可以看下我转载的一片文章机器学习入门概括
关于TensorFlow的安装 Ubuntu18.04下安装anaconda和pycharm搭建TensorFlow
持续更新,在和同学交流之后被推荐了北京大学曹健老师的这门实践课,学习TensorFlow的实践。先致谢一下曹健老师!课程资源在B站和网易中国MOOC都可以找到。大三课务紧张,只能抽时间补笔记,可能更新缓慢。
目录
3.1基本概念 张量(Tensor)、计算图(Graph)、会话(Session)
3.2前向传播(搭建神经网络模型,让神经网络NN实现推理过程)
第一讲:概述
图灵在1950年写过一篇论文《计算机器与智能》,图灵让我们思考:“机器能否拥有智能?(Can machines think?)”这个问题。图灵成功定义了什么是计算机器(即图灵机),但却不能定义什么是智能(Think),没有办法用机器或算法来准确定义。因此图灵设计了一个模拟测试——图灵测试(一种用于判定机器是否具有智能的试验方法)。图灵测试的核心想法是要求计算机在没有直接物理接触的情况下接受人类的询问,并尽可能把自己伪装成人类。
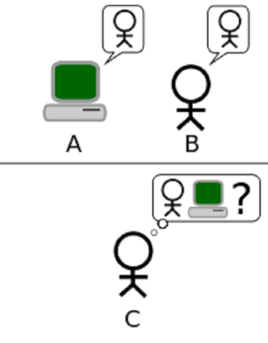
试验过程:提问者和回答者隔开,提问者通过一些装置(如键盘)向机器随意提问。多次测试,如果有超过30%的提问者认为回答问题的是人而不是机器,那么这台机器就通过测试,具有了人工智能。
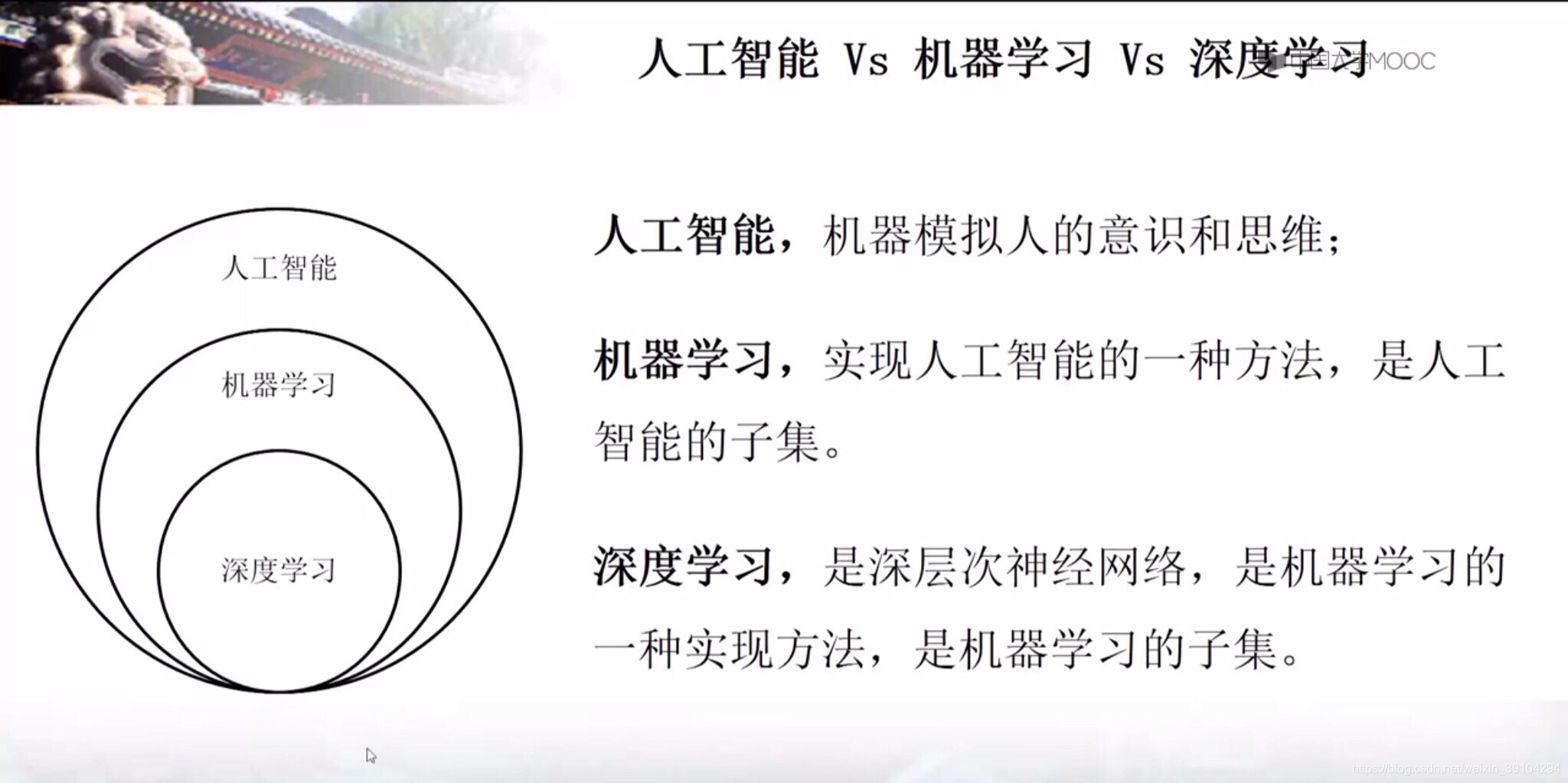
人工智能:机器模拟人的意识和思维。
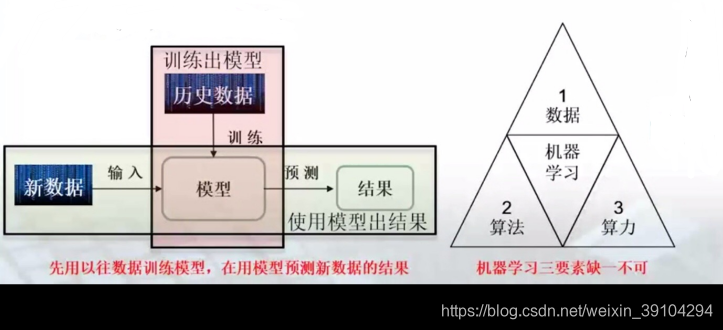
机器学习:机器学习是一种统计学方法,计算机利用已有的数据,得出某种模型,再利用这个模型来预测结果。在历史数据的基础上,不断训练,随经验增加,预测的效果会更好。(以预测班车到达时间为例)
add.这里我补充一下“花书”中对于机器学习的描述:Ai系统需要具备自己获取知识的能力,即从原始数据中提取模式的能力,这种能力被称为机器学习。
深度学习(深度神经网络):模仿人类的神经网络,在计算机中建立计算机的神经网络。
add.“花书”中对于深度学习的描述:让计算机从经验中学习,并根据层次化的概念体系来理解世界,而每个概念则通过与某些相对简单的概念自己啦的关系来定义。让计算机从经验中获取知识,可以避免由人类来给计算机形式化地指定它所需要的所有知识。层次化的概念让计算机构建相对较简单的概念来学习复杂的概念。如果绘制出这些概念如何建立在彼此之上的图,我们将得到一张“深(deep)层次很多的”图。基于这些原因,我们称这种方法为深度学习。
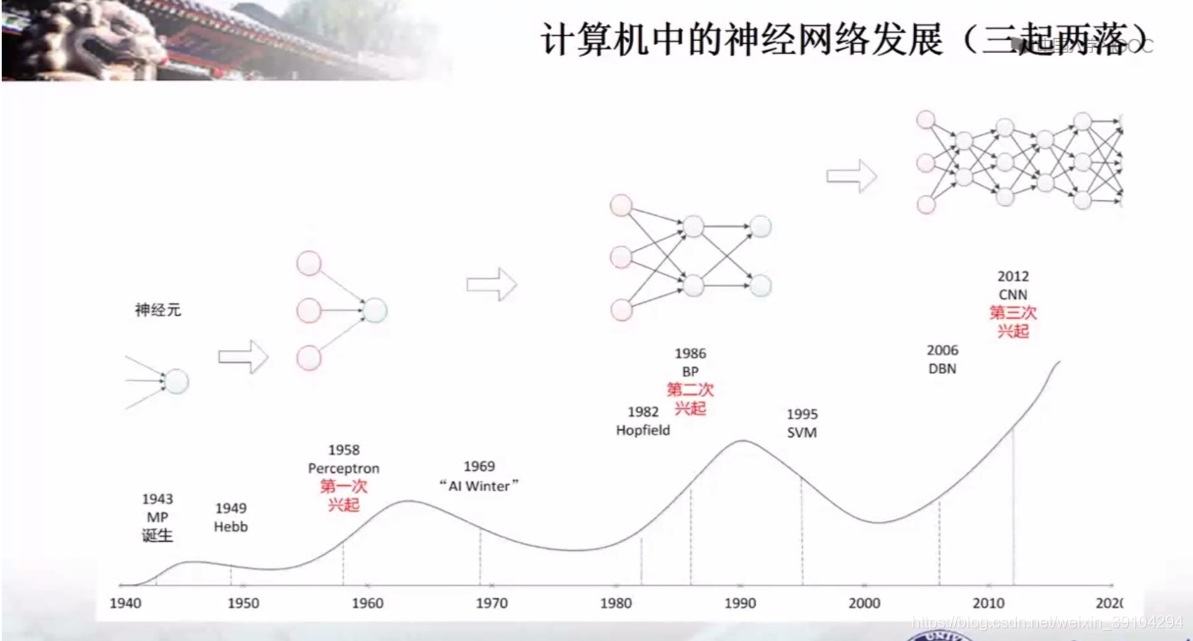
(在下面的计算机网络的发展中,可以更加直观的理解到深层网络。1986年是一层网络,2012年到了CNN出现了4层。层次化越来越深,对于知识的理解程度也越来越深刻。)

深度神经网络的发展过程:
机器学习最主要的应用:
- 对于连续数据的预测(预测房价)
- 对于离散数据的分类(判定是否为肿瘤)
第二讲:Python基础
就不记录了 直接翻看廖旭峰老师的博客或者其他材料即可
第三讲:TensorFlow框架
主要内容:张量、计算图和会话,以及讲解神经网络的前向传播和后向传播的实现方法;最终学会搭建神经网络,并总结神经网络的一般格式
3.1基本概念 张量(Tensor)、计算图(Graph)、会话(Session)
基于TensorFlow的NN:用张量(tensor)表示数据,用计算图(Graph)搭建神经网络,用会话(Session)执行计算图,优化线上的权重(参数w),得到模型
张量(tensor):多维数组(列表)
阶:张量的维数
| 维数 | 阶 | 名字 | 例子 |
| 0-D | 0 | 标量 scalar | s=1,2,3 |
| 1-D | 1 | 向量 vector | v=[1,2,3] |
| 2-D | 2 | 矩阵 matrix | m=[[1,2,3],[4,5,6],[7,8,9] |
| n-D | n | 张量 tensor | t=[[[....(张量的维度可以通过方括号的个数来确定) |
数据类型 :tf.float32 tf.int32 ···
# 导入TensorFlow模块
import tensorflow as tf
# 数据类型
# 定义一个张量[1.0,2.0]
a=tf.constant([1.0,2.0])
# 定义一个张量[3.0,4.0]
b=tf.constant([3.0,4.0])
# 实现一维向量加法
result = a+b
# 输出
print(result)
# 结果如下(输出的结果不是运算的结果) add:0 节点名:第0个输出;shape=(2,) shape维度 (2,)一维数组长度为2 dtype数据类型
# Tensor("add:0", shape=(2,), dtype=float32)
# result是一个名称为add:0的张量,shape=(2,)表示一维数组长度为2,dtype=float32表示数据类型为浮点型计算图(Graph):搭建神经网络的计算过程,只搭建不运算
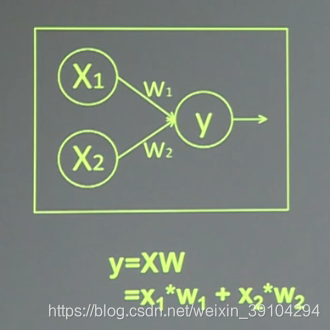
