一、基于tensorflow的NN
——定义:用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权 重(参数),得到模型
——张量(tensor):多维数组(列表)
0阶张量称作标量,表示一个单独的数;
举例 S=123
1阶张量称作向量,表示一个一维数组
举例 V=[1,2,3]
2阶张量称作矩阵,表示一个二维数组,它可以有i行j列个元素,每个元素可以用行号和列号共同索引到;
举例 m=[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
判断张量是几阶的,就通过张量右边的方括号数,0个是0阶,n个是n阶,张量可以表示0阶到n阶数组(列表);
举例 t=[ [ [… ] ] ]为3阶。

——阶:张量的维数
——数据类型:Tensorflow的数据类型有tf.float32、tf.int32等。
实现Tensorflow的加法
#引入模块
import tensorflow as tf
#定义一个张量等于[1.0,2.0]
a=tf.constant([1.0,2.0])
#定义一个张量等于[3.0,4.0]
b=tf.constant([3.0,4.0])
#实现a加b的加法
result=a+b
#打印出结果 可以打印出这样一句话:
#Tensor(“add:0”, shape=(2, ), dtype=float32)
#意思为result是一个名称为add:0的张量,shape=(2,)表示一维数组长度为2,dtype=float32表示数据类型为浮点型。
print result
——计算图(Graph):搭建神经网络的计算过程,是承载一个或多个计算节点的一张图,只搭建网络,不运算。
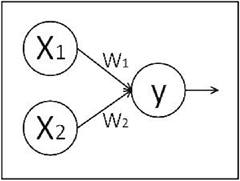
x1、x2表示输入,w1、w2分别是x1到y和x2到y的权重,y=x1w1+x2w2。
#引入模块
import tensorflow as tf
#定义一个2阶张量等于[[1.0,2.0]] (一行两列)
x = tf.constant([[1.0, 2.0]])
#定义一个2阶张量等于[[3.0],[4.0]] (两行一列)
w = tf.constant([[3.0], [4.0]]) (一行一列的张量)
#实现xw矩阵乘法
y=tf.matmul(x,w)
#打印出结果 可以打印出这样一句话:Tensor(“matmul:0”, shape(1,1), dtype=float32),
print y
#执行会话并打印出执行后的结果
#可以打印出这样的结果:[[11.]]
with tf.Session() as sess:
print sess.run(y)
print的结果显示y是一个张量,只搭建承载计算过程的计算图,并没有运算,如果我们想得到运算结果就要用到“会话Session()”了。
——会话(Session):执行计算图中的节点运算。我们用with结构实现
with tf.Session() as sess:
print sess.run(y)
在vim编辑器中运行Session()会话时,有时会出现“提示warning”,是因为有的电脑可以支持加速指令,但是运行代码时并没有启动这些指令。可以把这些“提示warning”暂时屏蔽掉。屏蔽方法为进入主目录下的bashrc文件,在bashrc 文件中加入这样一句 export TF_CPP_MIN_LOG_LEVEL=2,从而把“提示 warning”等级降低。source 命令用于重新执行修改的初始化文件,使之立即生效,而不必注销并重新登录。
vim ~/.bashrc
source ~/.bashrc
——参数:
即神经网络线上的权重w,用变量表示,随机给初值
生成参数的方法是让w等于tf.Variable,把生成的方式写在括号里。
w= tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1))

注意:
1、随机种子如果去掉每次生成的随机数将不一致。
2、如果没有特殊要求标准差、均值、随机种子是可以不写的

二、神经网络实现过程
当我们知道张量、计算图、会话和参数后,我们可以讨论神经网络的实现过程了。
(步骤1~3是训练过程 步骤4是使用过程)
1、准备数据集,提取特征,作为输入喂给神经网络(Neural Network,NN)
2、搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
( NN前向传播算法 -----> 计算输出)
3、大量特征数据喂给NN,迭代优化NN参数
( NN反向传播算法 -----> 优化参数训练模型)
4、使用训练好的模型预测和分类
由此可见,基于神经网络的机器学习主要分为两个过程,即训练过程和使用过程。
训练过程是第一步、第二步、第三步的循环迭代,使用过程是第四步,一旦参数优化完成就可以固定这些参数,实现特定应用了。很多实际应用中,我们会先使用现有的成熟网络结构,喂入新的数据,训练相应模型,判断是否能对喂入的从未见过的新数据作出正确响应,再适当更改网络结构,反复迭代,让机器自动训练参数找出最优结构和参数,以固定专用模型。
三、前向传播:
搭建神经网络模型,让神经网络NN实现推理过程

