1 数组+链表
首先HashMap是属于数组+链表的数据结构
数组:数组存储区间连续,占用内存比较严重(查找容易,插入/删除困难)
链表:链表存储区间离散,占用内存比较宽松(查找困难,插入/删除容易)
那么就可以结合数组和链表,设计出一种兼备二者优点的数据结构,就是哈希表(也叫散列表),HashMap底层就是一种散列表的数据结构
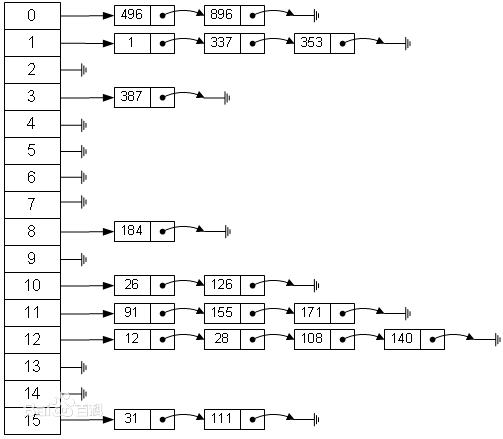
2 图表(图表源于百度--散列表)
3 HashMap 的主体方法
如图所示,这就是数组+链表的散列表,那么他是怎么做到的呢
a HashMap底层运用了一个内部静态类Entry,里面重要的属性大致有 key value next
b key value 都不用细述,主要是next
put int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; get int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
不同的key,可能会得到相同的index,那个这个链表又是怎么样加以区分的呢,就是通过next
index:15------>【 key1 value next(指向key2)】------------- -->【 key2 value next(指向下一个hash值对应的下标相同的key) 】
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next =B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
参考链接:http://blog.csdn.net/vking_wang/article/details/14166593