Apache Hbase 全攻略
标签(空格分隔): Apache Hbase
一,Hbase 介绍
HBase 是以数据为中心,RDBMS 是以关系为数据,HBase 是 NoSQL 数据库中的列存储数据库,它有以下特点:强一致性读写,自动分片,HBase 通过 Region 分布在集群中,数据增加时,Region 会自动分割并重新分片。RegionServer 自动故障移取,HBase 支持 HDFS 之外的存储文件,HBase 通过 MapReduce 支持大并发处理,HBase 支持以 API 方式访问数据,HBase 以 Bloom Filters 和 Bloom Cache 对大量数据进行查询优化。HBase 适合场景是存在随机读写的埸景,每秒需要在 TB 级别数据上完成数以千计的操作,访问的操作的方式要简单、明确和直接,如果应用只是插入数据而且处理时需要读取全部数据。HBase 不支持二次索引、事务性数据、关联表的操作。HBase 的使用埸景:消息 (Message) 比如点赞,电商中的 SMS/ MMS,有随机读写的能力,局部数据进行 TopN 的查询、简单实体、图数据、指标。
「下图是一张 HBase 的表,概括了列族、列名和行之间的关系」()逻辑存储
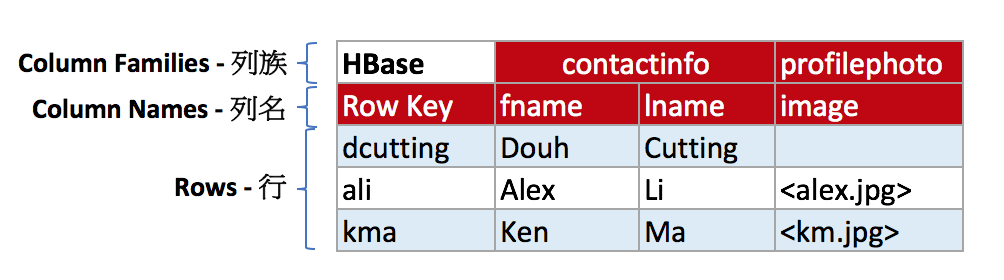
HBase 在表中存储数据,而表数据最后存储在 HDFS 上,数据被分割成 HDFS 块 (Block) 存储在集群的多个节点上,以128M为一个 BlockSize(HDFS Block Size 由 HDFS 存储层决定);
HBase 是由 Column Family (列族),Column (列) 和 Row Key (行) 组成的,列族是列的一个集合,列族可以有任意数量的列,e.g. contactinfo:fname, contactinfo:lname 它也可以单独对 每个列族 进行存储属性优化,比如对 profilephoto 进行压缩存储。
HBase 每一行都有一个 RowKey 用于快速检索,来保证一行数据的完整性,每个 RowKey 就类似于 RDBMS 的主键,HBase 表是基于 RowKey 进行快速检索,行按照RowKey 排序后进行存储,
HBase 底层磁盘上的文件是按照 Column Family 分开进行存储。这样的好处是相对于行存,占用空间会很小;
HBase 中间的数据是存储在 Cell 中,而且 Cell 是有版本化的,可以自定义保留多少过版本,Cell 为空时不存储。
二,HBase 集群体系结构
2.1集群搭建
2.1.1 必备条件(已经搭建好)
JDK 1.8
zookeeper Cluster
HDFS Cluster2.1.2 Hbase package(以1.3.0 为例)
配置jvm master regionserver 相关 jvm 参数
vim hbase-env.sh
export HBASE_LOG_DIR=/app/hbase/log
export HBASE_PID_DIR=/app/hbase/tmp
export HBASE_HEAPSIZE=16384
export HBASE_OFFHEAPSIZE=25g
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xmx16g -Xms16g -Xmn4g -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:+UseParNewGC -XX:ParallelGCThreads=12 -XX:+UseConcMarkSweepGC -XX:ParallelCMSThreads=
16 -XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=15 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:-DisableExplicitGC -XX:+HeapDump
OnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:/app/hbase/log/gc/gc-hbase-hmaster-`hostname`.log"
JMX_EXPORTER_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=19107 -java
agent:/app/exporters/jmx_exporter/jmx_prometheus_javaagent-0.12.0.jar=9107:/app/exporters/jmx_exporter/rs.yaml"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:+UseG1GC -Xmx20g -Xms20g -XX:+UnlockExperimentalVMOptions -XX:MaxGCPauseMillis=100 -XX:-ResizePLAB -XX:+ParallelRefProcEnabled -XX:+AlwaysPreTouc
h -XX:ParallelGCThreads=16 -XX:ConcGCThreads=8 -XX:G1HeapWastePercent=3 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1MixedGCLiveThresholdPercent=85 -XX:MaxDirectMemorySize=25g -XX:G1NewSizePercent=1 -XX:G1Max
NewSizePercent=15 -verbose:gc -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCApplicationStoppedTime -XX:+PrintHeapAtGC -XX:+PrintGCDateStamps -XX:+PrintAdaptiveSizePolicy -XX:PrintSafepointStatisticsCount=1 -
XX:PrintFLSStatistics=1 -Xloggc:/app/hbase/log/gc/gc-hbase-regionserver-`hostname`.log"
export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=20101"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=20102 $JMX_EXPORTER_OPTS"
export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=20103"
export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=20104"配置master regionserver 相关 运行时参数
vim hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rest.port</name>
<value>60050</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hbaseHadoop/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk地址,以逗号分割。</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<!-- replication -->
<property>
<name>hbase.replication</name>
<value>true</value>
</property>
<property>
<name>replication.source.ratio</name>
<value>1</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>200</value>
</property>
