基于 API 的爬虫
基于API的爬虫基本步骤如下:
- 注册某网站的API开发者权限,获得开发者密钥
- 在网址提供的API中找到自己需要的API,并确定开发者每天爬取数量,调用API参数
- 在联网情况下调用API,看是否能正常返回,再进行编码调用
- 从API返回的内容(常见为JSON格式)中获取所需属性
- 将获取的内容存储到本地(文件或数据库)
我是通过豆瓣提供的API进行练习 (豆瓣API)
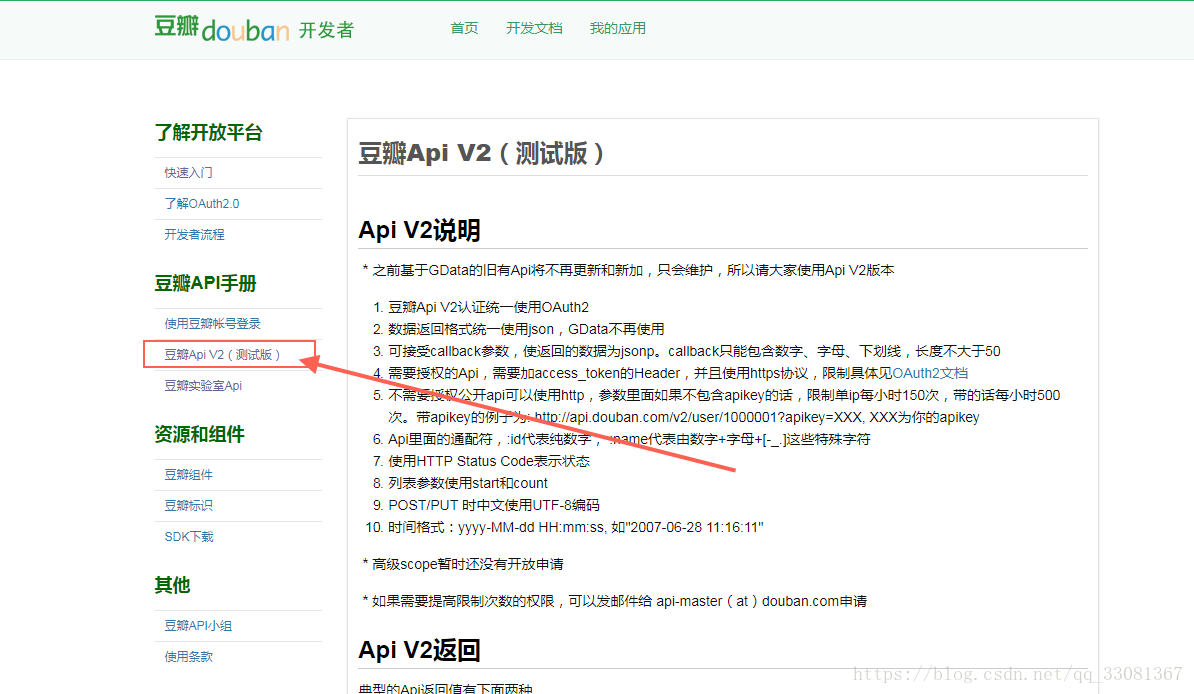

我模拟的场景是根据电影名称爬取该电影的评分:
- 启动你之前配置好的编程环境 : activate course_py35
- 安装编写Python的Jupyter Notebook工具 : conda install jupyter
- 启动工具 : jupyter notebook
浏览器会自动打开弹出 Jupyter Notebook 工具

打开后 New 一个 Python3

开始编写Python 代码 通过豆瓣提供的 API 还有 ID 获取到电影评分
# 常用的工具包
import urllib.request as urlrequest
import json
# 要访问的API URL (27605698 为电影 ID)
url = "https://api.douban.com/v2/movie/subject/27605698";
# 访问 URL 并获取返回的结果转换成 JSON
content = urlrequest.urlopen(url).read();
#这里会出现编码问题,如果先看JSON中的中文内容替换 content.decode('unicode-escape')
json_content = json.loads(content.decode('utf8'));
# 打印API返回的结果
print(json_content )
# 打印API返回的结果中电影评分
print(json_content['rating']['average'])通过豆瓣提供的 API 中提供的方法 根据电影名称获取他的评分

