数据预处理2–特征处理
首先进行特征处理是非常必要的,那么什么是特征处理?
特征工程是通过对原始数据处理和加工,将原始数据的属性转换为数据特征的过程。特征工程涵盖很多方面,其中较重要的部分是特征处理和特征选择。
特征处理通常包含以下四种:
特征缩放
数值离散化
特征编码
时间数值转换
一、特征缩放
1.进行特征缩放的必要性:
在实际业务中,当数据的量纲不同,数量级别差距大时,会影响最终的数据模型,因此需用特征缩放来平衡各特征贡献。
特征缩放可提高模型精度和模型收敛速度。它是数据预处理的重要环节之一。特征缩放又叫数据归一化。
2.方法:
2.1标准化 (Standardization):
标准化是将训练集中的某一列 (特征) 缩放成均值为0,方差为1的状态。对特征向量进行缩放是无意义的,比如对班级、年龄、性别一组特征向量 (行) 进行标准化操作是无价值的。标准化要求原始数据近似满足高斯分布,数据越接近高斯分布,标准化效果越佳。

特点:
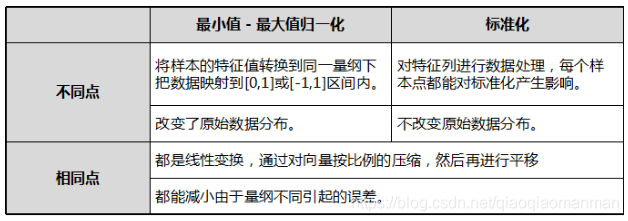
标准化后使得不同度量的数据特征具有可比性,同时不改变数据的原始分布状态。
标准化对数据进行规范化处理,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
2.2最小值-最大值归一化 (Min-Max Normalization)
将训练集中某一列特征数值缩放到0到1或-1到1之间。

特点:
受训练集中最大值和最小值影响大,存在数据集中最大值与最小值动态变化的可能。
容易受噪声(异常点、离群点)影响。
2.3均值归一化 (Mean Normalization)
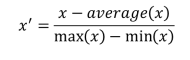
x是原始数据。
2.4缩放成单位向量 (Scaling to Unit Length)

3.标准化和最小值-最大值的区别和联系:
4.应用场景:
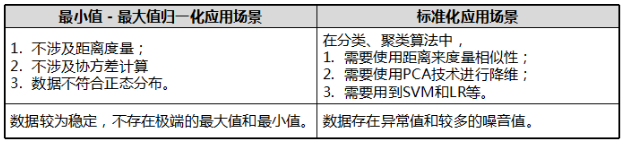
不要在整个数据集上做归一化处理,要区分训练集和测试集;
注意:这一点在之前的数据挖掘的笔记里也提到过,要将数据集分成训练和测试,而不是将整个数据集进行处理!
在实际应用中,特征缩放的标准化操作更常用。
二、数值离散化
什么是数值离散化?
把无限空间中有限的个体映射到有限的空间中去,以提高算法的时空效率。换句话说,在不改变数据相对大小的情况下,对数据进行相应缩小。
注意:离散化仅适用于只关注元素之间的大小关系而不关注元素数值本身的情况。

