一、正则表达式
grep:显示匹配行
- -v:反显示
- -e:使用扩展正则表达式 grep -E “ ” xxx.txt 用来省去 扩展需要输入的
匹配操作符
- 转义字符
- . 匹配任意单个字符
- [1249a],[ ^ 12 ],[ a - k ] 字符序列单字符占位
- ^ 行首
- $ 行尾
- <, > 单词首尾边界
- | 连接操作符
- (,) 选择操作符
- \n 反向引用
重复操作符
- ?匹配0到1次。
- *匹配0到多次。
- +匹配1到多次。
- {n} 匹配n次。
- {n,} 匹配n到多次。
- {n,m} 匹配n到m次。
与扩展正则表达式的区别:grep basic
?, +, {, |, (, and )
匹配任意字符
.*
示例
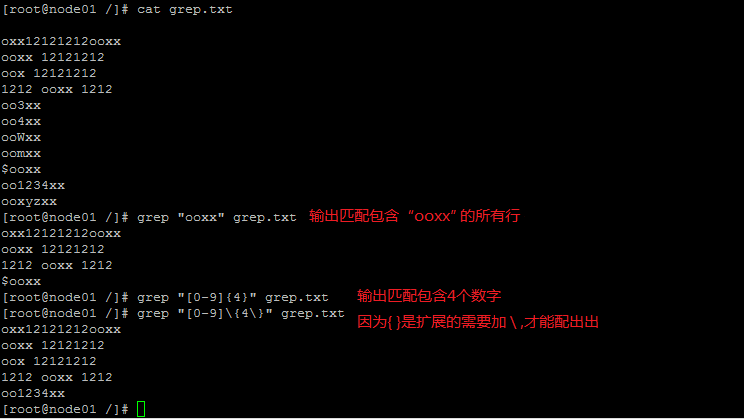
创建文件 grep.txt ,文件内容如下:
ooxx12121212ooxx
ooxx 12121212
oox 12121212
1212 ooxx 1212
oo3xx
oo4xx
ooWxx
oomxx
$ooxx
oo1234xx
ooxyzxx
示例2:
创建test文件,文件内容如下:
aaabbcaaa
aa bbc aaa
bb bbc bbb
asgodssgoodsssagodssgood
asgodssgoodsssagoodssgod
sdlkjflskdjf3slkdjfdksl
slkdjf2lskdjfkldsjl
接下来查看下列输出匹配各是什么结果:
cat test
- grep "a" test
- grep "a{3}" test
- grep "<aaa" test
- grep "<aaa>" test
- grep "b" test
- grep "b{2,3}" test
- grep "god" test
- grep "godgood" test
- grep "god*good" test
- grep "god.*good" test
- grep "god.* good.* god.*good" test
- grep "god.*good+" test
- grep " (god.*good )+" test
- grep " (god ).* good.*\1" test
- grep " (god ).* (good ).* \1.*\2" test 反向引用的例子
- grep " (god ).* (good ).* \1.*\2" test
- grep " (god ).* (good ).* \2.* \1" test
二、文本分析处理
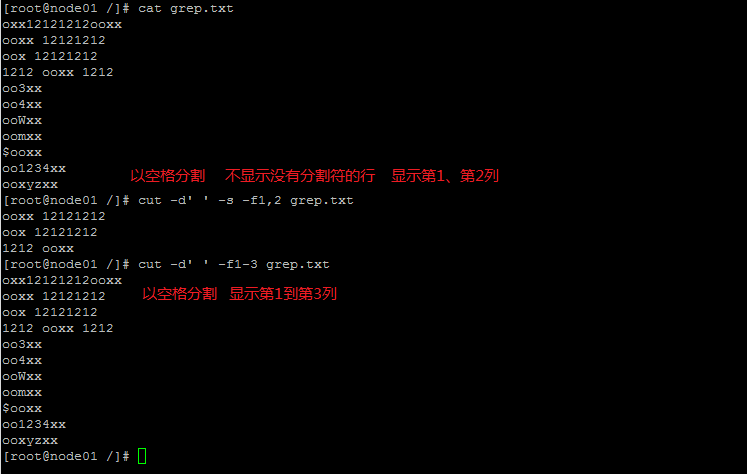
cut:显示切割的行数据
- -f:选择显示的列
- -s:不显示没有分隔符的行
- -d:自定义分隔符
示例:

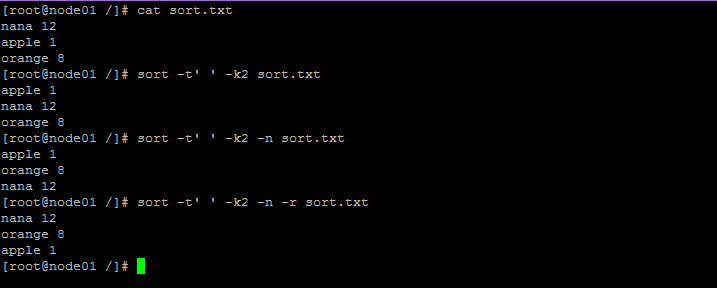
sort:排序文件的行
- -n:按数值排序
- -r:倒序
- -t:自定义分隔符
- -k:选择排序列
- -u:合并相同行
- -f:忽略大小写
示例:
wc:文本统计

sed:行编辑器
说明sed的语法是:sed [options(参数)] 'Address(地址)Command(命令)' file(文件) ...
sed:行编辑器options
- -n: 静默模式,不再默认显示模式空间中的内容
- -i: 直接修改原文件
- -e SCRIPT -e SCRIPT:可以同时执行多个脚本
- -f /PATH/TO/SED_SCRIPT
- -r: 表示使用扩展正则表达式
sed:行编辑器Command
- -d: 删除符合条件的行;
- -p: 显示符合条件的行;
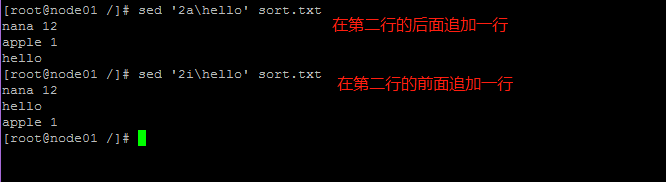
- -a \string: 在指定的行后面追加新行,内容为string
- \n:可以用于换行
- -i \string: 在指定的行前面添加新行,内容为string
- -r FILE: 将指定的文件的内容添加至符合条件的行处
- -w FILE: 将地址指定的范围内的行另存至指定的文件中;
- -s/pattern/string/修饰符: 查找并替换,默认只替换每行中第一次被模式匹配到的字符串
- -g: 行内全局替换
- -i: 忽略字符大小写
- -s///: s###, s@@@
- ( ), \1, \2
sed:行编辑器Address
- 可以没有
- 给定范围 如 : 第几行 1,2,3
- 查找指定行 如:/str/
简单示例:

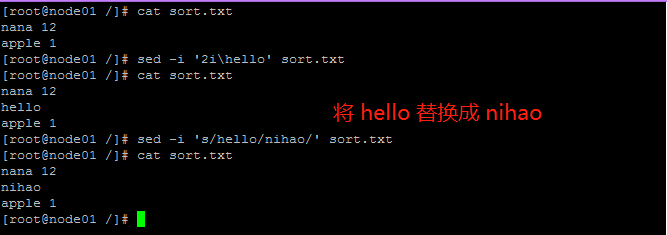

实用示例:修改inittab文件:
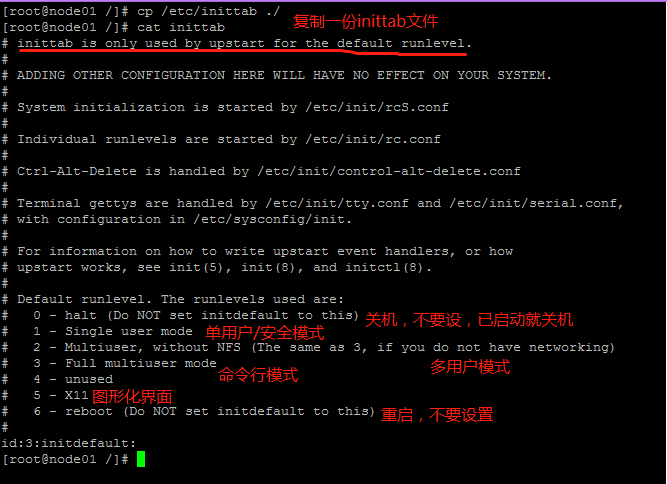
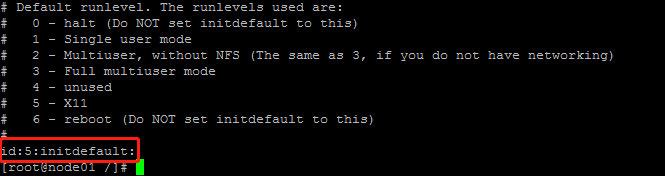
我们通过sed 's/\(id:\)[0-6]\(:initdefault:\)/\15\2/ig' inittab将3设置为5,结果如下:
实用示例:修改ip:
sed "s/\(IPADDR=\(\<2[0-5][0-5]\|\<2[0-4][0-9]\|\<1\?[0-9][0-9]\?\.\)\{3\}\).*/\188/" ifcfg-eth0将IP地址末尾改为188
awk 文本分析工具(重要)
- awk是一个强大的文本分析工具。
- 相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。
- 简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk语法: awk -F '{pattern(模式匹配) + action(动作)}' {filenames(文件名称)}
- 支持自定义分隔符
- 支持正则表达式匹配
- 支持自定义变量,数组 a[1] 、 a[tom] == map(key) 这里的数组可以相当于map
- 支持内置变量
- ARGC 命令行参数个数
- ARGV 命令行参数排列
- ENVIRON 支持队列中系统环境变量的使用
- FILENAME awk浏览的文件名
- FNR 浏览文件的记录数
- FS 设置输入域分隔符,等价于命令行 -F选项
- NF 浏览记录的域的个数
- NR 已读的记录数
- OFS 输出域分隔符
- ORS 输出记录分隔符
- RS 控制记录分隔符
- 支持函数
- print、split、substr、sub、gsub
- 支持流程控制语句,类C语言
- if、while、do/while、for、break、continue
示例,查找passwd文件:

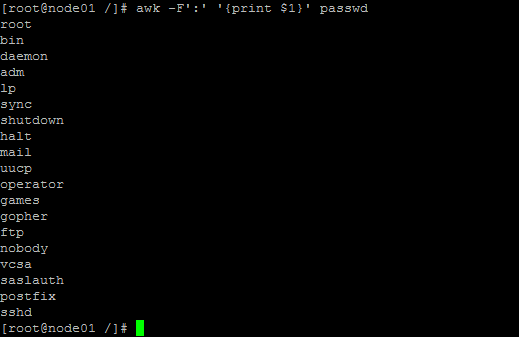
- 只是显示/etc/passwd的账户:CUT
awk -F':' '{print $1}' passwd
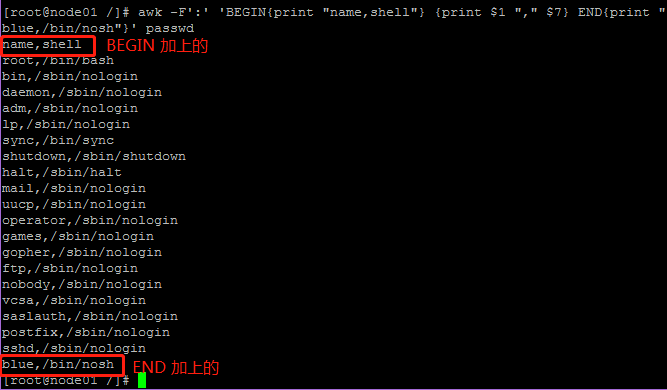
- 只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行开始前添加列名name,shell,在最后一行添加"blue,/bin/nosh"(cut,sed)
awk -F':' 'BEGIN{print "name,shell"} {print $1 "," $7} END{print "blue,/bin/nosh"}' passwd
- 搜索/etc/passwd有root关键字的所有行
awk '/root/ { print $0}' passwd

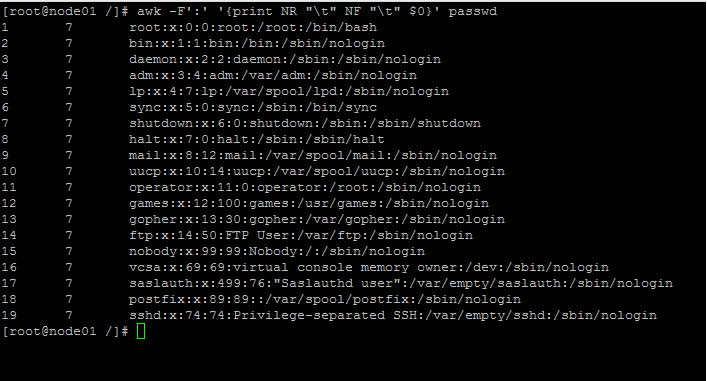
- 统计/etc/passwd文件中,每行的行号(NR),每行的列数(NF),对应的完整行内容
示例,统计报表:合计每人1月工资,0:manager,1:worker:
创建文件awk.txt

执行命令:awk '{split($3,date,"-");if(date[2]=="01"){name[$1]+=$5;if($2=="0"){role[$1]="M"}else{role[$1]="W"}}} END{for(i in name){print i "\t" name[i]"\t" role[i]}}' awk.txt
结果:

也可以将命令写入文件,然后读取文件执行命令:
