对人脸识别算法进行了一定程度的学习,从最开始的特征脸到如今的CNN人脸检测,有了较为全面的了解。重点掌握了基于PCA的特征脸检测,LDA线性判别分析(Fisher线性判别),以及基于级联器的Haar特征,LBP特征的人脸检测算法,人脸检测的学习主要是基于OpenCV中人脸识别类FaceRecognizer的学习。目前支持的算法有:
Eigenface特征脸 createEigenFaceRecognizer()
Fisherface createFisherFaceRecognizer()
LBP局部二值直方图 createLBPHFaceRecognizer()
1、Eigenface特征脸(掌握PCA数学原理,人脸识别步骤)
特征脸EigenFace:就相当于把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。EigenFace选择的空间变换方法是PCA,也就是大名鼎鼎的主成分分析。EigenFace方法利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行特征值分解,得到对应的特征向量,这些特征向量就是“特征脸”。
1)将训练集的每一个人脸图像都拉长一列,将他们组合在一起形成一个大矩阵A。假设每个人脸图像是MxM大小,那么拉成一列后每个人脸样本的维度就是N=MxM大小了。假设有20个人脸图像,那么样本矩阵A的维度就是20xN了。
2)将所有的20个人脸求每一列的平均值,就得到了一个“平均脸”,这个“平均脸”矩阵E是一个1xN的向量,将这个向量reshape成MxM矩阵,你就可以把这个脸显示出来。
3)将20个图像都减去那个平均脸图像(即矩阵A的每一行减去向量E),得到差值图像的数据矩阵Φ,矩阵Φ的维度也是20xN。
4)计算协方差矩阵 。协方差矩阵C的维度是NxN,(注意:协方差衡量的是不同像素位置间的相关性,并不是图像与图像之间的相关性)再对其进行特征值分解。就可以得到想要的特征向量(1xN)。这些特征向量如果还原成像素排列的话,其实还蛮像人脸的,所以称之为特征脸。我们可以取前40个特征向量,作为特征脸。
5)将训练集图像和测试集的图像都投影到这些特征向量上了,再对测试集的每个图像找到训练集中的最近邻或者k近邻等处理,进行分类即可。
实现步骤:
1、读取训练样本
注意一定要读取灰度图,并且转换成CV_32FC1
2、求特征向量(特征脸)
int number_principal_compent = 10;//保留最大的主成分数(特征向量数)
//构造pca数据结构
PCA pca(database, Mat(), CV_PCA_DATA_AS_ROW, number_principal_compent);
Mat eigenvectors = pca.eigenvectors.clone();3、求出每个训练样本和测试样本在子空间中的投影系数
Mat cv=pca.project(database);//输入database(m个样本)m*n,m张图像,返回cv是一个m*number_principal_compent 的向量
Mat test = pca.project(testimage);//testimage是输入一张人脸图像:1*n,返回test是一个1*number_principal_compent 的向量,每个值代表该输入图像在每个特征脸上投影的系数。
4、计算每个训练样本和测试样本的欧式距离,取其中最小的为识别图片。
vector< double > distance
for (int i = 0;i < cv.rows;i++)
distance[i]=norm(test,cv.row(i));
auto smallest = min_element(begin(distance), end(distance));
cout << "min element is " << *smallest << " at position " << std::distance(std::begin(distance), smallest) << std::endl;
from:https://blog.csdn.net/weixiao2015/article/details/50282153
2、Fisherface
Fisherface方法是主成分分析(PCA)与Fisher线性判别分析(FLD Fisher Linear Discriminant Analysis)相结合的算法。但也可以单独使用Fisher线性判别分析。
LDA:(有监督,使用类别信息)
基本思想是计算出使Fisher准则函数达到极值的向量,并将此向量作为最佳投影方向,样本在该方向上进行投影,投影后的特征向量具有类间离散度最大,类内离散度最小特点。
假设有C个人的人脸图像,每个人可以有多张图像,所以按人来分,可以将图像分为C类,这节就是要解决如何判别这C个类的问题。判别之前需要先处理下图像,将每张图像按照逐行逐列的形式获取像素组成一个向量,设该向量为x,维数为n,x为列向量(n行1列)
我们需要增加投影向量w的个数(当然每个向量维数和数据是相同的,),设w为:
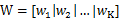
w1、w2等是n维的列向量,所以w是个n行k列的矩阵,这里的k其实可以按照需要随意选取,只要能合理表征原数据就好。x在w上的投影可以表示为: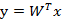
进行人脸识别时,将人脸向量投影到LDA子空间w,得到一个低维向量 : ,其中
在一个人脸集合上求得k=C-1个特征向量,如何匹配某人脸和数据库内人脸是否相似呢,方法是将这个人脸在k个特征向量上做投影,得到k维的列向量或者行向量,然后和已有的投影求得欧式距离,根据阈值来判断是否匹配。
具体步骤:
1、初始LDA对象,并根据输入样本计算最佳投影向量,即LDA子空间
LDA(const Mat& src, vector<int> labels,int num_components = 0):_num_components(num_components)
{
this->compute(src, labels); //! compute eigenvectors and eigenvalues
} 参数num_components=0采用默认,由给定数据label的类别自动判决,如果类别为C,则默认值是C-1
2、LDA::project,将样本投影到到LDA子空间
