1、 vi
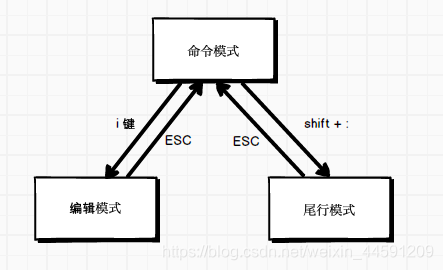
vi 有三种模式:
1) 命令行模式(command mode)
控制屏幕光标的移动,字符、字或行的删除。
2) 插入模式(Insert mode)
做文字输入。
3) 尾行模式(last line mode)
将文件保存或退出vi,也可以设置编辑环境,如寻找字符串、列出行号等。
命令行模式常见快捷键:
dd 删除当前行
dG 删除光标以下的所有行
ndd 删除光标以下的n行
gg 跳转到第一行的第一个字母
G 跳转到最后一行的第一个字母
shift+$ 跳转到行尾清空文件:
方法一: 先gg挑战到第一行第一个字母,再dG删除光标以下所有行。
方法二: echo "" > xxx.log (注!这命令清空完,文件还会有1个字节)
方法三(好!推荐!):cat /dev/null > xxx.log
大文件追加内容:
G shift+$ i 朝右箭头按一次+回车 到新的一行
搜索:
在尾行模式下 , /error ==> 搜索error关键词
设置/关闭行号
在尾行模式下,set nu / set nonu
【注: 生产上需要改配置文件,需先cp一份】
2、权限
drwxr-xr-x
第一个: d文件夹 -文件 l连接
r: 读权限 4
w: 写权限 2
x: 执行权限 shell脚本 1
-: 0
第一组:代表文件夹或文件所属的用户的权限
第二组:代表文件夹或文件所属的用户组的权限
第三组:代表其他组的所有用户对这个文件或文件夹的权限
[root@hadoop000 ~]# chmod 755 文件夹/文件 更改权限
[root@hadoop000 ~]# chmod -R 755 data 递归改权限
[root@hadoop000 ~]# chown jepson:jepson 目录/文件 更改文件所属用户、用户组
[root@hadoop000 ~]# chown -R jepson:jepson 目录/文件 递归更改文件所属用户、用户组3、查看文件/文件夹大小
方法一: ll -h (只能查文件的大小,文件夹的不准)
方法二: du -sh
4、软连接
相当于创建一个快捷方式
[root@hadoop000 ~]# ln -s 原始路径 目标路径5、上传下载(window)
[root@hadoop000 ~]# yum install lrzsz
[root@hadoop000 ~]# rz window ==>linux
[root@hadoop000 ~]# sz linux ==> window 6、top
![]()

load average :代表 一分钟,五分钟,十五分钟的机器负载情况。 一般不要超过 10
7、free -m

8、查看硬盘挂载状态
[root@hadoop000 ~]# df -h 9、压缩,解压
[root@hadoop000 ~]# zip -r 1.zip 1/* 压缩文件夹
[root@hadoop000 ~]# unzip 1.zip 解压缩
[root@hadoop000 ~]# tar -czvf 6.tar.gz 6/* 压缩
[root@hadoop000 ~]# tar -xzvf 6.tar.gz 解压10、定时任务
[root@hadoop000 ~]# crontab -e 编辑
[root@hadoop000 ~]# crontab -l 查看
[root@hadoop000 ~]# crontab -r 删除全部
* * * * * /root/test.sh >> /root/test.log
第1个: 分
第2个: 小时
第3个: 日
第4个: 月
第5个: 周
| 代表意义 | 分钟 | 小时 | 日期 | 月份 | 周 |
| 数字范围 | 0~59 | 0~23 | 1~31 | 1~12 | 0~7 |
| 特殊字符 | 代表意义 |
| * | 代表‘’每‘’。 * * * * * 代表每分钟执行一次 |
| , | 代表分隔时段的意思。 0 3,6 * * * 代表每天3:00和6:00执行一次 |
| - | 代表一段时间范围内。 20 8-12 * * * 代表8点到12点之间的每小时的20分都执行一次。 |
| /n | 那个n代表数字,即是每隔n单位间隔的意思,例如每五分钟进行一次,则: */5 * * * * |
若需要每10秒执行一次,则在脚本内部实现,for(1 to 6) sleep 10 。
11、后台执行命令
[root@hadoop000 ~]# nohup ./test.sh &
[root@hadoop000 ~]# nohup ./test.sh > /root/test.log 2>&1 &