<property>
<name>hbase.hregion.majorcompaction</name>
<value>0</value>
</property>
<property>
<name>hbase.hstore.compactionThreshold</name>
<value>6</value>
</property>
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>100</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>4</value>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>21474836480</value>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>67108864</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>40</value>
</property>
<property>
<name>hbase.regionserver.maxlogs</name>
<value>256</value>
</property>
<property>
<name>hbase.regionserver.hlog.splitlog.writer.threads</name>
<value>10</value>
</property>
<!-- Memstore tuning-->
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.50</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.90</value>
</property>
<!--Flush All memstore bofore 5 h-->
<property>
<name>hbase.regionserver.optionalcacheflushinterval</name>
<value>36000000</value>
</property>
<!--Set Major Minor thread -->
<property>
<name>hbase.regionserver.thread.compaction.small</name>
<value>5</value>
</property>
<property>
<name>hbase.regionserver.thread.compaction.large</name>
<value>5</value>
</property>
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property>
<!-- Blockcache M 20G-->
<property>
<name>hbase.bucketcache.size</name>
<value>20480</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.30</value>
</property>
<!-- 开启Heged Read -->
<property>
<name>dfs.client.hedged.read.threadpool.size</name>
<value>10</value>
</property>
<property>
<name>dfs.client.hedged.read.threshold.millis</name>
<value>500</value>
</property>
<property>
<name>hbase.ipc.server.max.callqueue.size</name>
<value>2147483647</value>
</property>
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy</value>
<description>
A split policy determines when a region should be split. The various other split policies that
are available currently are ConstantSizeRegionSplitPolicy, DisabledRegionSplitPolicy,
DelimitedKeyPrefixRegionSplitPolicy, KeyPrefixRegionSplitPolicy etc.
</description>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.group.GroupAdminEndpoint</value>
</property>
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.hadoop.hbase.group.GroupBasedLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
<property>
<name>hbase.master.ui.readonly</name>
<value>true</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>multiwal</value>
</property>
<property>
<name>hbase.wal.regiongrouping.strategy</name>
<value>bounded</value>
</property>
<property>
<name>hbase.wal.regiongrouping.numgroups</name>
<value>1</value>
</property>
<property>
<name>hbase.hlog.asyncer.number</name>
<value>16</value>
</property>
<property>
<name>hbase.wal.storage.policy</name>
<value>ALL_SSD</value>
</property>
</configuration>所有机器环境变量统一
vim /etc/profile
# HADOOP CONFIG
export HADOOP_HOME=/app/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib/native"
export YARN_CONF_DIR=$HADOOP_CONF_DIR
export HIVE_HOME=/app/hive
export SCALA_HOME=/app/scala
export SPARK_HOME=/app/spark
export HBASE_HOME=/app/hbase
export ZOOKEEPER_HOME=/app/zookeeper
export GO_HOME=/app/go
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$ANT_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin:$PRESTO_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$GO_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
验证 Java Hadoop bin
java -XX:+PrintFlagsFinal -version
hadoop fs -help2.2 常用命令
2.2.1 启动停止集群相关
$ su - hbase
$ start-hbase.sh || ( hbase-daemon.sh start master && hbase-daemon.sh start regionserver)
# HMaster ThriftServer
$ jps | grep -v Jps
32538 ThriftServer
9383 HMaster
8423 HRegionServer
# BackUp HMaster ThriftServer
$ jps | grep -v Jps
24450 jar
21882 HMaster
2296 HRegionServer
14598 ThriftServer
5998 Jstat
# BackUp HMaster ThriftServer
$ jps | grep -v Jps
31119 Bootstrap
8775 HMaster
25289 Bootstrap
14823 Bootstrap
12671 Jstat
9052 ThriftServer
26921 HRegionServer
# HRegionServer
$ jps | grep -v Jps
29356 hbase-monitor-process-0.0.3-jar-with-dependencies.jar # monitor
11023 Jstat
26135 HRegionServer
# Usage
Usage: hbase [<options>] <command> [<args>]
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
hlog Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
version Print the version
CLASSNAME Run the class named CLASSNAME
# hbase版本信息
$ hbase version
root@VECS00996:/etc/salt/salt/hbase-1.3.0/conf# hbase version
HBase 1.3.0
Source code repository git://chenxi-QiTianM4650-N000/usr/code/inc-bdp-hms-hbase revision=38b6b12c92f74985ef5e411c706edd03456caf2f
Compiled by chenxi on 2018年 04月 13日 星期五 15:11:00 CST
From source with checksum 3f976107ab38ba6f4769cb874a475031
hbase@VECS00996:~$ hdfs dfs -ls /hbase
Found 11 items
drwxrwxrwx - hbase hbase 0 2019-11-28 00:25 /hbase/.hbase-snapshot
drwxr-xr-x - hbase hbase 0 2019-08-19 08:51 /hbase/.hbck
drwxr-xr-x - hbase hbase 0 2019-12-12 16:13 /hbase/.tmp
drwxr-xr-x - hbase hbase 0 2020-01-19 14:32 /hbase/MasterProcWALs
drwxr-xr-x - hbase hbase 0 2020-01-16 02:01 /hbase/WALs
drwxrwxrwx - hbase hbase 0 2018-12-26 11:50 /hbase/archive
drwxr-xr-x - hbase hbase 0 2018-08-24 21:34 /hbase/corrupt
drwxr-xr-x - hbase hbase 0 2018-08-02 16:27 /hbase/data
-rwxr-xr-x 3 hbase hbase 42 2018-08-02 16:27 /hbase/hbase.id
-rwxr-xr-x 3 hbase hbase 7 2018-08-02 16:27 /hbase/hbase.version
drwxr-xr-x - hbase hbase 0 2020-01-19 15:00 /hbase/oldWALs
# HBase 批处理
$ echo "<command>" | hbase shell
$ hbase shell ../script/batch.hbase
hbase shell 后面加跟 脚本路径
# HBase 命令行
$ hbase shell
# 连接远程 HBase 集群,需要把远程 HBase 的 Zookeeper 地址配置到 hbase-site.xml 中
$ vim hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk地址,逗号分割</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>
$ status
1 servers, 0 dead, 41.0000 average load
$ zk_dump
HBase is rooted at /hbase
Active master address: yuzhouwan03,60000,1481009498847
Backup master addresses:
yuzhouwan02,60000,1481009591957
yuzhouwan01,60000,1481009567346
Region server holding hbase:meta: yuzhouwan03,60020,1483442645857
Region servers:
yuzhouwan02,60020,1483491016710
# ...
/hbase/replication:
/hbase/replication/peers:
/hbase/replication/peers/1: yuzhouwan03,yuzhouwan02,yuzhouwan01:2016:/hbase
/hbase/replication/peers/1/peer-state: ENABLED
/hbase/replication/rs:
/hbase/replication/rs/yuzhouwan03,60020,1483442645857:
/hbase/replication/rs/yuzhouwan03,60020,1483442645857/1:
/hbase/replication/rs/yuzhouwan03,60020,1483442645857/1/yuzhouwan03%2C60020%2C1483442645857.1488334114131: 116838271
/hbase/replication/rs/1485152902048.SyncUpTool.replication.org,1234,1:
/hbase/replication/rs/yuzhouwan06,60020,1484931966988:
/hbase/replication/rs/yuzhouwan06,60020,1484931966988/1:
# ...
Quorum Server Statistics:
yuzhouwan02:2015
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Clients:
/yuzhouwan:62003[1](queued=0,recved=625845,sent=625845)
# ...
/yuzhouwan:11151[1](queued=0,recved=8828,sent=8828)
Latency min/avg/max: 0/0/1
Received: 161
Sent: 162
Connections: 168
Outstanding: 0
Zxid: 0xc062e91c6
Mode: follower
Node count: 25428
yuzhouwan03:2015
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Clients:
/yuzhouwan:39582[1](queued=0,recved=399812,sent=399812)
