一、贝叶斯公式及分类
贝叶斯公式是在条件概率和全概率公式的基础上得来的,详细请参考:
https://blog.csdn.net/Hearthougan/article/details/75174210
贝叶斯公式p(yi|X) = p(X|yi) p(yi) / p(X) = p(yi) p(x1|yi) p(x2|yi) … p(xj|yi) / p(X)
P(X):待分类对象自身的概率,可忽略
P(yi):每个类别的先验概率,如P(军事)
P(X|yi):每个类别产生该对象的概率
P(xi|yi):每个类别产生该特征的概率,如P(苹果|科技)
那么我们知道了朴素贝叶斯公式,我们怎么来进行分类呢,也就是说我们要怎么求这个概率,这个过程中,我们首先要知道先验概率和条件概率即知道分子p(X|yi)和p(yi),为什么这里不说p(x)呢,因为这个概率始终是个固定值,可以约去,那么我们来说一下p(X|yi)怎么理解:
例如1:
• 总共训练数据1000篇,其中军事类300篇,科技类240篇,生活类140篇,…
• 军事类新闻中,单词"谷歌"出现在15篇中,单词“投资”出现9篇,上涨出现36篇
P(yi)
– p(军事)=0.3, p(科技)=0.24, p(生活)=0.14,…
P(xj|yi)
– P(谷歌|军事)=0.05, P(投资|军事)=0.03, P(上涨|军事)=0.12,…
– P(谷歌|科技)=0.15, P(投资|科技)=0.10, P(上涨|科技)=0.04,…
– P(谷歌|生活)=0.08, P(投资|生活)=0.13, P(上涨|生活)=0.18,…
例如2:
给大家100篇文章,其中50篇是军事、30篇财经、20篇体育
P(y=军事) = 50/100
P(y=财经) = 30/100
P(y=体育) = 20/100
P(X):这篇文章的概率=是一个固定值,可以忽略掉
P(yi|X)≈ P(yi)P(X|yi)
P(X|yi) :对于y指定的类别中,出现X的概率,X={x1,x2,x3,…},xi是文章X包含的所有单词
P(xi|yi):对于y指定的类别中,出现xi这个词的概率
y=军事,x1=军舰
X={军舰、大炮、航母}
P(X|y=军事) = P(x1=军舰|y=军事)*P(x2=大炮|y=军事)*P(x3=航母|y=军事)
前提:独立同分布=》朴素贝叶斯
P(yi|X)≈ P(yi)P(X|yi)
对每一个标签都求对应概率,最大者为该分类
为了完成NB分类问题,我们需要2类参数来支持
1、先验概率P(yi)
2、条件概率P(X|yi)
其实这里所谓的求这类的参数也就是求模型的过程,即参数就是模型。
在这里说明一下,我们在平时代码实现的过程中有两种求解条件概率的计算方法,这两类都可以计算条件概率:
第一种:
分子:军事类文章中包含“谷歌”这个词的文章个数
分母:军事类文章个数
p(x="谷歌"|y="军事"):分子 / 分母
第二种:
分子:军事类文章中包含“谷歌”这个词的个数
分母:军事类文章中所有词的个数
p(x="谷歌"|y="军事"):分子 / 分母
朴素贝叶斯说了这么多,有什么优缺点呢:
优点:简单有效,结果是概率,对二值和多值同样适用
二、Python代码实现
代码注释参考:https://blog.csdn.net/Jameslvt/article/details/81321145
数据准备:总共3116篇已经分好词的文件(文章),词与词之间用空格分开,每篇文章属于体育、财经和汽车三类中的一类,并且类别包含在文件名中。
数据转换:目的是把所有数据文件(每篇文章的类别和单词均转换成数字token)放到一个文件中,该文件的每一行表示一篇文章的内容,第一列为类别,最后一列是#号+原文件名称。
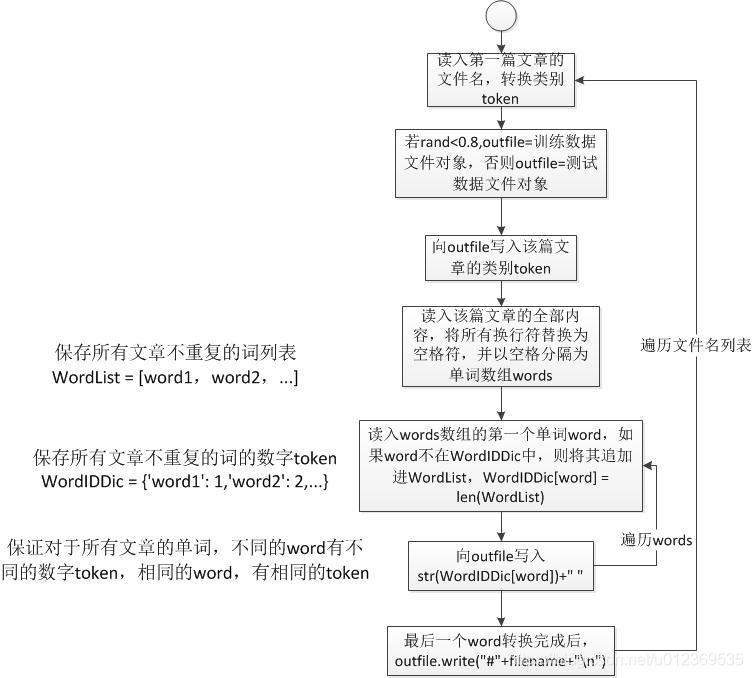
import sys
import os
import random
#列表,保存所有文章的不重复的词
WordList = []
#字典,保存所有文章的不重复的词的id值
WordIDDic = {}
#训练阈值
TrainingPercent = 0.8
#输入文件夹
inpath = sys.argv[1]
#输出的文件
OutFileName = sys.argv[2]
#输出的文件训练集是OutFileName.train,测试集是:OutFileName.test
trainOutFile = file(OutFileName+".train", "w")
testOutFile = file(OutFileName+".test", "w")
def ConvertData():
i = 0
tag = 0
for filename in os.listdir(inpath):
#只分析三大类的数据,财经,汽车,体育,并且给每个类别打个标示,财经是1,汽车2,体育3
if filename.find("business") != -1:
tag = 1
elif filename.find("auto") != -1:
tag = 2
elif filename.find("sport") != -1:
tag = 3
#统计一共读了多少篇文章
i += 1
#设置一个随机数,为了下面能够把数据按照二八原则分为训练集和测试集
rd = random.random()
#把测试集的文件对象赋给outfile变量
outfile = testOutFile
#若随机数小于0.8则把训练集文件对象赋值给outfile变量,这种操作是为了下面写入数据做准备
if rd < TrainingPercent:
outfile = trainOutFile
if i % 100 == 0:
print i,"files processed!\r",
#读入目录下的文章内容,inpath是目录地址,filename是目录下的文件名称
infile = file(inpath+'/'+filename, 'r')
#首先把三类文章的标签写入输出文件开头,后面加空格
outfile.write(str(tag)+" ")
#一次性全部读入,python中read,readline 不同的读的方式不一样
content = infile.read().strip()
#进行编码转义
content = content.decode("utf-8", 'ignore')
#因为一次性读入,所以会有换行的问题,这里直接把换行替换成空格,并且以空格切分开,words是个列表
words = content.replace('\n', ' ').split(' ')
for word in words:
if len(word.strip()) < 1:
continue
'''这里的代码是我觉得写的最好的一段代码,简单又复杂。
首先判断这个单词在不在token2Id的字典里面,若不在,将该单词添加到一个wordList列表中
然后将该单词存入token2Id的字典里面,key是word,value是wordList列表的长度
这个if判断的精华在于利用判断word是否在token2id的字典来进行去重复
'''
if word not in WordIDDic:
WordList.append(word)
WordIDDic[word] = len(WordList) #向字典添加新的键值对
#将word对应的value写入输出文件中
outfile.write(str(WordIDDic[word])+" ")
#最后一个单词转换完成后,用#号隔开文章内容和名称
outfile.write("#"+filename+"\n")
infile.close()
print i, "files loaded!"
print len(WordList), "unique words found!"
#首先调用ConvertData()函数
ConvertData()
trainOutFile.close()
testOutFile.close()
加载数据:目的是在所有训练文章中,
初始化ClassFeaProb字典,其表示各单词在各类别中的出现概率;
计算完成ClassFeaDic字典,其表示各单词在各类别中出现的频次;
计算完成ClassFreq字典,其表示各类别的文章数;
计算完成WordDic字典,其表示所有训练文章中出现的单词集合。
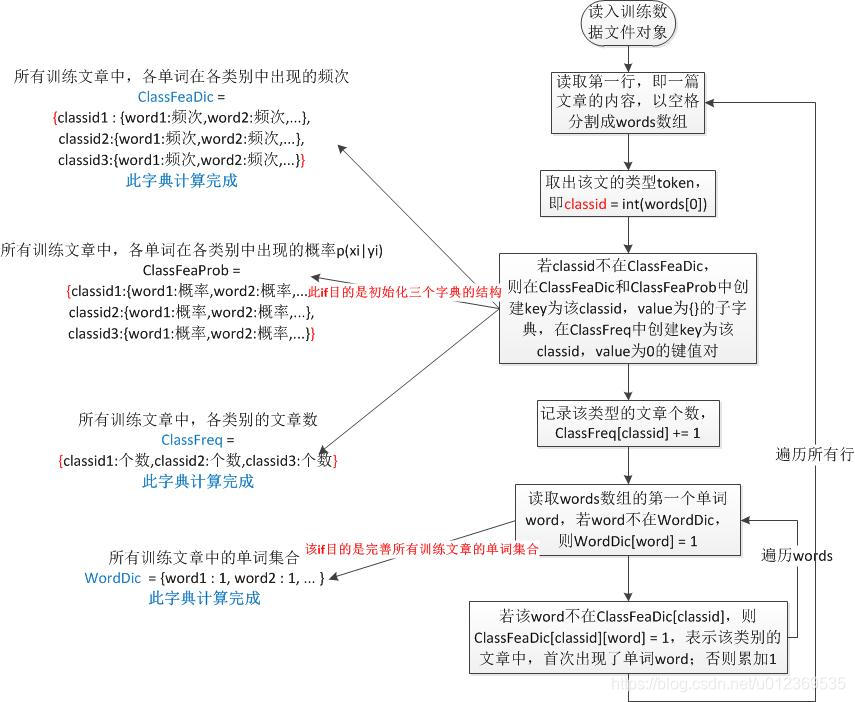
import sys
import os
import math
DefaultFreq = 0.1
TrainingDataFile = "nb_data.train"
ModelFile = "nb_data.model"
TestDataFile = "nb_data.test"
TestOutFile = "nb_data.out"
ClassFeaDic = {} #{classid :{自增长id:计数器}}
ClassFreq = {} #频次 classid下token的总数
WordDic = {} #token字典
ClassFeaProb = {} #条件概率字典
ClassDefaultProb = {}
ClassProb = {}
def Dedup(items):
tempDic = {}
for item in items:
if item not in tempDic:
tempDic[item] = True
return tempDic.keys()
#加载数据,初始化,记录每个类型文章的次数、每个文章的词语出现在每个类型下的次数
def LoadData():
i =0
#读入训练集
infile = file(TrainingDataFile, 'r')
#以行的方式读入,在上次的Data处理中已经转换成每一行的内容,首先读入一行
sline = infile.readline().strip()
#判断该文件是否有内容,循环所有的训练集
while len(sline) > 0:
#找到每行的#号和文章名,输出是个索引index数字
pos = sline.find("#")
if pos > 0:
#取出从该篇文章开始到#号的位置
sline = sline[:pos].strip()
#将取出的文章内容以空格分割开
words = sline.split(' ')
#判断文章有么有问题
if len(words) < 1:
print "Format error!"
break
#得到刚刚那三类文章的tag即财经是1,汽车2,体育3 赋给classid
classid = int(words[0])
#判断这类型文章在不在文章字典里面,不在进入if,在进行频次+1,为了求先验概率
if classid not in ClassFeaDic:
#记录每个类中的每个token的计数
ClassFeaDic[classid] = {}
#记录每个token在各自类中的概率
ClassFeaProb[classid] = {}
#记录每个类的文章个数
ClassFreq[classid] = 0
ClassFreq[classid] += 1
#获取除了文章标签的真正内容
words = words[1:]
#remove duplicate words, binary distribution
#words = Dedup(words)
for word in words:
if len(word) < 1:
continue
#获取每个词,这里词是我们转置的数字
wid = int(word)
#判断当前的词在不在词语字典里面,不在初始化为1
if wid not in WordDic:
WordDic[wid] = 1
#若当前词在该词的字典里面,紧接着判断当前词在不在当前classid文章中的字典里面,不在初始化为1,在的话记录频次
if wid not in ClassFeaDic[classid]:
ClassFeaDic[classid][wid] = 1
else:
ClassFeaDic[classid][wid] += 1
#记录读的总行数
i += 1
#接着再读入一行直到结束
sline = infile.readline().strip()
infile.close()
print i, "instances loaded!"
print len(ClassFreq), "classes!", len(WordDic), "words!"
计算模型:目的是
计算出各类别的先验概率ClassProb字典,即p(yi);
计算出各类别中出现各单词的条件概率ClassFeaProb字典,即p(xi|yi);
计算出各类别的默认概率ClassDefaultProb字典
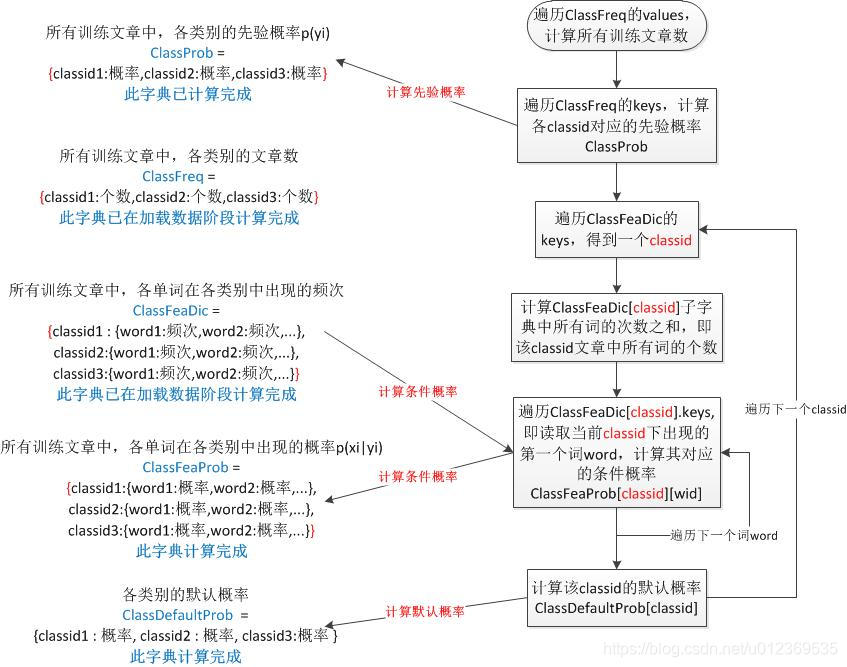
#计算模型,求先验概率p(yi)和条件概率p(x|yi)
def ComputeModel():
sum = 0.0
#循环遍历不同类文章记录的字典的value值,key是classid value是该类对应的频次
for freq in ClassFreq.values():
#sum将所有的value相加即得到三类文章的总的篇幅数
sum += freq
#循环遍历不同类文章记录的字典的key值,key是classid value是该类对应的频次
for classid in ClassFreq.keys():
#当前classid对应的先验概率,用体育举例子,体育类文章篇幅数除以总的篇幅数,循环计算三类文章各个先验概率
ClassProb[classid] = (float)(ClassFreq[classid])/(float)(sum)
#循环遍历每类文章中每个词频的字典中的key,key是classid,value是个字典{词:词频}
for classid in ClassFeaDic.keys():
#Multinomial Distribution
sum = 0.0
#循环遍历当前classid对应的value字典{词:词频},中的key即词
for wid in ClassFeaDic[classid].keys():
#统计当前类文章的词频次数
sum += ClassFeaDic[classid][wid]
#newsum = (float)(sum+len(WordDic)*DefaultFreq)