在前一讲中我们讲到,神经网络是由很多个神经元组成的。每个神经元的基本操作为数学运算中的加、乘运算。其中每条线上的w分别是输入在结果中占的权重。x1、x2表示输入,w1、w2分别是x1到y和x2到y的权重,y=x1*w1+x2*w2。
import tensorflow as tf
# 计算图(Graph)搭建神经网络的计算过程,只搭建不运算
# y = x1*W1 + x2*W2 其中w1和w2 分别是x1和x2到y的权重值
x1=tf.constant([[1.0,2.0]]) # x1是一个1行2列的张量
x2=tf.constant([[3.0],[4.0]]) #x2是一个2行1列的张量
y=tf.matmul(x1,x2) #用tf调用matmul# 实现矩阵乘法
print(y)
# 结果如下(输出的结果不是运算的结果,是一个张量Tensor)
# Tensor("MatMul:0", shape=(1, 1), dtype=float32)会话(Session):执行计算图中的节点运算,通过下面的代码将结果存入会话(Session)中,再通过输出sess对象得到结果
with tf.Session() as sess:
print(sess.run(result))则上面两个实例关于向量&关于矩阵的运算都可以输出结果,如下
#向量加法运算
import tensorflow as tf
a=tf.constant([1.0,2.0])
b=tf.constant([3.0,4.0])
result = a+b #实现一维向量加法
print(result)
with tf.Session() as sess:
print(sess.run(result))
#结果
# Tensor("add:0", shape=(2,), dtype=float32)
# [4. 6.]import tensorflow as tf
# 矩阵乘法运算
x=tf.constant([[1.0,2.0]])
w=tf.constant([[3.0],[4.0]])
y=tf.matmul(x,w)
print(y)
with tf.Session()as sess:
print(sess.run(y))
# 结果
# Tensor("MatMul:0", shape=(1, 1), dtype=float32)
# [[11.]]add.关于报错:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
原因是下载TensorFlow的版本不支持cpu的AVX2编译,不影响程序的运行,只是有些指令不能用,程序的效率低点
解决方案:在代码开头加入以下2行代码,降低TensorFlow的日志通知等级,忽略警告。
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'或者去下载一个支持cpu用AVX2编译的TensorFlow版本
3.2前向传播(搭建神经网络模型,让神经网络NN实现推理过程)
参数:即计算图(Graph)中神经元线上的权重w,用变量表示,随机给初值。
生成参数的方法是让w等于tf.Variable,把生成的方式写在括号里。
w= tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1))tf.Variable表示生成随机数,将生成方式写在括号里。例如上图中的tf.random_normal表示生成正态分布的随机数,形状是两行三列,标准差是2,均值是0,随机种子是1,随机种子如果去掉,每次生成的随机数将不一样。
注意:
- 随机种子如果去掉每次生成的随机数将不一致。
- 如果没有特殊要求标准差、均值、随机种子是可以不写的
TensorFlow中常用的生成随机数/数组的函数有:
| tf.constant | 生成直接给定值的数组 |
| tf.random_normal() | 生成正态分布随机数 |
| tf.truncated_normal() | 生成去掉过大偏离点的正态分布随机数 |
| tf.random_uniform() | 生成均匀分布随机数 |
| tf.zeros | 生成全0数组 |
| tf.ones | 生成全1数组 |
| tf.fill | 生成全定值数组 |
神经网络实现过程(步骤1~3是训练过程 步骤4是使用过程)
1、准备数据集,提取特征,作为输入喂给神经网络(neural network,NN)
2、搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
(NN前向传播算法-->计算输出)
3、大量特征数据喂给NN,迭代优化NN参数
(NN反向传播算法-->优化NN参数)
4、使用训练好的模型预测和分类
基于神经网络的机器学习主要分为两个过程,即训练模型过程和使用模型过程。
通过第一步、第二步、第三步的循环迭代来不断训练模型,通过第四步来使用模型进行预测和分类。一旦参数优化完成就可以固定这些参数,实现特定功能了。在实际应用中,我们会先使用现有的成熟网络结构,喂入新的数据,训练相应模型,判断是否能对喂入的从未见过的新数据作出正确响应,再适当更改网络结构,反复迭代,让机器自动训练参数找出最优结构和参数,以固定专用模型。(这里是从网上扒的)
前向传播:搭建神经网络模型,让神经网络NN实现推理过程
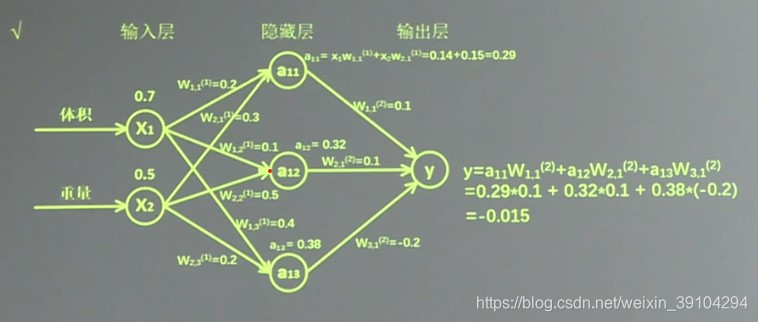
这块引用拿来详细讲解下上图的前向传播例子:
Eg NN:生产一批零件,将体积x1和重量x2位特征,把它们喂入神经网络,当体积和重量这组数据输入神经网络后会得到一个输出。
Input:以输入的特征值是:体积0.7 重量0.5为例。
Output:由搭建的神经网络可得,隐藏层节点a11=x1*w11+x2*w21=0.14+0.15=0.29,同理算得节点a12=0.32,a13=0.38,最终计算得到输出层Y=-0.015,这便实现了前向传播过程。
推导:
神经网络共有几层(或当前是第几层网络)都是指的计算层,输入层不是计算层,所以a为第一层网络,
- 输入层:
x是输入为1X2矩阵;表示一次输入一组特征,这组特征包含了 “体积” 和 “重量” 两个元素。
下编号(节点),上编号(层数) 为待优化的参数
参数
- 输入层到第一层,参数要满足前面两个节点,后面三个节点 ;因此
应该是个两行三列矩阵2x3;运算后得到的a是一个一行三列矩阵1x3。
- 第一层到输出层,参数要满足前面三个节点,后面一个节点;所以
是三行一列矩阵3x1。
- 隐藏层:
隐藏层的计算;我们把每层输入与线上的权重
a= tf.matmul(X,
y= tf.matmul(a,
- 输出层:
想要输出结果,就需要用到Session会话,利用with结构来实现。把所有的所有变量初始化过程、计算过程都要放到 sess.run 函数中
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对输入给出相应的输出。下面是结合分段代码讲解:
#变量初始化,计算图节点运算都有要用会话(with结构)实现 with tf.Session() as sess: sess.run() #变量初始化:在sess.run函数中用tf.global_variables_initializer() init__op=tf.global_variables() sess.run(init__op) #计算图节点运算:在sess.run函数中写入待运算的节点 sess.run(y) #用tf.plaeholder 占位,在sess.run函数中用feed_dict喂数据 # 如果一次喂一组数据shape的第一维位置写1,第二维位置看有几个输入特征; # 如果一次想喂多组数据,shape的第一维位置可以写None表示先空着,第二维位置写有几个输入特征。 # 喂一组数据: x=tf.placeholder(tf.float32,shape=(1,2)) sess.run(y,feed_dict={x:[[0.5,0.6]]}) # 喂多组数据: x=tf.placeholder(tf.float32,shape=(None,2)) sess.run(y,feed_dict={x:[[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})以输入的特征值是:体积0.7 重量0.5 的例子的实现整体代码如下
#!/user/bin/env python3 # -*- coding: utf-8 -*- # 定义两层简单神经网络(全连接) import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #导入TensorFlow模块,并简写为tf import tensorflow as tf # 定义神经网络的输入和神经元上的参数权重 x = tf.constant([[0.7,0.5]]) #定义体积为0.7 重量为0.5 w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) #定义一个2x3随机矩阵作为w1参数 w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #定义一个3x1随机矩阵作为w2参数 # 定义前向传播过程 a = tf.matmul(x,w1) y = tf.matmul(a,w2) # 到此为止 神经网络创建完成 #用会话Session来计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) print(sess.run(y)) ''' [[ 3.0904665]] '''另一种输入方式,引入tf.placeholder实现输入定义 (sess.run中以feed_dict={}喂一组数据)
