上一篇博客(入门知识篇),对爬虫有了一个基本的了解,但是具体怎么实现一个爬虫程序呢?
一般情况下,我们在浏览器获取信息,是向服务器发送一个http请求,要么返回html页面,要么是ajax请求返回一串json数据,以更新当前网页中局部信息。这里用两个例子分别学习下爬虫的基本操作。
以下代码是基于python3.6环境。
一、百度在线翻译的自动联想功能
百度在线翻译有这样一个功能,如下图,输入一个字母w,下面黄框里实时就会联想出来几个w开头的单词并有相应的翻译,分析可见,是网页自动发送了一个post请求"https://fanyi.baidu.com/sug",并且只有一个参数。那么我们怎么利用这个API实现我们自己的联想功能呢?
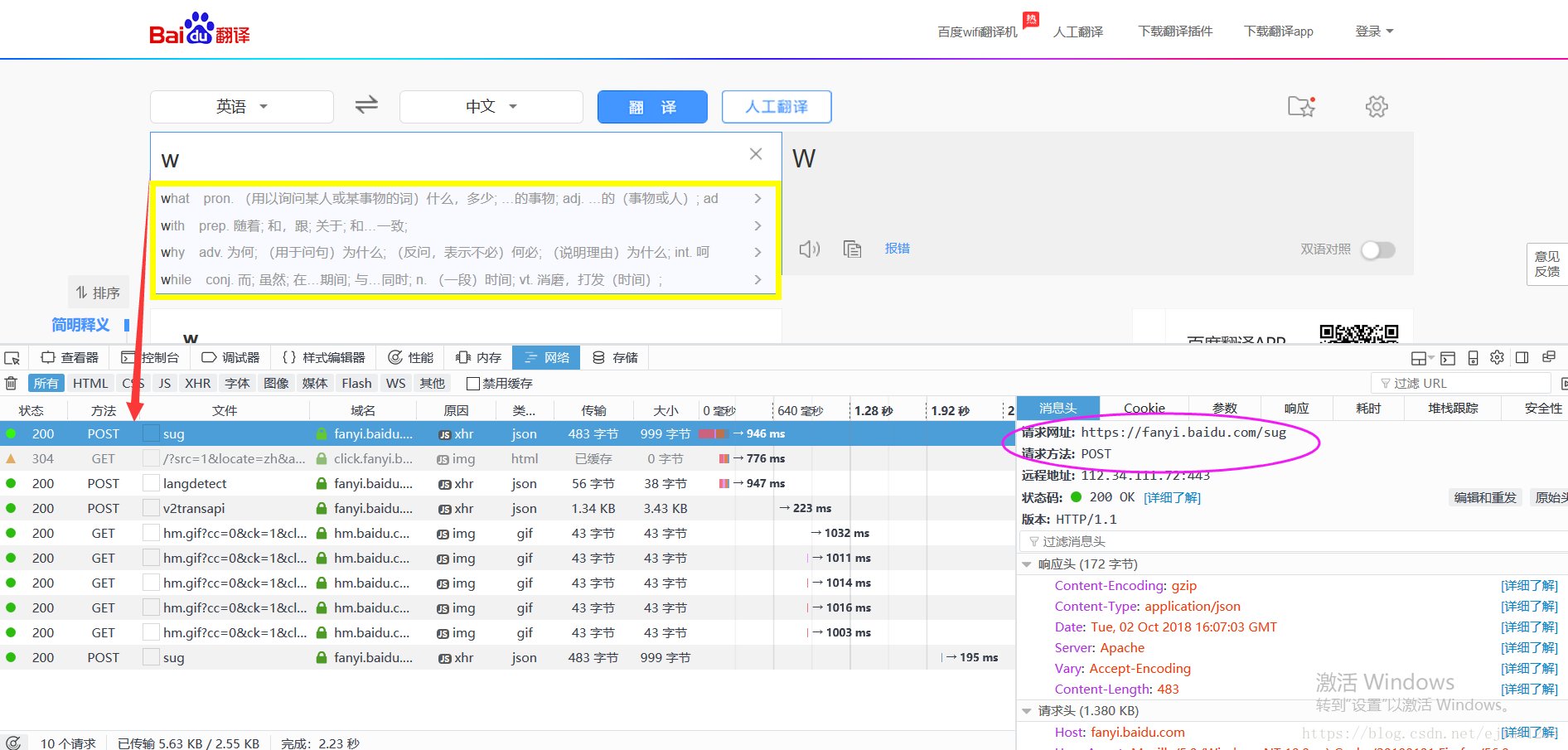
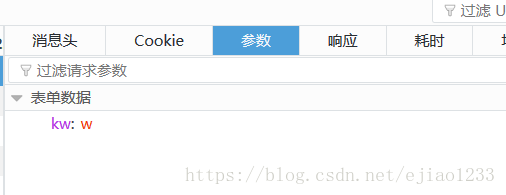
参数列表:
再看下其返回结果:
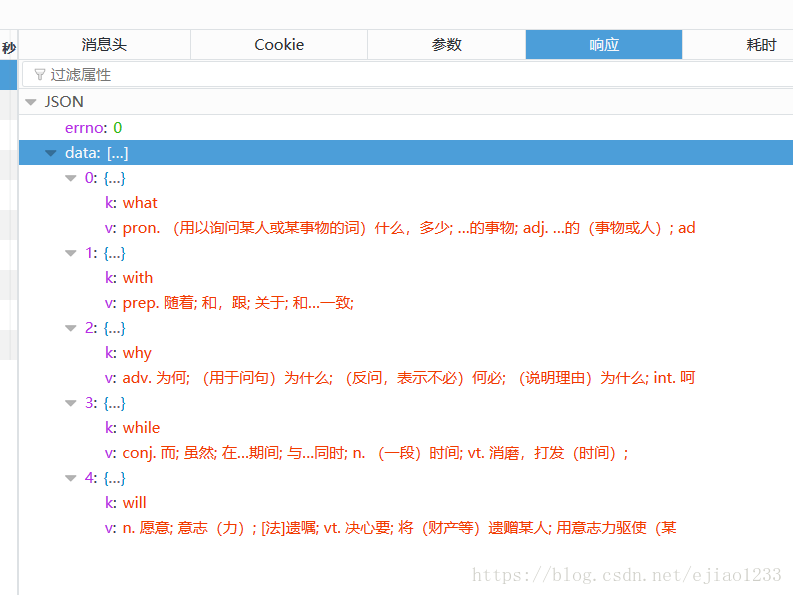
我们模拟浏览器发送这个请求,将获得这样的json字符串,解析之后,就可以拿到联想到的单词和相应的翻译了:
# 使用requests
import requests
import json
def fanyi(keyword):
url = 'https://fanyi.baidu.com/sug'
# 定义请求参数
data = {
'kw' : keyword
}
# 通过设置header头,伪装浏览器用户
headers = {"User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
# 发送post请求,抓取信息
res = requests.post(url,data=data,headers=headers)
# 解析结果并输出
# 获取响应的json字串
str_json = res.text
# 把json转字典
myjson = json.loads(str_json)
# 先判断data里面是否有内容
if len(myjson['data'])==0:
print("结果:没有这个词")
print()
else:
# 遍历结果,输出单词和相应的翻译
for v in myjson['data']:
print("--联想到的单词:"+v['k'])
print("--翻译:"+v['v'])
print()
if __name__ == '__main__':
while True:
keyword = input('输入翻译的单词:')
if keyword == 'q':
print("-- 结束 --")
break
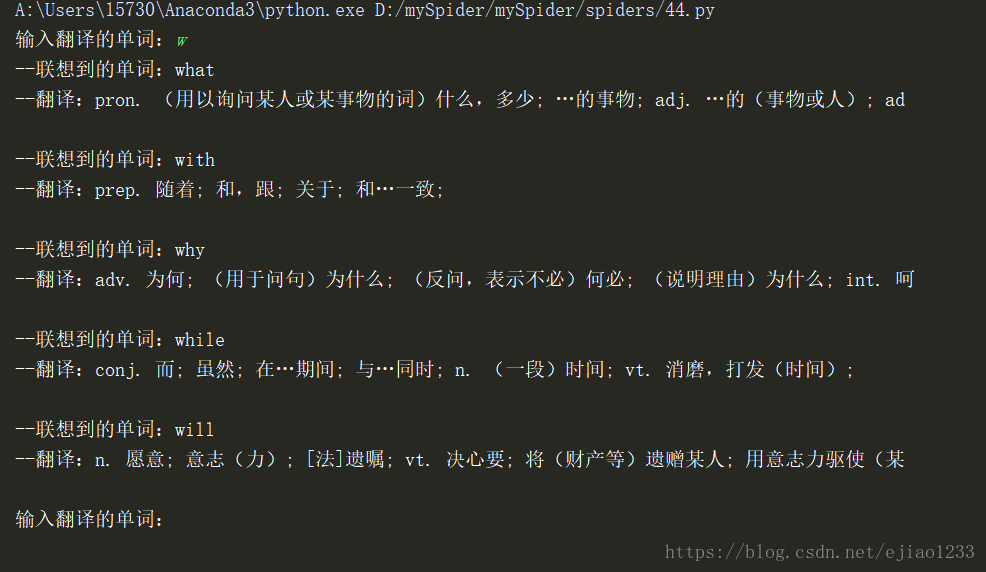
fanyi(keyword)输出结果如下:
二、使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入txt文件和数据库中(源码有详细的注释)
和上一个例子不同的是,这次返回的结果是html代码,我们需要通过正则表达式匹配解析出需要的内容;
这里有两点值得注意的:
1、使用requests方式请求得到的html源码,有可能和直接在浏览器选取其中一个元素看到的代码不一致,也有可能和右键查看页面源代码不一致,对解析会造成一定的干扰。 这是因为浏览器可能是通过Ajax局部更新的数据,解析之前要注意区分。
2、python中yield的使用(对python使用不是很熟悉的情况下,这个应用还是很新鲜、很特别的):
一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,但不会执行任何函数代码,直到对其调用 next()(在 for 循环中会自动调用 next())才开始执行。虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,并返回一个迭代值,下次执行时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。
yield 的好处是显而易见的,把一个函数改写为一个 generator 就获得了迭代能力,比起用类的实例保存状态来计算下一个 next() 的值,不仅代码简洁,而且执行流程异常清晰。
以下是第二个例子的源码:
# URL地址:http://maoyan.com/board/4 其中参数offset表示分页的每页起始条数-1
# 获取信息:{排名,图片,标题,主演,放映时间,评分}
from requests.exceptions import RequestException
import requests
import re,time,json
import pymysql
def getPage(url):
'''爬取指定url页面信息'''
try:
#定义请求头信息(模拟浏览器)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'
}
# 执行爬取
res = requests.get(url,headers=headers)
#判断响应状态,并响应爬取内容
if res.status_code == 200:
return res.text
else:
return None
except RequestException:
return None
def parsePage(html):
'''解析爬取网页中的内容,并返回字段结果
这里有个问题,使用requests获取的网页html和在浏览器中从页面中选择一个元素对应的html代码可能不一致
'''
#定义解析正则表达式(关于正则表达式的写法用法,后面有机会再探讨)
pat = '<i class="board-index board-index-[0-9]+">([0-9]+)</i>.*?' \
'<img data-src="(.*?)" alt="(.*?)" class="board-img" />.*?' \
'<p class="star">(.*?)</p>.*?' \
'<p class="releasetime">(.*?)</p>.*?' \
'<i class="integer">([0-9\.]+)</i>' \
'<i class="fraction">([0-9]+)</i>'