# ...
/yuzhouwan:58770[1](queued=0,recved=3234,sent=3234)
$ stop-hbase.sh三,实战技巧
3.1 Hive 数据导入(Bulkload)
Bulkload 就是 依据 Hive 表的 schema 解析 RCFile,然后通过 MapReduce 程序 生成 HBase 的 HFile 文件,最后直接利用 Bulkload 机制将 HFile 文件导入到 HBase 中。也就是 直接存放到 HDFS 中。这样比调用接口一条条的导入,效率会高很多(一般的,Hive 的数据入库到 HBase 中,都会采用 Bulkload 的方式)
3.2 集群间复制(CopyTable + Replication)
相关命令
| Commend | Commend |
| :--------: | :-----: |
| add_peer | 添加一条复制连接,ID 是连接的标识符,CLUSTER_KEY 的格式是 HBase.zookeeper.quorum: HBase.zookeeper.property.clientPort: zookeeper.znode.parent |
| list_peers | 查看所有的复制连接 |
| enable_peer | 设置某条复制连接为可用状态,add_peer 一条连接默认就是 enable 的,通过 disable_peer 命令让该连接变为不可用的时候,可以通过 enable_peer 让连接变成可用 |
| disable_peer |设置某条复制连接为不可用状态 |
| remove_peer | 删除某条复制连接 |
| set_peer_tableCFs |设置某条复制连接可以复制的表信息,默认 add_peer 添加的复制连接是可以复制集群所有的表。如果,只想复制某些表的话,就可以用 set_peer_tableCFs,复制连接的粒度可以到表的列族。表之间通过 ‘;’ 分号 隔开,列族之间通过 ‘,’ 逗号 隔开。e.g. set_peer_tableCFs ‘2’, “table1; table2:cf1,cf2; table3:cfA,cfB”。使用 ‘set_peer_tableCFs’ 命令,可以设置复制连接所有的表|
| append_peer_tableCFs | 可以为复制连接添加需要复制的表 |
| remove_peer_tableCFs | 为复制连接删除不需要复制的表 |
| show_peer_tableCFs | 查看某条复制连接复制的表信息,查出的信息为空时,表示复制所有的表 |
| list_replicated_tables | 列出所有复制的表 |
3.2 监控 Replication
HBase Shell
status 'replication'
Metrics
源端:
| Metrics Name | Commend |
| :--------: | :-----: |
| sizeOfLogQueue | 还有多少 WAL 文件没处理 |
|ageOfLastShippedOp |上一次复制延迟时间|
|shippedBatches |传输了多少批数据|
|shippedKBs |传输了多少 KB 的数据|
|shippedOps |传输了多少条数据|
|logEditsRead| 读取了多少个 logEdits|
|logReadInBytes| 读取了多少 KB 数据|
|logEditsFiltered |实际过滤了多少 logEdits|
目的端:
| Metrics Name | Commend |
| :--------: | :-----: |
|sink.ageOfLastAppliedOp |上次处理的延迟|
|sink.appliedBatches| 处理的批次数|
|sink.appliedOps| 处理的数据条数|
# 小集群上执行
# 预先进行 list_peers,避免 peer id 冲突
$ list_peers
$ add_peer '<peer id>', "<big cluster zk address>,<big cluster zk address>,...:<big cluster zk port>:/<hbase parent path>"
# 开启表的 REPLICATION_SCOPE
$ disable '<table name>'
# 1: open; 0: close(default)
$ alter '<table name>', {NAME => '<column family>', REPLICATION_SCOPE => '1'}
$ enable '<table name>'3.3 CopyTable 数据迁移
# 明确迁移时间
2017-01-01 00:00:00(1483200000000) 2017-05-01 00:00:00(1493568000000)
# 这里需要转换时间格式为 13 位的 毫秒级 unix timestamp
# 在线转换工具 http://tool.chinaz.com/Tools/unixtime.aspx
# 或者用 shell
$ echo "`date -d "2017-01-01 00:00:00" +%s`000"
$ echo "`date -d "2017-05-01 00:00:00" +%s`000"
# 这里不用担心出现 边界问题 [starttime, endtime)
# 源集群执行(不限制 starttime,可以增加参数 --starttime=0)
$ hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1483200000000 --endtime=1493568000000 --peer.adr=<aim zk address>,<aim zk address>,...:<aim zk port>:/<hbase parent path> <table name>
