化操作,从而可以大大的提高效率。
总结起来延迟物化有四个方面的好处:
- 关系代数里面的
selection和aggregation都会产生一些不必要的物化操作,从一种形式的tuple, 变成另外一种形式的tuple。如果对物化进行延迟的话,可以减少物化的开销(因为要物化的字段少了),甚至直接不需要物化了。 - 如果Column数据是以面向Column的压缩方式进行压缩的话,如果要进行物化那么就必须先解压,而这就使得我们之前提到的可以直接在压缩数据上进行查询的优势荡然无存了。
- 操作系统Cache的利用率会更好一点,因为不会被同一个Row里面其它无关的属性污染Cache Line。
块遍历的优化手段对Column类型的数据效果更好,因为数据以Column形式保存在一起,数据是定长的可能性更大,而如果Row形式保存在一起数据是定长的可能性非常小(因为你一行数据里面只要有一个是非定长的,比如VARCHAR,那么整行数据都是非定长的)。