文献:How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
(a)结合最先进的人脸特征点定位(landmark localization)架构和最先进的残差模块(residual block),我们首次构建了一个非常强大的基准,在一个非常大的2D人脸特征点数据集(facial landmark dataset)上训练,并在所有其他人脸特征点数据集上进行评估。
(b)我们创建了一个将2D特征点标注转换为3D,并统一所有现有的数据集,从而创建了迄今最大、最具有挑战性的3D人脸特征点数据集LS3D-W(约230000张图像)。
(c)然后,我们训练一个神经网络来进行3D人脸对齐(face alignment),并在新的LS3D-W数据集上进行评估。
(d)我们进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态( large pose),初始化和分辨率,并引入一个“新的”因素,即网络的大小。
(e)我们的研究显示2D和3D人脸对齐网络都实现了非常高的性能,这很可能接近所使用的数据集的饱和性能。
训练和测试代码以及数据集可以从https://www.adrianbulat.com/face-alignment/ 下载。
使用卷积神经网络进行特征点定位。
基于热图回归的全卷积神经网络体系结构。
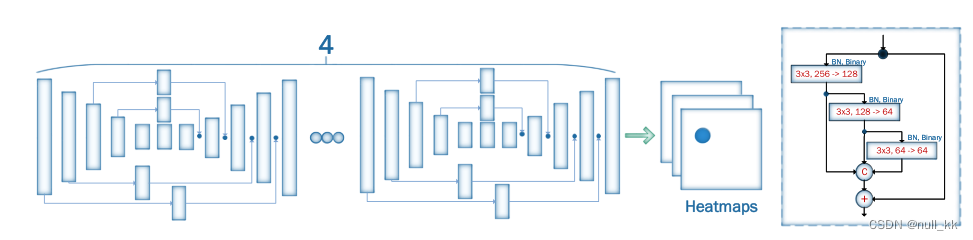
四个HGs堆叠而成的Face Alignment Network (FAN)
构建和训练这样一个强大的面部对齐网络,并首次研究它距离在所有现有的2D面部对齐数据集和新引入的大型3D数据集上达到接近饱和的性能还有多远。
工作:
- 我们通过结合最先进的地标定位体系结构和最先进的残留块,首次构建了一个非常强的基线,并在一个非常大的但综合扩展的2D面部地标数据集上训练它。然后,我们在所有其他2D数据集(约23万张图像)上评估它,研究我们距离解决2D人脸对齐问题还有多远。
- 为了克服3D人脸对齐数据集的稀缺,我们进一步提出了一个2D地标引导CNN,它将2D注释转换为3D,并使用它创建LS3D-W,这是迄今为止最大和最具挑战性的3D人脸地标数据集(约23万张图像),该数据集几乎统一了迄今为止所有现有的数据集。
- 然后,我们训练一个3D人脸对齐网络,然后在新引入的大规模3D人脸地标数据集上对其进行评估,研究我们距离解决3D人脸对齐问题还有多远。
- 我们进一步研究了影响人脸对齐性能的所有“传统”因素,如大姿势、初始化和分辨率的影响,并引入了一个“新的”因素,即网络的大小。
- 2D和3D人脸对齐网络都实现了显著的准确性,这可能接近饱和所使用的数据集。
人脸对齐和特征点定位的相关工作:
2D面部对齐:深度学习之前,级联回归是二维人脸对齐的最先进方法。
CNN用于面部对齐:使用CNN级联回归面部特征点定位。3D变形模型(3DMM)拟合到2D面部图像来执行面部对齐。
转移地标注释:通过转移地标注释来统一面部对齐数据集,通常是通过开发跨数据集的公共地标。
数据集
3D注释实际上是3D面部地标坐标的2D投影
训练数据集
300-W是目前最广泛使用的野外数据集,用于2D人脸对齐。
300-W- lp是一个综合生成的数据集。
2D数据集
300-W test set
300-VW(半自动标注法,导致视频标注不准确。)
Menpo
3D数据集
AFLW2000-3D
度量:人脸对齐的度量是由眼间距离归一化的点对点欧氏距离。
归一化平均误差
方法:
2D-to-3D FAN网络,用于构建包含超过23万个3D地标注释的超大规模3D人脸对齐数据集(LS3D-W)。
沙漏(HG)网络构建了FAN。特别地,我们使用了四个HG网络的堆栈。使用的瓶颈块作为HG的主要构建块,我们更进一步,用最近引入的分级、并行和多尺度块取代瓶颈块。当使用相同数量的网络参数时,该块的性能优于的原始瓶颈。
2D-to-3D FAN网络:
预测3D地标的FAN由2D地标引导。创建一个3D-FAN,其中输入RGB通道增加了68个额外通道,每个2D地标一个通道,包含一个2D高斯,std = 1px以每个地标的位置为中心。
训练模型:初始学习率设置;随机增强(翻转、旋转、颜色抖动、尺度噪声、随机遮挡)
2D人脸对齐
2D-FAN在所有数据集上实现了几乎相同的性能,优于MDM和ICCR,值得注意的是,与lfpw上的MDM的性能相当。