import urllib
import urllib.request as urlrequest
import json
# 搜索名称集合 List
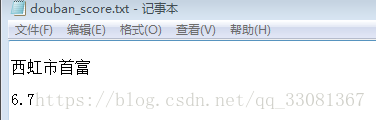
name_list = ["西红柿首富","巨齿鲨","小偷家族","风语咒"]
# 写入文件的名称及格式 “a” 表示递增 “w”表示覆盖
with open("douban_score.txt" , "w" ) as outputfile:
# 循环集合
for name in name_list:
# 这里需要将中文名转换为网页链接中能够读取的编码
id = urllib.parse.quote(name);
url = "https://api.douban.com/v2/movie/search?q={}".format(id);
content = urlrequest.urlopen(url).read();
json_content = json.loads(content.decode('utf8'));
# 找到评分所在位置 因为通过名称返回的JSON是集合所以要通过下标来读取[0]
rank = json_content['subjects'][0]['rating']['average'];
# 写入到douban_score.txt的内容 \n回车整理格式
outputfile.write("{} {}\n".format(name,rank))成功获取到电影评分
拓展补充
- JSON 教程
- Python JSON
- Python3 JSON 数据解析
- 字符集和字符编码(Charset & Encoding)
- 字符串和编码
- 白话产品对接,一篇文章看懂API和SDK
- 免费实用的API接口
- 高德API+Python解决租房问题
- Python爬虫小白入门(一)写在前面
希望有富余时间的同学可以看看这些不错文章,并自己尝试下。
基于 HTML 的爬虫
基于 html 编写爬虫 你需要一定的 html 基础 (最起码要认识常用的 html 标签)
- HTML 4.01 快速参考
- HTTP 教程
- 爬虫开发技术基础教程之HTTP基础
- 爬虫入门系列(一):快速理解HTTP协议
- 爬虫入门系列(二):优雅的HTTP库requests
- 爬虫入门系列(三):用 requests 构建知乎 API
- 爬虫入门系列(四):HTML文本解析库BeautifulSoup
- 爬虫入门系列(五):正则表达式完全指南(上)
不同于API爬取得到的是JSON 格式的数据,需要用到JSON库来处理,基于网页的爬虫返回的HTML页面需要用BeautifulSoup库来解析。有的网站不支持API,或者API中数据较少而且还限制每天的爬取次数,所以这个时候就需要使用另一种爬取数据的方式,来进行数据爬取。
- 启动你之前配置好的编程环境 : activate course_py35
- 安装 BeatifulSoup : pip install beautifulsoup4
- 启动工具 : jupyter notebook
Jupyter 中实现网页的获取
# 运行以下代码看BeautifulSoup 是否正常安装(若未提示错误则表示正常)
from bs4 import BeautifulSoup
url = "https://movie.douban.com";
craw_content = urlrequest.urlopen(url).read();
# 使用BeautifulSoup解析HTML文档
soup = BeautifulSoup(craw_content ,‘html.parser’)
# BeautifulSoup 中 “soup.prettify” 这个方法可以让网页更加友好地打印出来
print(soup.prettify())
# 返回title部分的全部内容 <title>西红柿首富</title>
soup.title
# 返回title标签的名称'title'
soup.title.name
# 返回这个标签的内容 “西红柿首富”
soup.title.string
# 返回所有超链接的元素如下
soup.find_all(‘a’)
# 返回 id=screening 部分的内容 .get_text() 只显示文本
soup.find(id="screening").get_text()
我们来获取豆瓣电影中推荐列表电影的评分,这里我用的 Chrome 浏览器,其中按 f12 会进入开发者模式,模式下可以看到你底层的 html 代码而且还有一个很方便的选取功能。

import urllib.request as urlrequest;
url = "https://movie.douban.com";
craw_content = urlrequest.urlopen(url).read();
from bs4 import BeautifulSoup
soup = BeautifulSoup(craw_content,'html.parser');
# 查找页面标签 id = screening 内,并且 class 属性中包含 ui-slide-content
soup_forecast = soup.find(id = 'screening').find(class_= 'ui-slide-content')
# 根据class属性获取到title标题集合
title_list = soup_forecast.find_all(class_='title')
# 根据class属性获取到rating标题集合
rating_list = soup_forecast.find_all(class_='rating')
with open('douban_score.txt','w') as outputfile :
# range(10) 循环10次
for i in range(10):
# 获取文本内容并写入
title = title_list[i].get_text();
rating = rating_list[i].get_text();
outputfile.write('{}{} \n '.format(title,rating))拓展链接
正则表达式
正则表达式的原理是依次拿出表达式和文本中的字符进行比较,并有其匹配的规则,例如最简单的有:
.可以匹配任意字符\d用于匹配任意的数字
那么.\d就可以用于匹配a1
这里使用到的是re库,常用于解析HTML的函数有re.match,re.search等等。示例:
import re
url = "http://www.baidu.com"
w = "www."
m = re.search(w,url)
if m:
print(m.group())
if m == False:
print('cannot match')
#返回:www.
爬虫返回的html页面也是字符串类型,使用re库函数,可以用正则表达式来匹配。
链接材料
- 请阅读正则表达式,学习匹配方法、re模块、切分字符串、分组、贪婪匹配这五块内容。
- 请阅读Python正则表达式指南中图片的部分,了解更多关于Python正则表达式的用法
- 请阅读[Python]爬虫,正则表达式解析网页及Json序列化链接中re模块的函数match,research,findall的使用
也许你并不能在短时间内记忆正则表达式的大部分使用方法,这也不是这门课程的必学内容,但请你掌握正则表达式的大致思想,在今后遇见特定的场合,可以马上回想起正则表达式是如何支持你预想的操作。
学习完正则表达式之后,是否觉得BeautifulSoup 包十分方便可爱呢,的确在解析HTML网页方面,使用BeautifulSoup库进行解析是十分方便的,正则表达式主要自己编写,但在处理纯文本数据的时候,正则表达式就十分灵活。