版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/89676130
1 创建分组
- 原数据表
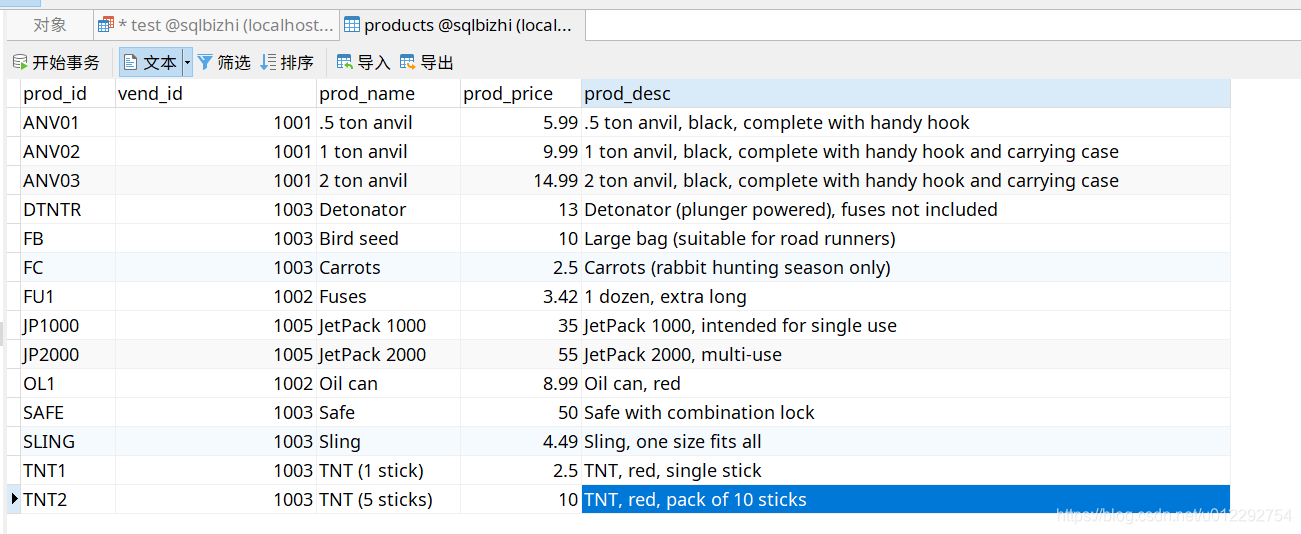
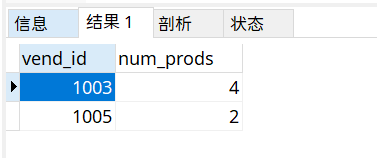
SELECT vend_id,count(*) as num_prods
from products
GROUP BY vend_id;
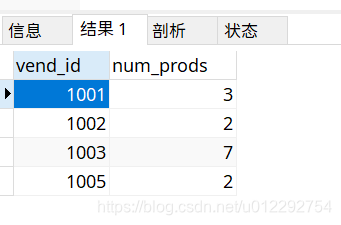
2 group by
group by子句可以包含任意数目的列。使得能对分组进行嵌套,为数据分组提供更加细致的控制;- 如果在
group by子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算,所以不能从个别的列取回数据; group by子句中列出的每个列都必须是检索列或者有效的表达式(不能是聚集函数)。如果 select 中使用表达式,则必须在group by子句中指定相同的表达式,不能使用别名;- 除聚集计算语句外,select 语句中的每个列都必须在
group by子句中给出; - 如果分组列中具有 NULL 值,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值,它们将分为一组;
GROUP BY子句必须出现在where子句之后,order by子句之前;
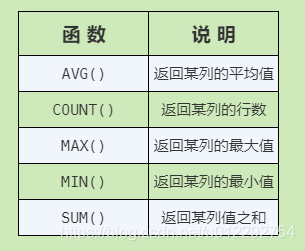
2.1 聚集函数
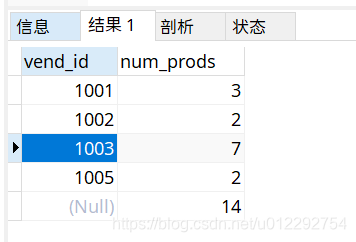
2.2 with rollup
- 可以的得到每个分组以及每个分组汇总级别(针对每个分组)的值
SELECT vend_id,count(*) as num_prods
from products
GROUP BY vend_id WITH ROLLUP;
3 过滤分组 having
where过滤指定的是行而不是分组,它没有分组的概念;- 所有类型的
where都可以用having来替代,区别就是having过滤分组; having支持所有where操作符;
- 原数据表
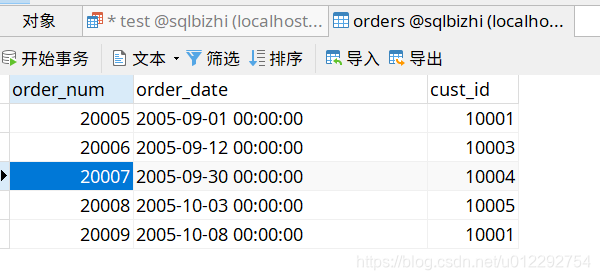
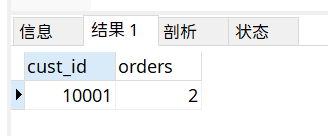
SELECT cust_id,COUNT(*) as orders
from orders
GROUP BY cust_id
HAVING COUNT(*)>=2;
3.1 having 和 where 的区别
where在数据分组前进行过滤;having在数据分组后进行过滤;where排除的行不包括在分组中,这可能会改变计算值,从而影响having子句中基于这些值过滤掉的分组;