Mat LDA::project(InputArray src) {
return subspaceProject(_eigenvectors, Mat(), _dataAsRow ? src : src.getMat().t());
} 数据的处理:
1、循环读入训练图像Mat,并将Mat对象存储到vector<Mat>容器中,同时新建一个Mat对象,或行矢量或列矢量来存储类别标签。
2、将步骤1中的数据传入到LDA的构造函数中,构造函数进行计算处理,从而获得特征矢量。
3、将训练数据利用project函数,投影到特征矢量构造的子空间,即LDA子空间,得到结果。
4、利用project函数,将测试图像投影到LDA子空间,保存返回的Mat矢量,与训练数据得到的结果进行欧式距离比较,距离最小即为识别的人脸。
总结:PCA是为了去除原始数据集中冗余的维度,让投影子空间的各个维度的方差尽可能大,也就是熵尽可能大。LDA是通过数据降维找到那些具有discriminative的维度,使得原始数据在这些维度上的投影,不同类别尽可能区分开来。
LDA+PCA
原始样本采用了200*200大小的图片,形成了40000维的特征矢量,其中包含了大量冗余信息和噪声,导致了LDA方法的不准确。因此一般先采用PCA降维:首先对原始样本图像进行PCA降维,而后再使用LDA进行分类训练;在进行测试时,也先对原始图像进行PCA降维,再利用LDA进行识别,这样可以有效消除冗余信息和噪声的干扰,压缩后的信息对脸部位置也变得不敏感。
转换矩阵,可以将样本投影到c-1维空间,其中c表示类别。
投影公式为:
表示LDA的特征矢量构成的,
表示PCA的特征矢量构成的,u是PCA分析中所有样本的均值。z列向量的维数为类别数目-1.注意:这里x是n*1列向量,
是 n*(样本数−类别数)矩阵,
得到(样本数−类别数)*1的列向量,实际上就是压缩后的人脸图像temp,
(
,这里的
是在pca降维后的人脸图像上求得的投影向量,矩阵尺寸为(样本数−类别数)*(类别数-1)
from:https://blog.csdn.net/zdyueguanyun/article/details/8595549
除了特征脸和Fisher线性判别外,人脸检测与识别有三个常用特征,分别是Haar,HOG,LBP。
Haar
Haar特征其实就是一组特征模板,模板由黑白两区域组成,每个模板代表一种Haar特征,用这些模板在图像上进行滑动,皆可以求出图像每个像素的不同种Haar特征响应,特征响应相当于模板与图像进行卷积,每个特征由白方块下的像素和减去黑方块的像素和来得到。 为了加速计算一般采用在积分图(掌握积分图计算)上进行求解
HOG
HOG特征的提取过程:
1、Gamma归一化: 对图像颜色进行Gamma归一化处理,降低局部阴影及背景因素的影响.
2、计算梯度:通过差分计算出图像在水平方向上及垂直方向上的梯度,然后得到各个像素点的梯度的幅值及方向
3、划分cell
将整个图像窗口划分成大小相同互不重叠的细胞单元cell(如8×8像素),计算出每个cell的梯度大小及方向.然后将每像素的梯度方向在0−180(无向:0-180,有向:0-360)平均分为9个bins,统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor.
4、组合成block,统计block直方图
将2×2个相邻的cell组成大小为16×16的像素块即block.依次将block大小的滑动框在整个图像窗口内,从左到右从上到下滑动,求其梯度方向直方图向量,一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
对于64*128的图像而言,每8*8的像素组成一个cell,每2*2个cell组成一个block(16×16像素),因为每个cell有9个特征,所以每个block内有4*9=36个特征,以8个像素为步长,那么,水平方向将有7个扫描窗口(block),垂直方向将有15个扫描窗口(block),这样检测窗口block的数量有((128-16)/8+1)×((64-16)/8+1)=15×7。也就是说,64*128的图片,总共有36*7*15=3780个特征。
HOG在行人检测和这里的检测中,一个是级联adaboost,另一个是SVM进行判别。
LBP
人脸特征还可以LBP直方图向量进行表达。在图像的每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(每个像素点的LBP值)。然后将一幅图片划分为若干的子区域,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了,LBP即可以用于人脸检测,也可用于人脸识别。更多适用于检测,识别精度可能不高。
在OpenCV级联分类器检测类CascadeClassifier中,使用Adaboost的方法+LBP、HOG、HAAR进行目标检测。
Cascade器是通过将多个强分类器串联在一起,当样本满足所有分类器时,才能判别该样本是人脸,好处是:比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20约等于98%,错误接受率也仅为0.5^20约等于0.0001%。这样的效果就可以满足现实的需要了。
强分类器的获取通过adaboost提升算法获得,强分类器是由多个弱分类器“并列”构成,即强分类器中的弱分类器是两两相互独立的。在检测目标时,每个弱分类器独立运行并输出,然后把当前强分类器中每一个弱分类器的输出值相加,这里的弱分类器其实就是Haar特征判别,CART树,仅有一个树桩节点(单个特征)。
如果直接利AdaBoost训练,那么工作量是极其极其巨大的,因为Haar特征太多。所以必须有个筛选的过程,筛选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost进行训练。
弱分类器的选取过程: 对于每个特征 f,为该特征弱分类器选择使分类误差最小的阈值(最优阈值),此时我们的第一个最优弱分类器就诞生了,依次训练我么会得到每个特征的最优弱分类器。
然后从这些最优弱分类器中挑选最好的T个分类器,分别送入多个Adaboost中进行训练。最终得到多个Adaboost强分类器(意思是:我们把选出的T个分类器分为10组,然后对每组的分类器分别进行Adaboost训练,这样最终我们会得到10个强分类器),最后将这些强分类器进行级联。