# 检查数据一致性(在两个集群分别执行,比较 RowCount 是否一致)
$ hbase org.apache.hadoop.hbase.mapreduce.RowCounter <table name> --endtime=1493568000000
# 进一步检查数据一致性(在两个集群分别执行,比较 字节数 是否一致)
$ hadoop fs -du hdfs://<base path>/hbase/data/<namespace>/<table name>
如果是拷贝至自身集群,则可以使用 new.name 参数,以创建新的表
CopyTable 仅仅适用于推数据到 另一独立集群或者本集群本身 的Hbase 表。
3.4 Trouble shooting
3.4.1 HBCK 检测工具
# 源集群执行
$ hbase hbck
# 出现问题后 hbase hbck --repair
# 也可以针对出问题的表 进行 hbase hbck --repair tablename
# 没有问题后 `hbase shell` 中执行
$ balance_switch true
3.4.2 关闭自动分区
alter 'table_name', {METHOD => 'table_att', SPLIT_POLICY => 'org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy'}3.4.3 JMX 获取部分指标项
# 语法
http://namenode:50070/jmx?qry=<指标项>
# 例如,只返回 NameNodeInfo 指标项
http://namenode:50070/jmx?qry=hadoop:service=NameNode,name=NameNodeInfo3.4.4 提示已经被删除的表,仍然存在
$ hbase zkcli 或者 使用zookeeper 本身的 zkCli.sh 进入zk 客户端与zookeeper 集群交互。
> ls /hbase/table
> rmr /hbase/table/${table_name}
# 重启 HBase 集群即可3.5 架构
3.5.1 Compaction (大合并 小合并)
介绍
一般的,我们会在一张 HBase 表中定义少量的 CF。而随着数据不断地写入到同一个 CF,为了避免 HStore 中单个的 HStoreFile 文件过大(默认 10G),会触发 Split 操作进行分裂。而对应于 Split 切割 HStoreFile 的行为,就是 Compaction 合并 HStoreFile 的操作。Compaction 的作用也是显而易见的,通过合并小的 HStoreFile,避免产生过多的小文件。同时 Compaction 操作小文件的时候,也不会带来严重的 IO 放大问题。另外,众多的业务场景,每个业务的数据分布的情况也不尽相同,因此 HBase 定义了 CompactionPolicy 接口,以便扩展选择 HStoreFile 的策略
Date Tiered Compaction Strategy
概念
HBase 2.x 中新的 Compaction 策略 DTCS,同样也是扩展了 CompactionPolicy 接口。主要是针对时序数据的场景,解决了默认策略无法针对时间维度进行 Compaction,导致一次查询命中过多的 HStoreFile 的问题,如下图所示:
https://picture.yuzhouwan.com/hbase_性能优化.png?imageslim
流程
如下图所示,整个时间轴被一个个时间窗口分割开,每 4 个时间窗口会被 Compact,从而组成一个大的 Tier(由 hbase.hstore.compaction.date.tiered.windows.per.tier 指定,默认值为 4;窗口的大小由 hbase.hstore.compaction.date.tiered.base.window.millis 指定,默认值为 6h)。时间轴最右边是最近一段时间写入的数据,刚形成的 HStoreFile 不会立即被 DTCS 选中,需要等数量达到一定阀值的时候(由 hbase.hstore.compaction.date.tiered.incoming.window.min 指定,默认值为 6),可以减少不必要的 Compact 数量。为了避免 Compact 已经写入很久的数据,则可以指定一个阀值,来控制距离当前时间多久的数据不被 DTCS 选中(由 hbase.hstore.compaction.date.tiered.max.storefile.age.millis 指定,默认值为 Long.MAX_VALUE)
优点
通过基于时间分层的存储结构,优化了针对时间范围的 Scan 查询请求
减少了 Compaciton 操作的开销
优化了 TTL 的处理效率
缺点
不适合非时序数据,并且如果时序数据完全乱序写入的话,还是可能会退化到默认的 Compaction 策略
频繁的更新和删除操作,性能会比较差
3.6 踩过的坑
3.6.1
Table is neither in disabled nor in enabled state
# 检查发现 table 既不处于 `enable` 状态,也不处于 `disable` 状态
$ is_enabled 'yuzhouwan'
false
$ is_disabled 'yuzhouwan'
false
$ hbase zkcli
$ delete /hbase/table/yuzhouwan
$ hbase hbck -fixMeta -fixAssignments
# 重启 active HMaster
$ is_enabled 'yuzhouwan'
true
$ disable 'yuzhouwan'