#!/user/bin/env python3 # -*- coding: utf-8 -*- # 定义两层简单神经网络(全连接) import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #导入TensorFlow模块,并简写为tf import tensorflow as tf # 定义输入和参数 # 用placeholder实现输入定义 (sess.run中喂一组数据) x = tf.placeholder(tf.float32, shape=(1, 2)) #这里定义了x是一行两列的矩阵 w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) # 定义前向传播过程 a = tf.matmul(x, w1) y = tf.matmul(a, w2) #到此为止 神经网络创建完成 # 用会话计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) print(sess.run(y, feed_dict={x: [[0.7,0.5]]})) #feed_dict={} 用字典把特征喂入 ''' [[3.0904665]] '''喂入多组数据给神经网络,注意tf.placeholder()函数中的参数的赋值变化
#!/user/bin/env python3 # -*- coding: utf-8 -*- # 两层简单神经网络(全连接) import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf # 定义输入和参数 # 用placeholder定义输入(sess.run喂多组数据) x = tf.placeholder(tf.float32, shape=(None, 2)) # shape的第一个参数是None表示不知道,这样在with结构中可以一次喂入多组输入; # shape的第二个参数为2,因为我们已经知道了x的输入是体积和重量这两个特征 w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) # 定义前向传播过程 a = tf.matmul(x, w1) y = tf.matmul(a, w2) # 到此为止 神经网络创建完成 # 调用会话计算结果 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) print("result:") print(sess.run(y, feed_dict={x: [[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})) print("w1:") print(sess.run(w1)) print("w2:") print(sess.run(w2)) ''' result: [[ 3.0904665 ] [ 1.2236414 ] [ 1.72707319] [ 2.23050475]] w1: [[-0.81131822 1.48459876 0.06532937] [-2.4427042 0.0992484 0.59122431]] w2: [[-0.81131822] [ 1.48459876] [ 0.06532937]] '''
到此为止,搭建神经网络的前向传播就完成了。从输入到输出(先搭建计算图,再用会话执行)
(NN前向传播算法-->计算输出)
这条引用拿来归纳TensorFlow神经网络的几个基本点:
在 TensorFlow 中,数据不是以整数、浮点数或者字符串形式存储的。这些值被封装在一个叫做 tensor 的对象中;tf.constant 返回的 tensor 是一个常量 tensor,因为这个 tensor 的值不会变
- 操作(Op/operation):在 TensorFlow 的运行时中,它是一种类似 add 或 matmul 或 concat的运算
- 张量(Tensor):表示数据。Tensor是一种特定的多维数组。每一个tensor值在graph上都是一个op
- 计算图(Graph):描述运算任务。把运算任务描述成一个直接的无环图形(DAG),图表中的节点(node)代表必须要实现的一些操作。图中的边代表数据或者可控的依赖。
- 会话(Session):运行Tensorflow操作的类,Session 提供在图中执行操作的一些方法。Session封装了被执行操作和Tensor计算的环境,运行session.run()可以获得你要进行运算的结果。启动图的第一步是创建一个 Session 对象。
- tf.placeholder(dtype,shape=None,name=None) :在实际应用中,我们可以一次喂入一组或多组输入,先用tf.placeholder给输入占位,方便输入的处理。dtype:数据类型,喂给TensorFlow的张量元素的类型; shape:数据形状[x,y];表示有x组输入,y表示每组输入有y个特征。name:名称;返回值:张量Tensor类型
3.3反向传播(大量特征数据喂给NN,迭代优化NN参数)
反向传播:训练模型数据,在所有参数上用梯度下降,使NN模型再训练数据上的损失函数最小。
损失函数(loss):预测值(y|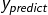
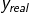
均方误差MSE: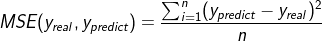
loss =tf.reduce_mean(tf.square(y_ - y)) 反向传播训练方法:以减小loss值为优化目标,分别有3种不同的方法可以使用——梯度下降、momentum优化器、adam优化器等
