Optimizer
- tf.train.GradientDescentOptimizer
- tf.train.AdadeltaOptimizer
- tf.train. AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer
- tf.train.AdamOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
梯度下降优化器对比
- 标准梯度下降法:先计算所有样本汇总误差,然后根据总误差来更新权值
- 随机梯度下降法:随机抽取一个样本来计算误差,然后更新权值,可能会学习到比较多的噪声
- 批量梯度下降法:是一种折中方案,从总样本中选取一个批次(比如一个有10000个样本,随机选取100个样本作为一个batch),然后计算这个batch的总误差,根据这个总误差来更新权值






优化器动图比较
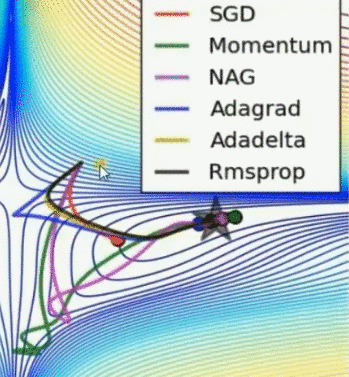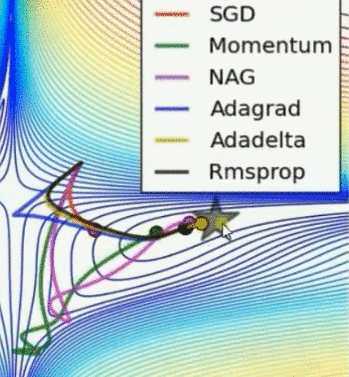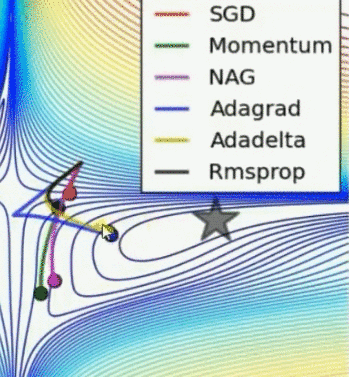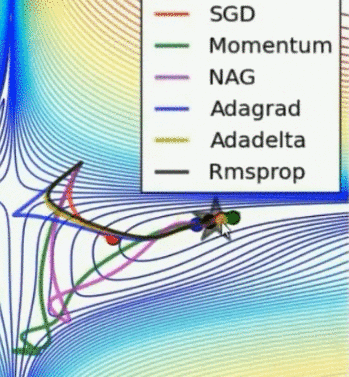
Momentum 和 NAG 速度快,但偏离方向乱跑;Adadelta 最快,其次是 Adagrad 和 Rmsprop
鞍点问题

其他的优化器都能逃离鞍点,但随即梯度不能,Adadelta 最快,NAG 速度快,但意识错误的反应慢,Rmsprop 比 Adagrad 稍快
每种优化器都有它的适用范围,很多新的算法都比梯度下降快,但哪个优化器准确率高就说不准了
使用如下
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 载入数据集
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)
batch_size = 100
# 计算一个有多少批次,整除
n_batch = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# 设置有百分之多少的神经元工作
keep_prob = tf.placeholder(tf.float32)
# 创建一个简单的神经网络
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x,W)+b)
# 二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction))
# 交叉熵代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
# 梯度下降法
# train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
train_step = tf.train.AdamOptimizer(1e-2).minimize(loss)
init = tf.global_variables_initializer()
# 结果存放在布尔型列表中
# tf.equal 相等返回 True,否则 False,argmax 比较 y 中哪个元素的值为 1,返回该元素下标
correct_predition = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
# 求准确率
# tf.cast 将布尔型转换为32位浮点型,True -> 1.0,False -> 0.0,然后求平均值,如有 9 个 1,1 个 0,平均值为 0.9,准确率为 0.9
accuracy = tf.reduce_mean(tf.cast(correct_predition, tf.float32))
with tf.Session() as sess:
sess.run(init)
# 循环 21 个周期,每个周期批次为 100,每个周期将所有图片都训练一次
for epoch in range(20):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x:batch_xs, y:batch_ys, keep_prob: 0.7})
#训练完一个周期看下准确率
test_acc = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels, keep_prob: 1.0})
train_acc = sess.run(accuracy, feed_dict={x:mnist.train.images,y:mnist.train.labels, keep_prob: 1.0})
print('Iter ' + str(epoch) + ', Testing Accuracy' + str(test_acc) + ', Testing Accuracy'+ str(train_acc))