这块引用拿来详细讲解下上图的前向传播例子:
Eg NN:生产一批零件,将体积x1和重量x2位特征,把它们喂入神经网络,当体积和重量这组数据输入神经网络后会得到一个输出。
Input:以输入的特征值是:体积0.7 重量0.5为例。
Output:由搭建的神经网络可得,隐藏层节点a11=x1w11+x2w21=0.14+0.15=0.29,同理算得节点a12=0.32,a13=0.38,最终计算得到输出层Y=-0.015,这便实现了前向传播过程。
推导:
神经网络共有几层(或当前是第几层网络)都是指的计算层,输入层不是计算层,所以a为第一层网络,第一层 X是输入为1X2矩阵 用x表示输入,是一个1行2列矩阵,表示一次输入一组特征,这组特征包含了 体积和重量两个元素。
W 前节点编号,后节点编号(层数) 为待优化的参数
对于第一层的w 前面有两个节点,后面有三个节点 w应该是个两行三列矩阵,
我们这样表示:
所以a为第一层网络,a是一个一行三列矩阵。
我们这样表示:a(1)=[a11, a12, a13]=XW(1)
第二层参数要满足前面三个节点,后面一个节点,所以W(2) 是三行一列矩阵。 我们这样表示:

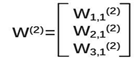
输入层:
x是输入为1X2矩阵;表示一次输入一组特征,这组特征包含了 “体积” 和 “重量” 两个元素。
下编号(节点),上编号(层数) 为待优化的参数参数w的确定:
输入层到第一层,参数要满足前面两个节点,后面三个节点 ;因此应该是个两行三列矩阵2x3;运算后得到的a是一个一行三列矩阵1x3。
第一层到输出层,参数要满足前面三个节
点,后面一个节点;所以 是三行一列矩阵3x1。 隐藏层:
隐藏层的计算;我们把每层输入与线上的权重进行矩阵乘法,这样用矩阵乘法可以计算出输出y了。
a= tf.matmul(X,)
y= tf.matmul(a, )
输出层:
想要输出结果,就需要用到Session会话,利用with结构来实现。把所有的所有变量初始化过程、计算过程都要放到 sess.run 函数中 前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对输入给出相应的输出。
①用placeholder实现输入定义(sess.run中喂入一组数据)的情况 第一组喂体积0.7、重量0.5
#coding:utf-8
#两层简单神经网络(全连接)
import tensorflow as tf
#定义输入和参数
#用placeholder实现输入定义 (sess.run中喂一组数据)
x = tf.placeholder(tf.float32, shape=(1, 2)) (一行两列)
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
#定义前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
#用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op) (执行计算)
print "y in tf3_4.py is:\n" , sess.run(y, feed_dict={x: [[0.7,0.5]]}) 将x的一组特征喂入)
`
②用placeholder实现输入定义(sess.run中喂入多组数据)的情况第一组喂体积0.7、重量0.5,第二组喂体积0.2、重量0.3,第三组喂体积0.3 、重量0.4,第四组喂体积0.4、重量0.5.
#coding:utf-8
#两层简单神经网络(全连接)
import tensorflow as tf
#定义输入和参数
#用placeholder定义输入(sess.run喂多组数据)(不知道喂入多少组,shap的第一个参数为none)
x = tf.placeholder(tf.float32, shape=(None, 2))
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
#定义前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
#调用会话计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print "the result of tf3_5.py is:\n",sess.run(y, feed_dict={x: [[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
print "w1:\n", sess.run(w1)
print "w2:\n", sess.run(w2)
以输入的特征值是:体积0.7 重量0.5 的例子的实现整体代码如下
#!/user/bin/env python3
# -*- coding: utf-8 -*-
# 定义两层简单神经网络(全连接)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#导入TensorFlow模块,并简写为tf
import tensorflow as tf
# 定义神经网络的输入和神经元上的参数权重
x = tf.constant([[0.7,0.5]]) #定义体积为0.7 重量为0.5
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) #定义一个2x3随机矩阵作为w1参数
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #定义一个3x1随机矩阵作为w2参数
# 定义前向传播过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
# 到此为止 神经网络创建完成
#用会话Session来计算结果
with tf.Session() as sess:
init_op = tf.global_variables_initializer() (i把初始化所有的函数,简写为初始化为节点nit_op)
sess.run(init_op)
print(sess.run(y))
'''
[[ 3.0904665]]
'''
这条引用拿来归纳TensorFlow神经网络的几个基本点:
在 TensorFlow 中,数据不是以整数、浮点数或者字符串形式存储的。这些值被封装在一个叫做 tensor的对象中;tf.constant 返回的 tensor 是一个常量 tensor,因为这个 tensor 的值不会变
操作(Op/operation):在 TensorFlow 的运行时中,它是一种类似 add 或 matmul 或 concat的运算
张量(Tensor):表示数据。Tensor是一种特定的多维数组。每一个tensor值在graph上都是一个op
计算图(Graph):描述运算任务。把运算任务描述成一个直接的无环图形(DAG),图表中的节点(node)代表必须要实现的一些操作。图中的边代表数据或者可控的依赖。