# print(html)
#执行解析
items = re.findall(pat,html,re.S)
#遍历封装数据并返回
for item in items:
print("item : ",item)
yield {
'index':item[0],
'image':item[1],
'title':item[2],
'actor':item[3].strip()[3:],
'time':item[4].strip()[5:],
'score':item[5]+item[6],
}
def writeDB(content):
"""
写入数据库
:param content:
:return:
"""
print(content)
print(content["index"])
db = pymysql.connect("127.0.0.1", "root", "root", "myspider_001")
cursor = db.cursor()
sql = "insert into tb_results (index0,image,title,actor,time,score) \
values ('%s','%s','%s','%s','%s','%s')"% \
(content['index'],content['image'],content['title'],content['actor'],content['time'],content['score'])
print(sql)
try:
cursor.execute(sql)
print("qq")
db.commit()
except:
print("q")
db.rollback()
def writeFile(content):
'''执行文件追加写操作'''
#print(content)
with open("./result.txt",'a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + "\n")
#json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
def main(offset):
''' 主程序函数,负责调度执行爬虫处理 '''
url = 'http://maoyan.com/board/4?offset=' + str(offset)
#print(url)
html = getPage(url)
#判断是否爬取到数据,并调用解析函数
if html:
for item in parsePage(html):
writeFile(item)
writeDB(item)
# 判断当前执行是否为主程序运行,并遍历调用主函数爬取数据
if __name__ == '__main__':
# 前100名,每页10名,分页参数offset 0 10 20 ...90
for i in range(10):
main(offset=i*10)
time.sleep(1)学完这两个基本的例子,就对爬虫有了一个初步的认识。
后面还会继续学习,写下来,一方面是个总结和记录,一方面希望有可能帮到和我一样的初学者。