数据的特征处理
相关视频讲解:待网站审核
数据:https://download.csdn.net/download/yiyongzhifu/11142350
Kaggle上有这样一个比赛:城市自行车共享系统使用状况。
提供的数据为2年内按小时做的自行车租赁数据,其中训练集由每个月的前19天组成,测试集由20号之后的时间组成。
#先把数据读进来
import pandas as pd
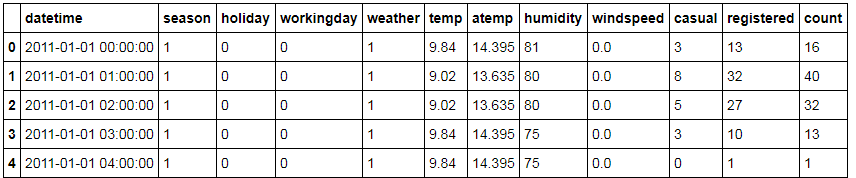
data = pd.read_csv('kaggle_bike_competition_train.csv', header = 0, error_bad_lines=False)
#看一眼数据长什么样
data.head()
# 处理时间字段
temp = pd.DatetimeIndex(data['datetime'])
data['date'] = temp.date
data['time'] = temp.time
data.head()
# 设定hour这个小时字段
data['hour'] = pd.to_datetime(data.time, format="%H:%M:%S")
data['hour'] = pd.Index(data['hour']).hour
data
# 我们对时间类的特征做处理,产出一个星期几的类别型变量
data['dayofweek'] = pd.DatetimeIndex(data.date).dayofweek
# 对时间类特征处理,产出一个时间长度变量
data['dateDays'] = (data.date - data.date[0]).astype('timedelta64[D]')
data
byday = data.groupby('dayofweek')
# 统计下没注册的用户租赁情况
byday['casual'].sum().reset_index()
# 统计下注册的用户的租赁情况
byday['registered'].sum().reset_index()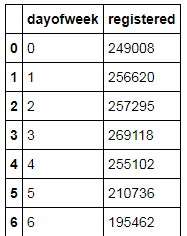
data['Saturday']=0
data.Saturday[data.dayofweek==5]=1
data['Sunday']=0
data.Sunday[data.dayofweek==6]=1
data# remove old data features
dataRel = data.drop(['datetime', 'count','date','time','dayofweek'], axis=1)
dataRel.head()
### 特征向量化
我们这里打算用scikit-learn来建模。对于pandas的dataframe我们有方法/函数可以直接转成python中的dict。
另外,在这里我们要对离散值和连续值特征区分一下了,以便之后分开做不同的特征处理。
扫描二维码关注公众号,回复:
6102479 查看本文章

from sklearn.feature_extraction import DictVectorizer
# 我们把连续值的属性放入一个dict中
featureConCols = ['temp','atemp','humidity','windspeed','dateDays','hour']
dataFeatureCon = dataRel[featureConCols]
dataFeatureCon = dataFeatureCon.fillna( 'NA' ) #in case I missed any
X_dictCon = dataFeatureCon.T.to_dict().values()
# 把离散值的属性放到另外一个dict中
featureCatCols = ['season','holiday','workingday','weather','Saturday', 'Sunday']
dataFeatureCat = dataRel[featureCatCols]
dataFeatureCat = dataFeatureCat.fillna( 'NA' ) #in case I missed any
X_dictCat = dataFeatureCat.T.to_dict().values()
# 向量化特征
vec = DictVectorizer(sparse = False)
X_vec_cat = vec.fit_transform(X_dictCat)
X_vec_con = vec.fit_transform(X_dictCon)dataFeatureCon.head()
X_vec_conarray([[ 14.395 , 0. , 0. , 81. , 9.84 , 0. ],
[ 13.635 , 0. , 1. , 80. , 9.02 , 0. ],
[ 13.635 , 0. , 2. , 80. , 9.02 , 0. ],
...,
[ 15.91 , 718. , 21. , 61. , 13.94 , 15.0013],