- 原数据表
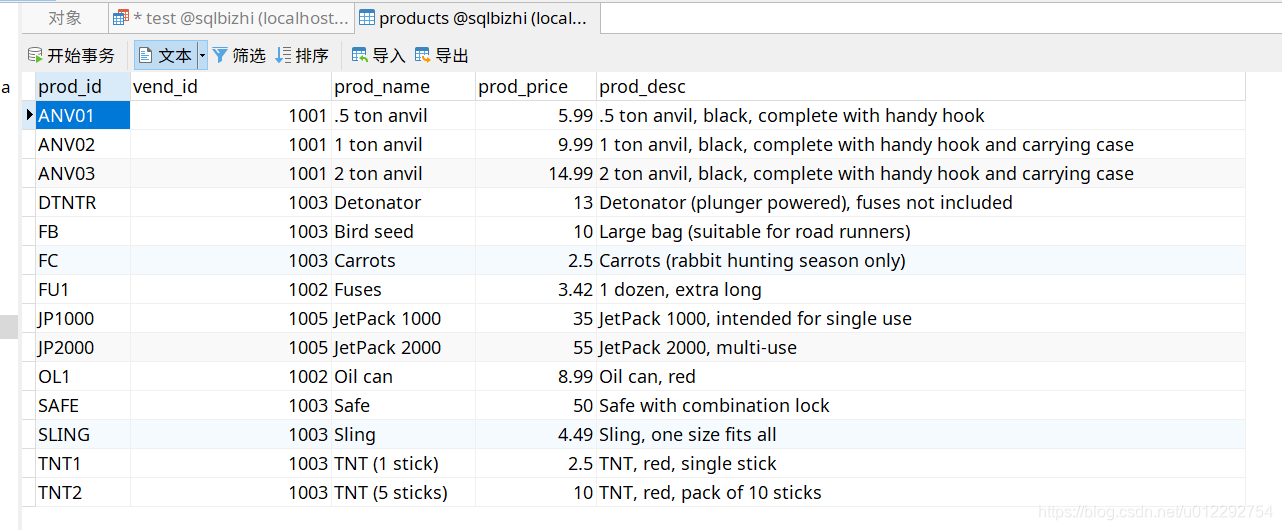
SELECT vend_id,COUNT(*) as num_prods
from products
WHERE prod_price >=10
GROUP BY vend_id;
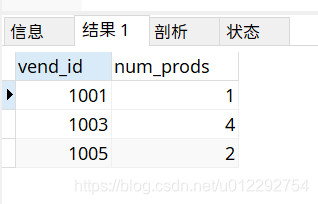
SELECT vend_id,COUNT(*) as num_prods
from products
WHERE prod_price >=10
GROUP BY vend_id
HAVING count(*)>=2;
4 分组和排序
4.1 order by 和 group by 区别
| order by | group by |
|---|---|
| 排序产生的输出 | 分组行,但是输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
4.2 不要忘记 order by
- 一般在使用
group by子句时,应该也给出order by子句,这是保证数据正确排序的唯一的方法,不要依赖group by排序数据;
- 原数据表
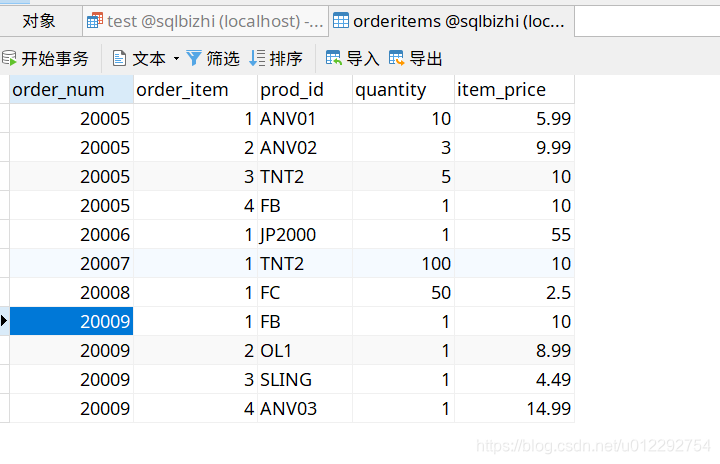
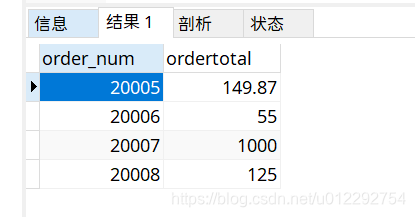
#检索总计订单价格大于等于50的订单的订单号和总计订单价格
SELECT order_num,SUM(quantity*item_price) as ordertotal
from orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price)>=50;
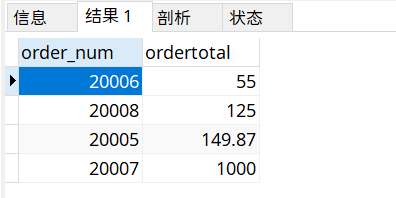
SELECT order_num,SUM(quantity*item_price) as ordertotal
from orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price)>=50
order by ordertotal;
5 select 子句及其顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| select | 要返回的列或者表达式 | 是 |
| from | 从中检索的数据表 | 仅在从表选择数据时使用 |
| where | 行级过滤 | 否 |
| group by | 分组说明 | 仅在按组计算聚集时使用 |
| having | 组级过滤 | 否 |
| order by | 输出排序顺序 | 否 |
| limit | 要检索的行数 | 否 |