在TensorFlow中代码表示分别如下:
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss)
train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss)
这个引用块拿来解释下这三种优化方法:(这里是搬运自网上的,等会再总结下)
- tf.train.GradientDescentOptimizer()
使用随机梯度下降算法,使参数沿着梯度的反方向,即总损失减小的方向移动,实现更新参数。
- tf.train.MomentumOptimizer()
在更新参数时,利用了超参数,实现更新参数。
- tf.train.AdamOptimizer()
是利用自适应学习率的优化算法,Adam 算法和随机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学习率在训练过程中并不会改变。而 Adam 算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。 学习率:决定每次参数更新的幅度。优化器中都需要一个叫做学习率的参数,使用时,如果学习率选择过大会出现震荡不收敛的情况,如果学习率选择过小,会出现收敛速度慢的情况。我们可以选个比较小的值填入,比如0.01、0.001。
学习率:决定参数每次更新的幅度
神经网络实现过程(步骤1~3是训练过程 步骤4是使用过程)
1、准备数据集,提取特征,作为输入喂给神经网络(neural network,NN)
2、搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
(NN前向传播算法-->计算输出)
3、大量特征数据喂给NN,迭代优化NN参数
(NN反向传播算法-->优化NN参数)
4、使用训练好的模型预测和分类
下面完整实现一下神经网络的4个步骤,随机产生32组生产出的零件的体积和重量,训练3000轮,每500轮输出一次损失函数。
#!/user/bin/env python3
# -*- coding: utf-8 -*-
# 两层简单神经网络(全连接)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
# 导入python的科学计算模块 numpy
import numpy as np
# 定义一次喂入神经网络的数据量 数据不宜过大
BATCH_SIZE = 8
seed = 23455 #这里设置seed的目的在于使得老师的数据能够保持一致,方便调试
# 生成随机数据集和标签 基于seed产生随机数
rng = np.random.RandomState(seed)
# 生成数据集 随机数返回32行2列的矩阵 表示32组包含体积和重量的数据 作为输入数据集
X = rng.rand(32,2)
# 从X这个32行2列的矩阵中 取出一行 判断是否合格 如果合格则给Y赋值为1;如果不合格则给Y赋值为0
# 生成已知标签 完成数据标注功能(已知结果正确答案)
Y_ = [[int (x0 + x1 <1 )] for (x0,x1) in X]
print("Input X:")
print(X)
print("Label Y_:")
print(Y_)
# 1定义神经网络的输入、参数和输出,定义前向传播过程
# x是输入数据 由于输入的组数位置则第一个参数为None;第二个参数为已知的体积和重量特征则为2
x = tf.placeholder(tf.float32,shape=(None,2))
# y_是数据已知的标签,个数也是未知,但是特征已知是合格与否
y_ = tf.placeholder(tf.float32,shape=(None,1))
# 关于参数的设定 输入是每组包含2个特征的数据 输出是合格与否的1个特征值
# 因此与输入处理相关的W1参数的行是2;与输出最后一步处理的参数W2的列是1
# 中间数3 为神经网络隐藏层的神经元个数 [2,3] [3,1]
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 2定义损失函数及反向传播方法。
loss_mse = tf.reduce_mean(tf.square(y - y_))
# 三种损失函数 这里用的是 梯度下降
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
# train_step = tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse)
# train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse)
# 3生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 输出目前(未经训练)的参数取值。
print("W1:")
print(sess.run(w1))
print("W2::")
print(sess.run(w2))
print("\n")
