在我们通常使用的windows系统中,我发现了一个有趣的现象。我新建一个空的文本文档,点击文件-另存为-编码选择UTF-8,然后保存。此时这个文件明明是空的,却占了3字节大小。原因在于:此时保存的编码方式自动会变为UTF-8 BOM
一、一个汉字在不同的编码方式中占多少字节?
1.在UTF-8中,一个汉字占3个字节(一个字符占一个字节)
2.在ASCII码中,一个汉字占2个字节(一个字符占一个字节)
3.在Unicode编码中,一个汉字占2个字节(一个字符同样占两个字节,所以JAVA中char a = '中';是可以的)
二、UTF-8与UTF-8 BOM
BOM即byte order mark,具体含义可百度百科或维基百科,UTF-8文件中放置BOM主要是微软的习惯,但是放在别的系统上会出现问题。不含BOM的UTF-8才是标准形式,UTF-8不需要BOM带BOM的UTF-8文件的开头会有U+FEFF,所以我新建的空文件会有3字节的大小。
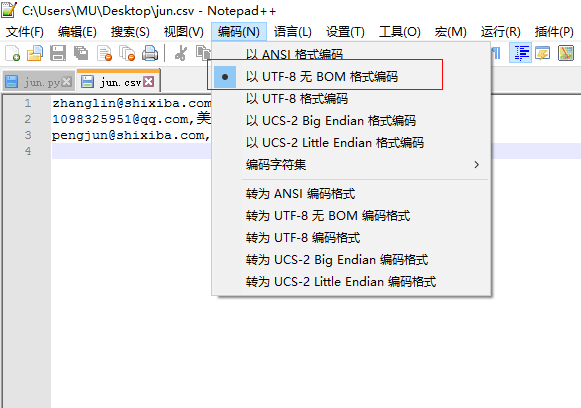
三、创建UTF-8(而非UTF-8 BOM)文件的方法
在发现文件另存为UTF-8缺得到UTF-8 BOM文件后,我们怎样才能得到UTF-8呢?
方法:.先另存为UTF-8保存,再使用notepad++打开,把里面的编码设置为无BOM的UTF-8然后保存。(此方法治标不治本,因为当你再次在里面写汉字时,文件会自动变成UTF-8 BOM)
文章参考: https://blog.csdn.net/LegendaryHsl/article/details/78794121