目录
Hive 配置
Hive是基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。Hive学习门槛较低,因为它提供了类似于关系数据库SQL语言的查询语言Hive QL,可以通过HiveQL语句快速实现简单的MR统计,Hive本身可以自动将HiveQL语句转换成MR任务运行,不必实现MR的api开发,因而十分适合数据仓库的统计分析;
Hive部署有三种部署模式:单用户、多用户和远程服务器模式。单用户模式连接到一个In-memory的数据库Derby,一般用于Unit Test;多用户模式是最常用到的部署模式,通过网络连接到一个数据库中,数据库一般选择MySQL存储Metastore元数据;远程服务器模式即Metastore元数据存储在远程服务器端的数据库中,客户端通过Thrift协议访问MetastoreServer数据库。
部署分两部分:先装mysql并创建用户和数据库,其次配置Hive;
配置
1、Mysql官网下载tar包,5.6.33(64位linux通用版),下载地址为:https://dev.mysql.com/downloads/mysql/5.6.html#downloads;在安装路径下/usr/local/解压、重命名为mysql;
注:getconf LONG_BIT 得到系统位数
2、新建mysql用户(属组mysql),将安装路径/usr/local/mysql的属主和属组变为mysql,新建数据路径/var/lib/mysql及/var/lib/mysql/data,将文件的属主和属组变为mysql;;
groupadd mysql
useradd -r -g mysql mysql
mkdir –p /var/lib/mysql/data
chown -R mysql:mysql /usr/local/mysql
chown -R mysql:mysql /var/lib/mysql3、安装数据库,传参:数据目录和安装目录;
sudo ./scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/var/lib/mysql/data --user=mysql4、启动脚本和配置文件修改:
./support-files/mysql.server和my.cnf;前者是启动时候运行的脚本,后者是启动时候读取的mysql配置,如果不做任何调整的话,默认的basedir是/usr/local/mysql,datadir是/var/lib/mysql/data,如果修改这两个参数需要修改很多配置量;
linux在启动MySQL服务时按照次序搜索my.cnf,先在/etc目录下找,找不到则会搜索"$basedir/my.cnf",linux操作系统在/etc目录下会存在一个my.cnf,需要将此文件更名为其他的名字,如/etc/my.cnf.bak,否则该文件会干扰正确配置,造成无法启动。
sudo cp ./support-files/mysql.server/etc/init.d/mysqld
sudo chmod755/etc/init.d/mysqld
sudo cp./support-files/my-default.cnf/etc/my.cnf//修改my.cnf配置文件中的数据目录和安装目录:
sudo vi/etc/init.d/mysqld
basedir=/usr/local/mysql/
datadir=/usr/local/mysql/data/mysql5、启动服务
sudo service mysqld start![]()
//关闭mysql服务
sudo service mysqld stop#查看mysql服务运行状态
sudo service mysqld status- 设置环境变量,并测试连接,配置登录权限:
#设置环境变量
export MYSQL=/usr/local/mysql
export PATH=${MYSQL}/bin:${PATH}
#赋权所有库下的所有表在任何IP地址或主机都可以被root用户连接
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
#修改root用户的登录密码(须停服务,完成后重启)
UPDATE user SET Password=PASSWORD(‘123456’) where USER=’root’;
flush privileges;7、创建hive库和hive用户,用来保存hive仓库的元数据信息,对hive用户赋权:
create database hive character set latin1;
create user hive;hive用户在表mysql.user下的赋权操作(略)
flush privileges;Hive的默认元数据保存在Derby中,这里修改其元数据库为mysql,需要下载mysql驱动,地址:https://dev.mysql.com/downloads/file/?id=480090,并将驱动复制到hive/lib文件中。
Hive读取的配置文件:hive-default.xml和hive-site.xml,可以不修改前者大量默认配置项,后者配置信息可以覆盖前者, 参考官网:Getting Started Guide;
1、在hdfs上新建hive的元数据路径
$HADOOP_HOME/bin/hadoop fs –mkdir /tmp
$HADOOP_HOME/bin/hadoop fs –mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse2、新建并修改hive-site.xml配置文件,如下(配置中读写元数据的mysql用户是root,权限太高,需优化):
cp hive-default.xml.template hive-site.xml
//hive-site.xml的详细配置:
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.19.52.155:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
</configuration>3、初始化hive元数据库,验证mysql设置是否成功(成功后hive库下的表会有很多hive的元数据表);
schematool -dbType mysql -initSchema![]()
启动和验证
完成以上配置,直接hive命令启动hive服务,测试建表;
![]()
//hdfs有相应的文件夹,说明配置成功:

问题
1、配置mysql并启动成功,但修改mysql.user表的登录用户配置信息后,重启发现localhost主机上root用户无法读取mysql的系统库(mysql库),解决方法:关掉mysql进程并删除datadir中的data目录后,重新初始化;
2、配置mysql库时候的登录权限问题,对用户和登录主机赋权;
![]()
HBase 配置
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化的和半结构化的松散数据。Hbase可以支持超大规模数据存储,可以通过水平扩展的方式,利用廉价硬件集群处理超过10亿元素和数百万列元素组成的数据集。
配置
配置参考官网:Example Configurations,需要修改3个配置文件:hbase-env.sh和hbase-site.xml和regionserver文件;
1、hbase-env.sh修改JAVA_HOME, HBASE_CLASSPATH, BASE_MANAGES_ZK,如果使用独立安装的zk,则HBASE_MANAGES_ZK 修改为false,这里复用之前部署的zk;
export JAVA_HOME=/home/stream/jdk1.8.0_144
export HBASE_CLASSPATH=/home/stream/hbase/conf
export HBASE_MANAGES_ZK=false2、hbase-site.xml文件设置zk地址和其他配置:
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.19.72.155,172.19.72.156,172.19.72.157</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/stream/zk/zookeeper/dataDir</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://172.19.72.155/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/stream/hbase/temp</value>
</property>
</configuration>3、修改regionserver文件,添加regionserver主机:
172.19.72.156
172.19.72.157
172.19.72.158
172.19.72.159启动和验证
在bin目录下运行./start-hbase.sh脚本,查看Hmaster进程,使用hbase shell指令启动hbase命令行建表,测试;

可以使用zkCli.sh进入zk查看hbase注册的节点信息:
![]()
问题
1、启动报错:java.lang.ClassNotFoundException:org.apache.htrace.SamplerBuilder
解决方法: cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
2、启动报错:Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
解决方法:在hbase-site.xml中增加配置:
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>Storm 配置
Strom为分布式、高可用的实时计算框架, Zookeeper负责Nimbus节点和Supervior节点之间的通信,监控各个节点之间的状态。提交任务在Nimbus节点上,Nimbus节点通过zk集群将任务分发下去,而Supervisor是真正执行任务的地方。
Nimbus节点通过zk集群监控各个Supervisor节点的状态,当某个Supervisor节点出现故障的时候,Nimbus通过zk集群将那个Supervisor节点上的任务重新分发到其他Supervisor节点上执行。
如果Nimbus节点出现故障的时候,整个任务并不会停止,但是任务的管理会出现影响,通常这种情况下我们只需要将Nimbus节点恢复就可以了。
Nimbus节点不支持高可用,这也是Storm目前面临的问题,一般情况Nimbus节点的压力不大,通常不会出问题。
配置
直接解压到/home/stream目录下.需要配置/home/stream/apache-storm-0.9.5/conf/storm.yaml,常用配置项及value 如下:
//配置zk的地址和端口和storm存放在zookeeper里目录
storm.zookeeper.server:
- “192.168.159.145”
- “192.168.159.144”
- “192.168.159.143”
storm.zookeeper.port: 21810
storm.zookeeper.root: /storm_new10
//storm主节点的地址 web页面的端口
nimbus.host: “192.168.159.145”
ui.port: 8989
//每个worker使用的内存
worker.heap.memory.mb: 512
storm.local.dir: "/home/zyzx/apache-storm-0.9.5/data"
//配置工作节点上的进程端口。你配置一个端口,意味着工作节点上启动一个worker,在实际的生产环境中,我们需要根据实际的物理配置以及每个节点上的负载情况来配置这个端口的数量。在这里每个节点我象征性的配置5个端口。
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 6700
nimbus.thrift.max_buffer_size: 204876
worker.childopts: “-Xmx1024m”启动和验证
控制节点启动nimbus和storm ui,其他节点启动Supervisor节点,通过JPS查看进程,主节点启动 nimbus进程,工作节点会启动 supervisor 进程;
nohup storm ui &
nohup storm nimbus &
nohup storm supervisor &storm的配置文件storm.yaml对格式规范要求高,多余空格可以造成读取配置失败,在启动所有节点后可以在zookeeper的zkCli客户端的root目录下查看storm下存活的supervisor节点数验证是否启动成功:

在~/storm/bin下运行./storm list命令列出在集群上提交的拓扑:

Spark (on yarn) 配置
Spark使用简练、优雅的Scala语言编写,基于Scala提供了交互式的编程体验,同时提供多种方便易用的API。Spark遵循“一个软件栈满足不同应用场景”的设计理念,逐渐形成了一套完整的生态系统(包括 Spark提供内存计算框架、SQL即席查询(Spark SQL)、流式计算(Spark Streaming)、机器学习(MLlib)、图计算(Graph X)等),Spark可以部署在yarn资源管理器上,提供一站式大数据解决方案, 同时支持批处理、流处理、交互式查询。
MapReduce计算模型延迟高,无法胜任实时、快速计算的需求,因而只适用于离线场景,Spark借鉴MapReduce计算模式,但与之相比有以下几个优势:
- Spark提供更多种数据集操作类型,编程模型比MapReduce更加灵活;
- Spark提供内存计算,将计算结果直接放在内存中,减少了迭代计算的IO开销,有更高效的运算效率。
- Spark是基于DAG的任务调度执行机制,迭代效率更高;
在实际开发中MapReduce需要编写很多底层代码,不够高效,Spark提供了多种高层次、简洁的API实现相同功能的应用程序,实现代码量比MapReduce少很多。
Spark作为计算框架只是取代了Hadoop生态系统中的MapReduce计算框架,它任需要HDFS来实现数据的分布式存储,Hadoop中的其他组件依然在企业大数据系统中发挥着重要作用;
Spark配置on yarn模式只需要修改很少配置,也不用使用启动spark集群命令,需要提交任务时候须指定任务在yarn上。
配置
Spark运行需要Scala语言,须下载Scala和Spark并解压到家目录,设置当前用户的环境变量(~/.bash_profile),增加SCALA_HOME和SPARK_HOME路径并立即生效;启动scala命令和spark-shell命令验证是否成功;Spark的配置文件修改如果按照管网教程不好理解,这里完成的配置参照博客及调试。
Spark的需要修改两个配置文件:spark-env.sh和spark-default.conf,前者需要指明Hadoop的hdfs和yarn的配置文件路径及Spark.master.host地址,后者需要指明jar包地址;
spark-env.sh配置文件修改如下:
export JAVA_HOME=/home/stream/jdk1.8.0_144
export SCALA_HOME=/home/stream/scala-2.11.12
export HADOOP_HOME=/home/stream/hadoop-3.0.3
export HADOOP_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export YARN_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export SPARK_MASTER_HOST=172.19.72.155
export SPARK_LOCAL_IP=172.19.72.155spark-default.conf配置修改如下:
//增加jar包地址,
spark.yarn.jars=hdfs://172.19.72.155/spark_jars/*该设置表明将jar地址定义在hdfs上,必须将~/spark/jars路径下所有的jar包都上传到hdfs的/spark_jars/路径(hadoop hdfs –put ~/spark/jars/*),否则会报错无法找到编译jar包错误;
启动和验证
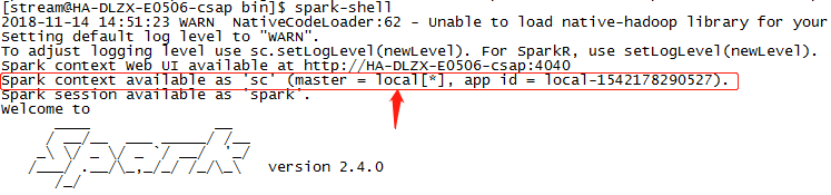
直接无参数启动./spark-shell ,运行的是本地模式:
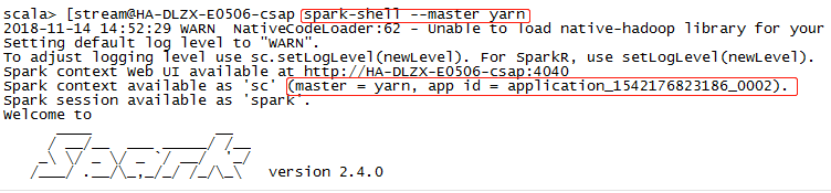
启动./spark-shell –master yarn,运行的是on yarn模式,前提是yarn配置成功并可用:
在hdfs文件系统中创建文件README.md,并读入RDD中,使用RDD自带的参数转换,RDD默认每行为一个值:

使用./spark-shell --master yarn启动spark 后运行命令:val textFile=sc.textFile(“README.md”)读取hdfs上的README.md文件到RDD,并使用内置函数测试如下,说明spark on yarn配置成功;

问题
在启动spark-shell时候,报错Yarn-site.xml中配置的最大分配内存不足,调大这个值为2048M,需重启yarn后生效。

设置的hdfs地址冲突,hdfs的配置文件中hdfs-site.xml设置没有带端口,但是spark-default.conf中的spark.yarn.jars值带有端口,修改spark-default.conf的配置地址同前者一致:

Flink (on yarn) 配置
Flink是针对流数据和批数据的分布式内存计算框架,设计思想主要来源于Hadoop、MPP数据库、流计算系统等,Fink主要是由Java代码实现,主要靠开源社区贡献而发展。Flink所处理的主要场景是流数据,默认把所有任务当成流数据处理,批数据只是流数据的一个特例,其支持本地快速迭代及一些环形迭代任务。
Flink以层级式系统形式组建软件栈,不同层的栈建立在其下层基础上,其特性如下:
- 提供面向流处理的DataStreaming API和面向批处理的DataSet API。DataSet API支持Java、Scala和Pyhton,DataStreaming API支持Java和Scala。
- 提供多种候选部署方案,如本地模式(Local)、集群模式(Cluster)、云模式(Cloud),对于集群而言,可以采用独立模式(Standalone)或者yarn;
- 提供了较好的Hadoop兼容性,不仅可以支持yarn,还可以支持HDFS、Hbase等数据源;
Flink支持增量迭代,具有对迭代自行优化的功能,因此在on yarn上提交的任务性能略好于 Spark。Flink是一行一行地处理数据,Spark是基于RDD的小批量处理,所以Spark在流式数据处理上不可避免地会增加一些延时,实时性没有Flink好。Flink和Storm可以支持毫秒级计算响应,Spark只能支持秒级响应。Spark的市场影响力和社区活跃度明显强于Flink,在一定程度上限制了Flink的发展空间;
配置
解压,进入bin目录下运行./yarn-session.sh –help 查看帮助验证yarn是否成功配置,./yarn-session.sh –q 显示yarn所有nodeManager节点资源;