# 训练模型。
STEPS = 3000
for i in range(STEPS):
start = (i * BATCH_SIZE) % 32
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
if i % 500 == 0:
total_loss = sess.run(loss_mse, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss_mse on all data is %g" % (i, total_loss))
# 输出训练后的参数取值。
print("\n")
print("W1:")
print(sess.run(w1))
print("W2:")
print(sess.run(w2))
'''
Input X:
[[ 0.83494319 0.11482951]
[ 0.66899751 0.46594987]
[ 0.60181666 0.58838408]
[ 0.31836656 0.20502072]
[ 0.87043944 0.02679395]
[ 0.41539811 0.43938369]
[ 0.68635684 0.24833404]
[ 0.97315228 0.68541849]
[ 0.03081617 0.89479913]
[ 0.24665715 0.28584862]
[ 0.31375667 0.47718349]
[ 0.56689254 0.77079148]
[ 0.7321604 0.35828963]
[ 0.15724842 0.94294584]
[ 0.34933722 0.84634483]
[ 0.50304053 0.81299619]
[ 0.23869886 0.9895604 ]
[ 0.4636501 0.32531094]
[ 0.36510487 0.97365522]
[ 0.73350238 0.83833013]
[ 0.61810158 0.12580353]
[ 0.59274817 0.18779828]
[ 0.87150299 0.34679501]
[ 0.25883219 0.50002932]
[ 0.75690948 0.83429824]
[ 0.29316649 0.05646578]
[ 0.10409134 0.88235166]
[ 0.06727785 0.57784761]
[ 0.38492705 0.48384792]
[ 0.69234428 0.19687348]
[ 0.42783492 0.73416985]
[ 0.09696069 0.04883936]]
Label Y_:
[[1], [0], [0], [1], [1], [1], [1], [0], [1], [1], [1], [0], [0], [0], [0], [0], [0], [1], [0], [0], [1], [1], [0], [1], [0], [1], [1], [1], [1], [1], [0], [1]]
W1:
[[-0.81131822 1.48459876 0.06532937]
[-2.4427042 0.0992484 0.59122431]]
W2::
[[-0.81131822]
[ 1.48459876]
[ 0.06532937]]
After 0 training step(s), loss_mse on all data is 5.13118
After 500 training step(s), loss_mse on all data is 0.429111
After 1000 training step(s), loss_mse on all data is 0.409789
After 1500 training step(s), loss_mse on all data is 0.399923
After 2000 training step(s), loss_mse on all data is 0.394146
After 2500 training step(s), loss_mse on all data is 0.390597
W1:
[[-0.70006633 0.9136318 0.08953571]
[-2.3402493 -0.14641267 0.58823055]]
W2:
[[-0.06024267]
[ 0.91956186]
[-0.0682071 ]]
Process finished with exit code 0
'''这块引用拿来解释一下上一段代码中的一些函数
rng = np.random.RandomState(seed)
搭建神经网络的八股(八股就是格式的意思,源于科举制度的八股文...):
- 准备
- 前向传播
- 反向传播
- 迭代循环
1、准备:
import 常量定义 生成或导入数据集
2、前向传播:定义输入、参数以及输出
x=定义输入Input 对应的组数和每组特征数 y_=定义标签Lable 对应的组数和标签特征数 w1=定义输入层到第一层的权重参数 行号要于输入的每组特征数一致 w2=定义第一层到输出层的权重参数 列号要于输出的标签特征数一致 a=第一层得到的结果 传递给下一层 y=输出层得到的结果