结论:考虑到2D- fan与MDM-on-LFPW的性能相匹配,我们得出结论,2D- fan在上述二维数据集上达到了接近饱和的性能。值得注意的是,该结果主要是通过对合成数据进行2D-FAN训练获得的,并且在训练和测试地标注释之间存在不匹配。
大规模3D面部野外数据集
由于3D人脸对齐标注的稀缺性和2D- fan的卓越性能,我们选择通过将所有现有的2D人脸对齐标注转换为3D来创建一个大规模的3D人脸对齐数据集。
3D面部对齐
3D-FAN使用了更多的大姿态图像。
3D-FAN在所有数据集上基本上产生相同的准确性,远远优于3DDFA。
消融实验
(设置对照组,通过去除某个模块的作用,来证明该模块的必要性,如果消融实验后得到结果不好或者性能大幅下降,说明该模块起到了作用。)
偏摆角度数据集LS3D-W Balanced。
跨姿势表演:面部姿势不是3D-FAN的主要问题。
跨分辨率性能:分辨率不是3D-FAN的主要问题。
跨噪声初始化性能:初始化不是3D-FAN的主要问题。
跨不同网络规模的性能:3D-FAN的性能随参数数量的增加有一定的下降。
结论
我们的网络几乎饱和了这些数据集,在姿态、分辨率、初始化,甚至使用的网络参数数量方面也显示出了显著的弹性。
(1)半自动标注法
参考文献:The first facial landmark tracking in-the-wild challenge: Benchmark and results.
半自动标注过程:首先将通用的人脸和地标定位方案应用于视频,然后将通用的可变形人脸检测器转换为特定于人的检测器并重新应用于视频。
首先需要准备训练数据,然后将每一类的数据抽取一小部分进行人工标注,标注完后投入进我们准备好的基模型中进行训练,训练得出结果后,在labelimg中打开进行人工纠正,接着从未标注数据中选出一部分数据和我们上述得到的数据一起重新投入到模型中继续训练,反复重复此过程,直到精度达到我们心里所期望的一个阈值之后,就把剩余数据和我们得到标注结果的数据都投入到模型中一起训练,最后再进行人工纠正即可。
参考:智能标注-半自动化标注实现
(2)基于沙漏网络构建FAN。
参考文献:Stacked hourglass networks for human pose estimation.
基于我们对用于获得网络最终输出的汇集和后续上采样步骤的可视化,我们将设计称为沙漏。
沙漏的设置如下:卷积和最大池化层用于处理分辨率很低的特征。在每个最大池化步骤,网络分支并以原始预池化分辨率应用更多卷积。在达到最低分辨率后,网络开始自上而下的上采样序列,并跨尺度组合特征。
(3)MDM(记忆下降法)该方法使用ground truth边界框初始化。
参考文献:Mnemonic descent method: A recurrent process applied for end-to-end face alignment.
MDM将可变形的面部对齐建模为非线性动态系统,MDM维护一个内部存储单元,用于累积从输入空间的所有过去观察的历史中提取的信息。
端到端的面部对齐方法,该方法使用卷积神经网络(CNN)直接从图像中以级联方式学习一组数据驱动的特征,最重要的是使用递归神经网络(RNN)对下降方向施加记忆约束。
SDM是第一个将级联回归问题描述为一个更通用的学习框架的工作,该框架利用从训练数据中学习的下降方向来优化非线性目标函数。
记忆下降法(MDM),这是一种用于非线性函数下降方向的端到端学习的非线性统一模型。与现有的级联回归框架相比,MDM能够通过在下降方向学习中引入记忆的概念来建模级联迭代之间的依赖关系。
- 特征提取
用卷积网络模块代替特征提取阶段,该卷积网络模块有助于学习导致函数最优的定向滤波器。由于训练是通过反向传播以端到端的方式执行的,因此我们本质上学习用于与拟合过程联合卷积图像块的滤波器。 - 模型
MDM的主要动机是通过将先前独立的级联步骤基本上视为非线性动力学系统下的时间步骤(即,对迭代的依赖性进行建模)来促进平滑收敛。使用RNN(递归神经网络)来实现MDM。RNN有助于反馈连接,从而在网络内生成环路和循环。这使得递归网络能够考虑数据中出现的时间依赖性。就MDM而言,这实现了迭代之间的建模依赖性,从而实现了下降方向。 - 面部对齐的端到端训练
给定对应于平均面部形状的初始估计x(0),提取一组补丁并通过卷积模块fc(·;x(0,θc)传播,以获得适当的非线性特征表示。然后,递归模块fr(·;h(0),θr)生成下一个状态h(1),并在固定的时间步长内重复该过程。
人脸关键点检测的评测指标主要是两种,NME(Normalized Mean Error)和 AUC(Area Under Curve)。
归一化平均误差&&曲线下面积