[ 17.425 , 718. , 22. , 61. , 13.94 , 6.0032],
[ 16.665 , 718. , 23. , 66. , 13.12 , 8.9981]])dataFeatureCat.head()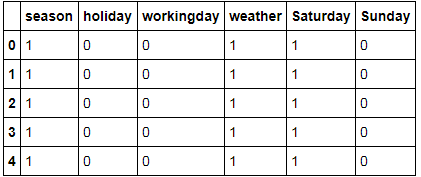
X_vec_catarray([[ 1., 0., 0., 1., 1., 0.],
[ 1., 0., 0., 1., 1., 0.],
[ 1., 0., 0., 1., 1., 0.],
...,
[ 0., 0., 0., 4., 1., 1.],
[ 0., 0., 0., 4., 1., 1.],
[ 0., 0., 0., 4., 1., 1.]])### 标准化连续值特征
我们要对连续值属性做一些处理,最基本的当然是标准化,让连续值属性处理过后均值为0,方差为1。
这样的数据放到模型里,对模型训练的收敛和模型的准确性都有好处
from sklearn import preprocessing
# 标准化连续值数据
scaler = preprocessing.StandardScaler().fit(X_vec_con)
X_vec_con = scaler.transform(X_vec_con)
X_vec_conarray([[-1.09273697, -1.70912256, -1.66894356, 0.99321305, -1.33366069,
-1.56775367],
[-1.18242083, -1.70912256, -1.52434128, 0.94124921, -1.43890721,
-1.56775367],
[-1.18242083, -1.70912256, -1.379739 , 0.94124921, -1.43890721,
-1.56775367],
...,
[-0.91395927, 1.70183906, 1.36770431, -0.04606385, -0.80742813,
0.26970368],
[-0.73518157, 1.70183906, 1.51230659, -0.04606385, -0.80742813,
-0.83244247],
[-0.82486544, 1.70183906, 1.65690887, 0.21375537, -0.91267464,
-0.46560752]])### 类别特征编码
最常用的当然是one-hot编码咯,比如颜色 红、蓝、黄 会被编码为[1, 0, 0],[0, 1, 0],[0, 0, 1]
from sklearn import preprocessing
# one-hot编码
enc = preprocessing.OneHotEncoder()
enc.fit(X_vec_cat)
X_vec_cat = enc.transform(X_vec_cat).toarray()
X_vec_catarray([[ 1., 0., 0., ..., 1., 1., 0.],
[ 1., 0., 0., ..., 1., 1., 0.],
[ 1., 0., 0., ..., 1., 1., 0.],
...,
[ 0., 1., 1., ..., 0., 0., 1.],
[ 0., 1., 1., ..., 0., 0., 1.],
[ 0., 1., 1., ..., 0., 0., 1.]])### 把特征拼一起
把离散和连续的特征都组合在一起
import numpy as np
# combine cat & con features
X_vec = np.concatenate((X_vec_con,X_vec_cat), axis=1)
X_vecarray([[-1.09273697, -1.70912256, -1.66894356, ..., 1. ,
1. , 0. ],
[-1.18242083, -1.70912256, -1.52434128, ..., 1. ,
1. , 0. ],
[-1.18242083, -1.70912256, -1.379739 , ..., 1. ,
1. , 0. ],
...,
[-0.91395927, 1.70183906, 1.36770431, ..., 0. ,
0. , 1. ],
[-0.73518157, 1.70183906, 1.51230659, ..., 0. ,
0. , 1. ],
[-0.82486544, 1.70183906, 1.65690887, ..., 0. ,
0. , 1. ]])最后的特征,前6列是标准化过后的连续值特征,后面是编码后的离散值特征
### 对结果值也处理一下
拿到结果的浮点数值
# 对Y向量化
Y_vec_reg = dataRel['registered'].values.astype(float)
Y_vec_cas = dataRel['casual'].values.astype(float)Y_vec_regarray([ 13., 32., 27., ..., 164., 117., 84.])Y_vec_casarray([ 3., 8., 5., ..., 4., 12., 4.])