3、反向传播 :定义损失函数、反向传播方法
loss= train_step=
4、迭代循环:生成会话,迭代训练STEPS轮
with tf.session() as sess Init_op=tf. global_variables_initializer() sess_run(init_op) STEPS=3000 for i in range(STEPS): start= end= sess.run(train_step, feed_dict:)
第四讲、神经网络优化
主要内容:
4.1损失函数
神经元的模型建立:神经网络是以神经元为基本单位构成的,建造怎样的数学模型来实现在计算机中定义类似于人脑中的神经元
在上一节中,我们定义的神经元模型是
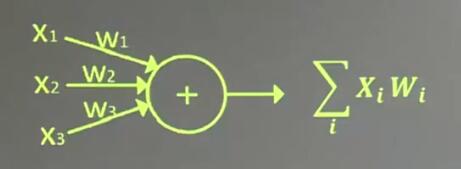
初代神经元 在1943年McCulloch Pitts参考生物学神经元模型加入了 激活函数(activation function)和偏置项(bias)
其中 f 是激活函数,b是偏置项

激活函数和偏置项神经元 以后的神经网络会以添加了激活函数和偏置项的神经元为基本单元收尾相接组成
激活函数(activation function)
激活函数引入的目的:引入非线性激活因素,提高模型的表达力。常用的激活函数有relu、sigmoid、tanh等。
三种不同的激活函数:
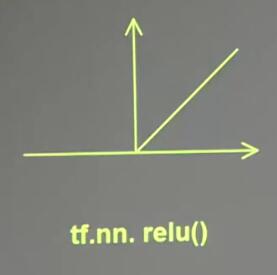
① 激活函数relu:
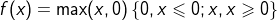
tf.nn.relu() #在Tensorflow中的表示relu()数学图形

tf.nn.relu() ② 激活函数sigmoid:
tf.nn.sigmoid() #在Tensorflow中的表示sigmoid()数学图形
tf.nn.relu().jpg ③ 激活函数tanh:
tf.nn.tanh() #在Tensorflow中的表示tanh()数学图形

tf.nn.tanh().jpg
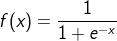
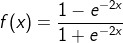
神经复杂度:多用NN层数和NN参数个数表示
层数 = 隐藏层的个数+1个输出层
总参数 = 总 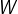
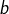
举例 下图的神经网络 2层NN 参数=(3*4+4)+(4*2+2)=26

NN
神经网络的优化(学习率learning_rate、滑动平均ema、正则化regularization)
损失函数(loss):用来表示预测值(y|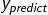
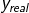
常用的损失函数有均方误差(mse Mean Squaread Error)、自定义 和 交叉熵(CE Cross Entropy)等
均方误差 mse:
loss_mse = tf.reduce_mean(tf.square(y_ - y)) #在TensorFlow中的表示举例:预测酸奶日销量 y来拟定每日的酸奶产量,影响日销量的两个因素分别是x1和 x2。
应提前采集的数据有:一段时间内,每日的 x1 因素、x2因素和真实销量 y_。采集的数据应当尽量多。在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用 Tensorflow 中函数随机生成 x1、 x2,制造标准答案y_= x1 + x2,为了更真实,求和后还加了正负 0.05 的随机噪声。 我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。
完整代码如下:#!/user/bin/env python3 # -*- coding: utf-8 -*- import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 导入模块 import tensorflow as tf import numpy as np BATCH_SIZE=8 SEED=234555 # 损失影响规则 预测多导致滞销和预测少导致利率不足的影响是等效的 # 生成数据集 rdm = np.random.RandomState(SEED) X = rdm.rand(32,2) Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] #1定义神经网络的输入、参数和输出,定义前向传播过程 x = tf.placeholder(tf.float32, shape=(None, 2)) y_ = tf.placeholder(tf.float32, shape=(None, 1)) w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w1) #2定义损失函数及反向传播方法。 #定义损失函数为MSE,反向传播方法为梯度下降,学习率定义为0.001 loss_mse = tf.reduce_mean(tf.square(y_ - y)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse) #3生成会话,训练STEPS轮 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 20000 for i in range(STEPS): start = (i*BATCH_SIZE) % 32 end = (i*BATCH_SIZE) % 32 + BATCH_SIZE sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]}) if i % 500 == 0: print("After %d training steps, w1 is: ") print(i) print(sess.run(w1)) print("\n") print("Final w1 is: \n") print(sess.run(w1)) #在本代码#2中尝试其他反向传播方法,看对收敛速度的影响,把体会写到笔记中 ''' 最终结果 Final w1 is: [[ 0.93673158] [ 1.07801604]] '''
自定义损失函数:由于在实际建模中的不同情况有不同要求,故TensorFlow可以根据实际项目的需要来自定义损失函数,让我们可以更好的训练出满足开发者需要的模型。
以上面的酸奶店预测商品销量为例;如果预测多了则损失成本,如果预测少了则损失利润。单份酸奶的成本和利润是不一样的,故需要进行损失函数自定义。将损失函数定义为分段函数来分别进行计算,分别是预测少了损失利润;预测多了损失成本。

自定义损失函数(分段进行计算) zia 在TensorFlo示zai 是
在TensorFlow中的表示是
loss = tf.reduce_sum(tf.where(tf.greater(y.y_),COST(y-y_),PROFIT(y_-y)))如:预测酸奶销量,酸奶成本(COST)1元;酸奶利润(PROFIT)9元。预测少了损失利润9元,大于预测多了损失成本1元。因此我们可以得到预测少了会损失更大,希望生成的预测函数往多了预测。
# 预测少了损失大,故不要预测少,故生成的模型会多预测一些 # 0导入模块,生成数据集 import tensorflow as tf import numpy as np BATCH_SIZE = 8 SEED = 23455 # 酸奶成本1元 COST = 1 # 酸奶利润9元 PROFIT = 9 rdm = np.random.RandomState(SEED) X = rdm.rand(32,2) Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] #1定义神经网络的输入、参数和输出,定义前向传播过程。 x = tf.placeholder(tf.float32, shape=(None, 2)) y_ = tf.placeholder(tf.float32, shape=(None, 1)) w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w1) #2定义损失函数及反向传播方法。 # 定义损失函数使得预测少了的损失大,于是模型应该偏向多的方向预测。 loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_)*COST, (y_ - y)*PROFIT)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss) #3生成会话,训练STEPS轮。 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) STEPS = 3000 for i in range(STEPS): start = (i*BATCH_SIZE) % 32 end = (i*BATCH_SIZE) % 32 + BATCH_SIZE sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]}) if i % 500 == 0: print("After %d training steps, w1 is: " % (i)) print(sess.run(w1), "\n") print("Final w1 is: \n", sess.run(w1)) ''' 最终结果 Final w1 is: [[ 1.02965927] [ 1.0484432 ]] '''
这里我遇到了一个报错:raise RuntimeError('Attempted to use a closed Session.')
产生这个报错的原因是我的最后一句print语句打印sess.run(w1);这里我缩进错误。没有保持在with机制内部,导致了获取不到Session里面的值。