会话(Session):运行Tensorflow操作的类,Session 提供在图中执行操作的一些方法。Session封装了被执行操作和Tensor计算的环境,运行session.run()可以获得你要进行运算的结果。启动图的第一步是创建一个Session
对象。tf.placeholder(dtype,shape=None,name=None) 在实际应用中,我们可以一次喂入一组或多组输入,先用tf.placeholder给输入占位,方便输入的处理。dtype:数据类型,喂给TensorFlow的张量元素的类型;
shape:数据形状[x,y];表示有x组输入,y表示每组输入有y个特征。name:名称;返回值:张量Tensor类型
四、反向传播
一、反向传播
反向传播:训练模型参数,在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小。
损失函数(loss):计算得到的预测值y与已知答案y_的差距
损失函数的计算有很多方法,均方误差MSE是比较常用的方法之一。
均方误差MSE:求前向传播计算结果与已知答案之差的平方再求平均。
用tensorflow函数表示为: loss_mse =tf.reduce_mean(tf.square(y_ - y))
反向传播训练方法:
以减小loss值为优化目标,有梯度下降、momentum优化器、adam优化器等优化方法。
在TensorFlow中代码表示分别如下:
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss)
train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss)
学习率:决定参数每次更新的幅度
代码(背)
#加入编码兼容格式utf-8
#coding:utf-8
#0导入模块numpy(python 的科学计算模块),生成模拟数据集。
import tensorflow as tf
import numpy as np
#BATCH一次喂入神经网络多少组数据,seed随机生成
BATCH_SIZE = 8
SEED = 23455
#基于seed产生随机数
rdm = np.random.RandomState(SEED)
#随机数返回32行2列的矩阵 表示32组 体积和重量 作为输入数据集
X = rdm.rand(32,2)
#从X这个32行2列的矩阵中 取出一行 判断如果和小于1 给Y赋值1 如果和不小于1 给Y赋值0
#作为输入数据集的标签(正确答案)
Y_ = [[int(x0 + x1 < 1)] for (x0, x1) in X]
print "X:\n",X
print "Y_:\n",Y_
#1定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2)) (输入)
y_= tf.placeholder(tf.float32, shape=(None, 1)) (标准答案)
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) (对应x)
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) (对应y)
#用矩阵乘法实现
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
#2定义损失函数loss及反向传播方法。
loss_mse = tf.reduce_mean(tf.square(y-y_)) (使用均方误差计算loss)
#使用梯度下降实现训练过程,学习率为0.001
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
#train_step = tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse) (Momentum优化方法)
#train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse) (Adam优化方法)
#3生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer() (初始化参数)
sess.run(init_op)
# 输出目前(未经训练)的参数取值。
print "w1:\n", sess.run(w1)
print "w2:\n", sess.run(w2)
print "\n"
# 训练模型。
#训练三千轮
STEPS = 3000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = start + BATCH_SIZE
# //从x的数据集和y的标签里面抽取相应的数据和标签喂入神经网络,用sess.run执行训练过程
sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})
//每500轮打印loss值
if i % 500 == 0:
total_loss = sess.run(loss_mse, feed_dict={x: X, y_: Y_})
print("After %d training step(s), loss_mse on all data is %g" % (i, total_loss))
# 输出训练(优化后的)后的参数取值。
print "\n"
print "w1:\n", sess.run(w1)
print "w2:\n", sess.run(w2)
由神经网络的实现结果,我们可以看出,总共训练3000轮,每轮从X的数据集 和Y的标签中抽取相对应的从start开始到end结束个特征值和标签,喂入神经网络,用sess.run求出loss,每500轮打印一次loss值。经过3000轮后,我们打印出最终训练好的参数w1、w2。
可以修改BATCH_SIZE 看看对loss的影响,可以训练次数增大来观察loss的减少过程,更改优化器来看看哪一个效果更好
五、搭建神经网络的八股
-
准备
-
前向传播
-
反向传播
-
迭代循环
1、准备
import
常量定义
生成或导入数据集
2、前向传播:定义输入、参数以及输出
x=定义输入Input 对应的组数和每组特征数
y_=定义标签Lable 对应的组数和标签特征数w1=定义输入层到第一层的权重参数 行号要于输入的每组特征数一致
w2=定义第一层到输出层的权重参数 列号要于输出的标签特征数一致a=第一层得到的结果 传递给下一层
y=输出层得到的结果
3、反向传播 :定义损失函数、反向传播方法
loss=
train_step=
4、迭代循环:生成会话,迭代训练STEPS轮
with tf.session() as sess
Init_op=tf. global_variables_initializer()
sess_run(init_op)
STEPS=3000 for i in range(STEPS):
start= end=
sess.run(train_step, feed_dict:)
`