Flink提供两种方式在yarn上提交任务:启动一个一直运行的 YARN session(分离模式)和在 YARN 上运行一个 Flink 任务(客户端模式),flink只需要修改一个配置conf/flink-conf.yaml ,详细参数请参考官网:
通用配置:Configuration,HA配置:High Availability (HA)
//需要设置 conf/flink-conf.yaml中的fs.hdfs.hadoopconf 参数来定位YARN和HDFS的配置;
//yarn模式下jobmanager.rpc.address不需要指定,因为哪一个容器作为jobManager由Yarn决定,不由Flink配置决定;taskmanager.tmp.dirs也不需要指定,这个参数将被yarn的tmp参数指定,默认就是/tmp目录下,保存一些用于上传到ResourceManager的jar或lib文件。parrallelism.default也不需要指定,因为在启动yarn时,通过-s指定每个taskmanager的slots数量。
//需要修改yarn-site.xml配置里面的yarn.resourcemanager.am.max-attempts,使得resourcemanager的连接的重试次数为4,默认是2;同时在flink-conf.yaml中增加yarn.application-attempts: 4;
//flink-on-yarn cluster HA虽然依赖于Yarn自己的集群机制,但Flink Job在恢复时依赖检查点产生的快照,这些快照配置在hdfs,但其元数据信息保存在zookeeper中,所以我们还要配置zookeeper的HA信息;其中recovery.zookeeper.path.namespace也可以在启动Flink on Yarn时通过-z参数覆盖。
flink-conf.yaml完整配置如下:
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# env
HADOOP_CONF_DIR:/home/stream/hadoop-3.0.3/etc/hadoop
YARN_CONF_DIR:/home/stream/hadoop-3.0.3/etc/hadoop
# Fault tolerance and checkpointing
state.backend:filesystem
state.checkpoints.dir:hdfs://172.19.72.155/yzg/flink-checkpoints
state.savepoints.dir:hdfs://172.19.72.155/yzg/flink-checkpoints
# hdfs
#The absolute path to the Hadoop File System’s (HDFS) configuration directory
fs.hdfs.hadoopconf:/home/stream/hadoop-3.0.3/etc/hadoop
#The absolute path of Hadoop’s own configuration file “hdfs-site.xml” (DEFAULT: null).
fs.hdfs.hdfssite:/home/stream/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
#HA
high-availability: zookeeper
high-availability.zookeeper.quorum: 172.19.72.155:2181,172.19.72.156:2181,172.19.72.157:2181
high-availability.storageDir: hdfs:///yzg/flink/recovery
high-availability.zookeeper.path.root: /flink
yarn.application-attempts: 4HA模式下需要配置zk,修改conf下的zoo.cfg;zoo.cfg配置如下:
dataDir=/home/stream/zk/zookeeper/logs
# The port at which the clients will connect
clientPort=2181
# ZooKeeper quorum peers
server.1=172.19.72.155:2888:3888
server.1=172.19.72.156:2888:3888
server.1=172.19.72.157:2888:3888启动和验证
采用分离模式来启动Flink Yarn Session,提交后提示该yarn application成功提交到yarn并返回id,使用yarn application –kill application_id 来停止yarn上提交的任务;
yarn-session.sh -n 3 -jm 700 -tm 700 -s 8 -nm FlinkOnYarnSession -d –st可以直接提交自带的词频统计用例,验证on yarn模式是否配置成功:
~/bin/flink run -m yarn-cluster -yn 4 -yjm 2048 -ytm 2048 ~/flink/examples/batch/WordCount.jar总结
以上基本完成大数据平台(包含批和流)的基础组件部署。综合而言,基于apache Hadoop的散装部署较为麻烦,需要自己适配组件,且组件的配置较多,配置较繁琐;目前完成的组件运行情况如下(on yarn模式的spark和flink无进程):