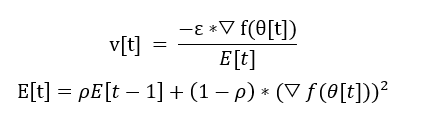所谓的优化器,就是tensorflow中梯度下降的策略,用于更新神经网络中数以百万的参数。工程师们除了在不断的推出新的神经网络的结构以外,还在不断的推出新的参数更新的策略,在这篇博客中,我们就列举tensorflow中所有的优化器,并对几个进行讲解。
为了列举所有的优化器,我们首先把tf包中所有的优化器都罗列出来。这里使用的是tf10版本,目前最新的版本,进入python,用dir(tf.train)列举出所有的和优化器相关的指令。

通过上面的图我们可以看到,一共有11个优化器,以及1个tf.train.Optimizer的基类。这11个优化器分别是:
- Tf.train.AdadeltaOptimizer
- Tf.train.AdagradDAOptimizer
- Tf.train.AdagradOptimizer
- Tf.train.AdamOptimizer
- Tf.train.FtrlOptimizer
- Tf.train.GradientDescentOptimizer
- Tf.train.MomentumOptimizer
- Tf.train.ProximalAdagradOptimizer
- Tf.train.ProximalGradientDescentOptimizer
- Tf.train.RMSPropOptimizer
- Tf.train.SyncReplicasOptimizer
下面我们就按照从博主看来从简单到困难的顺序为大家介绍一部分的优化器,因为有一些作者也不是特别了解。根据个人的经验,一般来说我们尝试几个常见的优化器SGD或者Adam等就可以了,个人感觉在实际的应用中,优化器对结果的影响不是特别大(可能和做的具体的数据有关,个人见解不喜勿喷),只要用一种优化器能保证收敛就可以了。
下面就介绍几个优化器,同时也列出一些链接方便大家对不同的优化器有更多的认识:
https://www.jianshu.com/p/aebcaf8af76e http://www.cnblogs.com/guoyaohua/p/8542554.html
1 Tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,
name='GradientDescent)
这是最基础的梯度下降算法,也就是大家一般在教科书中接触到的最朴素的方法,他的参数实际上只有一个,那就是learning_rate学习率,这里我们简写做ε(伊普西龙)。还有一个默认是False的参数use_locking,在官方文档的解释是,如果这个参数是True则对更新操作使用锁,这里我的理解就是如果是True的话,就不进行梯度下降的更新了,这个我们没有必要管它,在之后的优化器中我们不再介绍这个参数。
GradientDescentOptimizer的计算方法很简单,就是用学习率乘每个参数所对应的梯度▽θ更新网络参数。这里倒三角代表梯度,θ代表参数,f代表损失函数,v代表计算得到的参数的更新大小,▽f(θ)代表经过损失函数的梯度,中括号代表了计算[t]代表一次计算时网络的情况,而[t+1]代表新后网络中可学习的参数。
v[t] = -ε*▽f(θ[t])
Θ[t+1] = θ[t] +v[t]
2 Tf.train.MomentumOptimizer (self, learning_rate, momentum,
use_locking=False, name=‘Momentum’, use_nesterov=False)
learning_rate 是学习率,momentum是动量值的系数η。这个函数是带动量的梯度下降,与之前的区别就是在一次梯度下降的计算时,同时考虑到上一次梯度下降的大小和方向,就好像梯度下降是有惯性一样。Use_nesterov这个参数指的是,是否使用nesterov版本的带动量的梯度下降,(nesterov版本梯度下降见http://proceedings.mlr.press/v28/sutskever13.pdf)

从上面的图我们可以看出,单纯的带动量的梯度下降方法中我们在朴素的梯度下降的版本上加入了上一次训练中梯度下降的大小,用于更新参数。而在nesterov版本中,在原版的带动量的梯度下降的基础上我们还在及算梯度的时候加入了上一次的更新量。从我的角度看在参数更新的时候加入了更多的非线性的量来加速和稳定收敛。
3 Tf.train.AdagradOptimizer(self, learning_rate,
initial_accumulator_value=0.1, use_locking=False, name=‘Adagrad’)
AdagradOptimizer实际上属于自适应的梯度下降算法。其主要的思想是,如果一个可学习的参数已经梯度下降了很多,则减缓其下降的速度,反之如果一个参数和初始化相比没有下降很多,保证它有一个比较大的下降速度。和之前的对所有参数“一视同仁”的方法相比,该方法更加的“因材施教”。
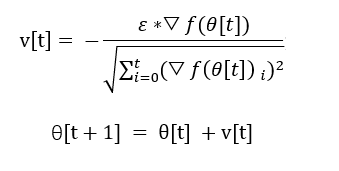
而这个因材施教,就是通过上图中v[t]中的分母实现的,分母是从开始训练到现在,参数梯度大小的根号下平方和,随着训练的进行,分母越来越大,因此参数的该变量越来越小。同时看过公式我们也知道了initial_accumulator_value代表了第一次训练时,分母梯度大小的初始值。
4 Tf.train.AdadeltaOptimizer(self, learning_rate=0.001, rho=0.95,
epsilon=1e-08, use_locking=False, name=‘Adadelta’)
AdaDelta,是google提出的一种对于AdaOptimizer的改进,同样是一种自适应的优化器,在看上面ada优化器的时候我们会发现,当训练时间越来越长的时候,分母会越来越大因此导致所有的该变量都趋向于变为0,这样就会导致训练停止,可能导致没有充分的训练。为了解决这个问题,google提出了adadelta算法,加入了一个ρ参数,使得分母不仅仅在不断地积累,同时也乘参数使其不断的减小。而且同时积累梯度和每次更新的数值,具体的论文见http://arxiv.org/pdf/1212.5701v1.pdf 算法的流程图如下。

5 Tf.train.AdagradDAOptimizer(self, learning_rate, global_step,
initial_gradient_squared_accumulator_value=0.1,
l1_regularization_strength=0.0, l2_regularization_strength=0.0,
use_locking=False, name=‘AdagradDA’)
Tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999,
epsilon=1e-08)
全称是Adagrad双重平均算法(Dual Averaging algorithm),这个算法我实在是看不懂了,光是数学原理就要好多页,这里贴出论文的链接http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf
,感兴趣的各位可以看一看,如果哪位大牛能看懂写一个简单易懂的易懂的解释,我愿意在这里附上大牛的链接
6 Tf.train.ProximalGradientDescentOptimizer(self, learning_rate,
l1_regularization_strength=0.0, l2_regularization_strength=0.0,
use_locking=False, name=‘ProximalGradientDescent’)
接近梯度下降方法,这个是tf取的名字,其实在文章中,作者简称该梯度下降算法为folos,之所以叫接近的梯度下降算法,是因为作者在原梯度下降算法的基础上加入了修正,进而解决了一些不可微的问题,http://papers.nips.cc/paper/3793-efficient-learning-using-forward-backward-splitting.pdf