#为了使程序健壮,防止向下溢出,这里可以把sum+1
newsum = (float)(sum + 1)
#Binary Distribution
#newsum = (float)(ClassFreq[classid]+2*DefaultFreq)
#循环遍历当前类文章的的key即词
for wid in ClassFeaDic[classid].keys():
#存入条件概率值,用体育举例子,体育文章中铅球的条件概率=铅球在体育文章中的总数/体育文章的总词数
ClassFeaProb[classid][wid] = (float)(ClassFeaDic[classid][wid]+DefaultFreq)/newsum
#每一类文章设置一个默认的条件概率,防止在测试集时候一个词在当前类文章没有,就用该值
ClassDefaultProb[classid] = (float)(DefaultFreq) / newsum
return
存储模型:向文件中写入模型结果,即对所有训练文章来说,求得的每个类别的先验概率,以及每个类别下出现的单词的条件概率。其格式如下:其中,第一行的classid是按照ClassFreq.keys而来,第二到四行的classid是按照ClassFeaDic.keys而来。注:在计算模型阶段的所有字典中的key的顺序即classid的顺序都是一致的。
第一行: classid1 先验概率 默认概率 classid2 先验概率 默认概率 classid3 先验概率 默认概率
第二行:(classid1) word1_token 条件概率 word2_token 条件概率 word3_token 条件概率
第三行:(classid2) word1_token 条件概率 word2_token 条件概率 word3_token 条件概率
第四行:(classid3) word1_token 条件概率 word2_token 条件概率 word3_token 条件概率
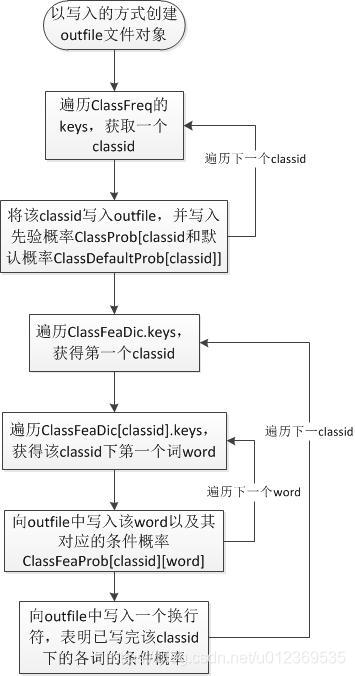
def SaveModel():
#以写的方式打开该类文件
outfile = file(ModelFile, 'w')
#循环遍历类别频次字典,获取三大类别的classid
for classid in ClassFreq.keys():
#将classid写入文件
outfile.write(str(classid))
outfile.write(' ')
#将获取的先验概率写入文件
outfile.write(str(ClassProb[classid]))
outfile.write(' ')
#将默认的每类别条件概率写入文件
outfile.write(str(ClassDefaultProb[classid]))
outfile.write(' ' )
#第一行遍历3类文章对应的不同概率,然后换行
outfile.write('\n')
#循环遍历每个类别对应的词和词频的字典,key是classid,value是{词:词频}
for classid in ClassFeaDic.keys():
#循环value的key即词
for wid in ClassFeaDic[classid].keys():
#将获得的词用来获取该词的条件概率
outfile.write(str(wid)+' '+str(ClassFeaProb[classid][wid]))
outfile.write(' ')
#每一类的文章模型为一行
outfile.write('\n')
outfile.close()
加载模型:目的是从已经计算好的模型文件中读取各字典,为预测阶段作数据准备
条件概率字典ClassFeaProb
先验概率字典ClassProb
默认概率字典ClassDefaultProb
单词字典WordDic
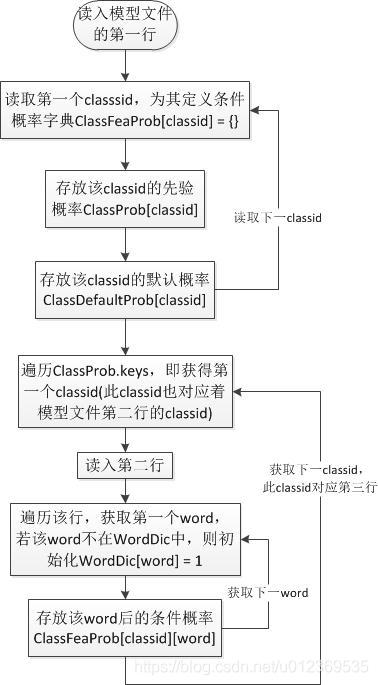
def LoadModel():
global WordDic
WordDic = {}
global ClassFeaProb
ClassFeaProb = {}
global ClassDefaultProb
ClassDefaultProb = {}
global ClassProb
ClassProb = {}
#读入模型
infile = file(ModelFile, 'r')
sline = infile.readline().strip()
#每个文章类型以空格分割开
items = sline.split(' ')
if len(items) < 6:
print "Model format error!"
return
i = 0
while i < len(items):
#获取每类文章的tag
classid = int(items[i])
#定义一个字典
ClassFeaProb[classid] = {}
i += 1
if i >= len(items):
print "Model format error!"
return
#存放先验概率
ClassProb[classid] = float(items[i])
#i+1接下来是默认的条件概率
i += 1
if i >= len(items):
print "Model format error!"
return
ClassDefaultProb[classid] = float(items[i])
i += 1
#循环遍历条件概率的key,key是不同类别的文章classid
for classid in ClassProb.keys():
#接下来读入第二行数据,就是某一类文章的某个词的条件概率
sline = infile.readline().strip()
items = sline.split(' ')
i = 0
while i < len(items):
#获取该词
wid = int(items[i])
#判断在不在词字典里,不在初始化
if wid not in WordDic:
WordDic[wid] = 1
i += 1
if i >= len(items):
print "Model format error!"
return
#并且给当前文章类的该词字典中赋上条件概率
ClassFeaProb[classid][wid] = float(items[i])
#接下来循环第二个词,以此类推
i += 1
infile.close()
print len(ClassProb), "classes!", len(WordDic), "words!"
预测测试集:目的是利用加载后的模型(各类别先验概率、各类别中各单词的条件概率)
若测试文章X={x1,x2,x3,…},则预测其属于哪一类别:yi = {y1,y2,y3}的概率如下
p(yi|X) = p(X|yi)p(yi) = p(x1|yi)p(x2|yi)…p(xn|yi)p(yi),其中p(xi|yi)和p(yi)均是从训练集中计算得来的,具体是判断xi在不在yi对应的单词条件概率字典里,在的话就利用已求得的概率值,不在的话就用默认概率值。预测阶段输出两个列表如下:
获取测试集每篇文章的真实类别集合
TrueLabelList = [classid, classid, classid, …]
获取测试集每篇文章的预测类别集合
PredLabelList = [classid, classid, classid, …]
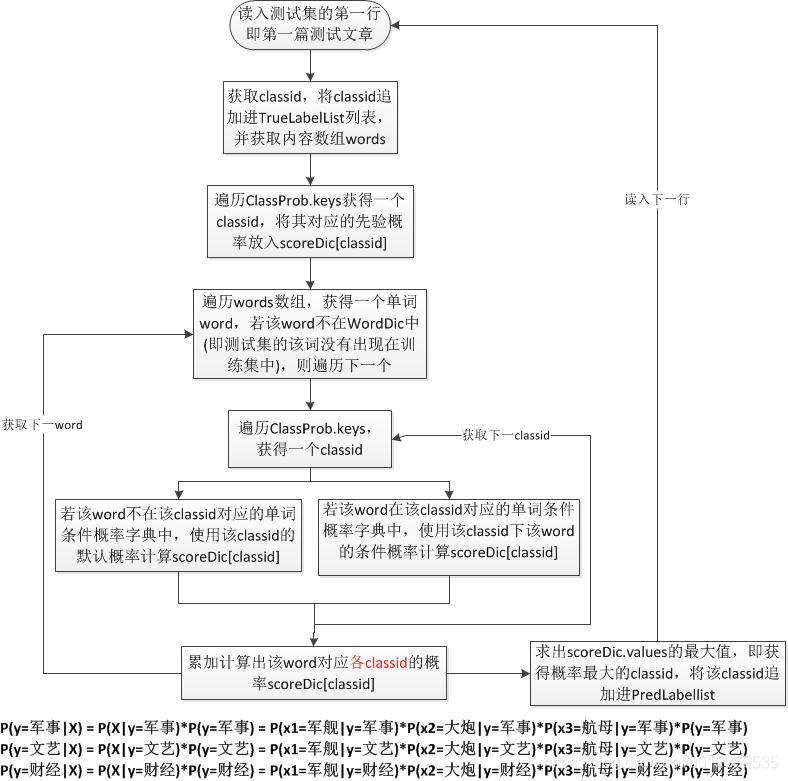
def Predict():
global WordDic
global ClassFeaProb
global ClassDefaultProb
global ClassProb
TrueLabelList = []
PredLabelList = []
i =0
#读入测试集
infile = file(TestDataFile, 'r')
outfile = file(TestOutFile, 'w')
#以每行读入,这里是每篇文章以及文章中的词
sline = infile.readline().strip()
scoreDic = {}
iline = 0
while len(sline) > 0:
iline += 1
if iline % 10 == 0:
print iline," lines finished!\r",
#这块和前面的一样,掠过#后面的文件名称
pos = sline.find("#")
if pos > 0:
sline = sline[:pos].strip()
words = sline.split(' ')
if len(words) < 1:
print "Format error!"
break
classid = int(words[0])
TrueLabelList.append(classid)
#内容从1开始直到最后
words = words[1:]
#remove duplicate words, binary distribution
#words = Dedup(words)
#循环遍历每个类别的先验概率,放入scoreDic字典中
for classid in ClassProb.keys():
scoreDic[classid] = math.log(ClassProb[classid])
for word in words:
if len(word) < 1:
continue
wid = int(word)
#过滤掉一些没有的词
if wid not in WordDic:
#print "OOV word:",wid
continue
for classid in ClassProb.keys():
#判断当前词存不存在条件概率的字典中,若不存在,直接取默认的条件概率,否则取出条件概率
if wid not in ClassFeaProb[classid]:
# 如果当前分类中不包含这个分词,就算出一个默认概率 p(x1|y) +p(x2|y) +p(x3|y) == p(军舰|军事) +p(大炮|军事)
scoreDic[classid] += math.log(ClassDefaultProb[classid])
else:
scoreDic[classid] += math.log(ClassFeaProb[classid][wid])
#binary distribution
#wid = 1
#while wid < len(WordDic)+1:
# if str(wid) in words:
# wid += 1
# continue
# for classid in ClassProb.keys():
# if wid not in ClassFeaProb[classid]:
# scoreDic[classid] += math.log(1-ClassDefaultProb[classid])
# else:
# scoreDic[classid] += math.log(1-ClassFeaProb[classid][wid])
# wid += 1
i += 1
maxProb = max(scoreDic.values())
for classid in scoreDic.keys():
if scoreDic[classid] == maxProb:
PredLabelList.append(classid)
sline = infile.readline().strip()
infile.close()
outfile.close()
print len(PredLabelList),len(TrueLabelList)
return TrueLabelList,PredLabelList