1.应用:
数值离散化在数据预处理中发挥重要作用。离散化可以降低特征中的噪声节点,提升特征的表达能力。但在实际应用中要根据不同环境和不同数据,选择合适的数值离散化方法。
2.必要性:
在数据挖掘理论研究中,数值离散化对数据预处理影响重大。研究表明离散化数值在提高建模速度和提高模型精度上有显著作用。
比如,对于决策树来说,离散化数据可以加快数据建模的速度,拥有更高的模型精度;离散化数值后,简化了逻辑回归,降低了数据过拟合的风险。
数值离散化实际是一个数据简化机制。因为通过数值离散化过程,一个完整的数据集变成一个个按照某种规则分类的子集,增强了模型的稳定性。
比如,30-40为一个年龄区间,标记为Mature。这样就可以避免从30岁到31岁就变成了另一类群体人员。
离散化后的特征对异常数据有很强的鲁棒性。能减少噪音节点对数据的影响。
比如,如果规定满分值中成绩大于80分为A,小于80分为B,则出现异常值120会被标记为A,减低了异常值对模型的干扰。
某些算法只能处理离散化数据,但即使模型可以处理连续型数据,其综合学习效率和模型精度也要稍逊色于离散化数据。
值得注意的是,任何离散化过程都会带来一定的信息丢失,因此寻求最小化信息丢失是使用数值离散化技术人员的核心目标之一。
3.连续变量的离散化:
连续变量的离散化分为有监督和无监督两类。
连续变量的离散化过程分为四个核心步骤:
3.1Sorting: 对连续型变量进行排序,为离散化做准备:
对连续型变量升序或降序。尽量选择时间复杂度低的排序算法。
3.2Evaluating: 对Splitting来说评估分割点(自顶向下),对Merging来说评估合并点(自底向上):
排序完成后,要选择较佳的分割点或合并点。自顶向下是划分间隔,自底向上是合并间隔。
评估较佳分割点或合并点的策略是评价函数,比如,熵测量、均方根误差 (RMSE)、平均绝对百分误差 (MAPE)等 (详细信息后续课程讲解),以此判断分割或合并后的模型的Performance是否提升,提升保留,否则舍弃。
3.3Splitting or Merging: 分割或合并区间:
确定了较佳分割点或合并点后,开始对连续数据集进行分割或合并。
对于Splitting来说,针对每个属性,选择最好的分割点将数据分割成两部分。
对于Merging来说,针对每个属性,选择最好的合并点进行间隔合并。
分割或合并之后需重复步骤二和步骤三,多次迭代继续分割或合并。
3.4Stopping: 达到停止条件,停止离散化:
当到达停止条件后,停止整个离散化过程。停止条件没有唯一绝对情况。通常,它由一致性、好的解释性和较少的数据间隔共同决定。
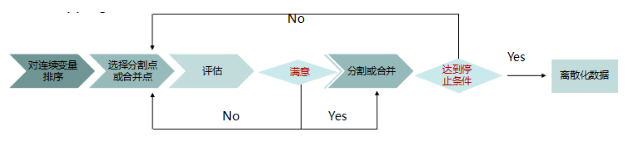
4.两种学习方法:
4.1无监督学习方法:
4.1.1聚类划分:
使用聚类算法将数据分为K类,需要制定K值大小。把同属一类的数值标记为相同标签
4.1.2分箱–等宽划分:
把连续变量按照相同的区间间隔划分几等份。换句话说,根据连续变量的最大值和最小值,划分N份,每份数值间隔相同。
划分区间间隔interval=(Max(x)-Min(x))/N。
4.1.3分箱–等频划分:
把连续变量划分几等份,保证每份的数值个数相同。具体来说,假设共有M个数值,划分N份,每份包含(M/N)个数值。划分个数count = M/N。
4.2有监督学习方法:
4.2.1分箱法–1R:
有监督的分箱方法。把连续的区间分成小区间,然后根据类标签对区间内变量调整。每个区间至少包含6个变量(最后一个区间除外)。
步骤:
从第一个变量开始,将前N个变量纳入第一个区间。N一般取6。
若第七个变量的类别标签与第一个区间内的大多数变量的类别标签相同,则把第七个变量纳入第一个区间,然后按此方法继续判断第八个变量。
若第七个实例的类别标签与第一个区间内的大多数变量的类别标签不相同,则从第七个实例开始纳入六个变量,建立第二区间。
然后对后续变量按照相同的方法判断是否属于第二区间,直至结束。
最终根据每个区间中的大多数变量的共同标签决定这个区间的标签。
通过此流程,对各区间添加标签后,可能会出现相邻区间类别标签相同的情况,此时合并相邻区间。
4.2.2基于信息熵的方法 :
自顶向下的方法,运用决策树的理念进行变量离散化。
步骤:
计算数据集中每个变量的熵,选择熵值最小的点作为端点,将数据集一分为二。再利用递归的方式继续对每个小区间的数值一分为二。直到满足停止条件。
停止条件有:每个区间实例小于14个等等。
根据最小描述长度准则 (MDLP) 衡量哪些是符合要求的端点,哪些不是。对不符合要求的端点进行合并。
4.2.3基于卡方的方法:
自底向上的方法,运用卡方检验的策略,自底向上合并数值进行有监督离散化,核心操作是Merge。
将数据集里的数值当做单独区间,递归找出可合并的最佳临近区间。判断可合并区间用到卡方统计量来检测两个区间的相关性,对符合所设定阀值的区间进行合并。
三、特征编码:
数据挖掘中,一些算法可以直接计算分类变量,比如决策树模型。但许多机器学习算法不能直接处理分类变量,它们的输入和输出都是数值型数据。因此,把分类变量转换成数值型数据是必要的,可以用独热编码 (One-Hot Encoding) 和哑编码 (Dummy Encoding)实现。
比较常用的是对逻辑回归中的连续变量做离散化处理,然后对离散特征进行独热编码 (One-Hot Encoding) 或哑编码 (Dummy Encoding),这样会使模型具有较强的非线性能力。
1.无序分类变量的离散化方法较为常用方法,如下:
独热编码 (One-Hot Encoding):
使用M位状态寄存器对M个状态进行编码,每个状态都有独立的寄存器位,这些特征互斥,所以在任意时候只有一位有效。也就是说,这M种状态中只有一个状态位值为1,其他状态位都是0。换句话说,M个变量用M维表示,每个维度的数值或为1,或为0。
哑编码 (Dummy Encoding):
哑编码和独热编码很相似,唯一的区别在于哑编码使用M-1位状态寄存器对M个状态进行编码
2.有序分类变量的离散化方法:
Label-Encoding:
有序分类变量数值之间存在一定的顺序关系,可直接使用划分后的数值进行数据建模。
如分类变量{低年级,中年级,高年级},可以直接离散化为{0,1,2}。
3.这三种方法的对比:

4.如何用python实现独热编码
想要用代码实现独热编码有两个步骤:
导入实验数据集。
使用OneHotEncoder ( )函数计算出独热编码。
代码如下:
# 导入数据集iris
from sklearn.datasets import load_iris
iris=load_iris()
# 导入OneHotEncoder类
from sklearn.preprocessing import OneHotEncoder
# 指定sparse = False,避免输出的是稀疏的存储格式,即索引加值的形式
enc = OneHotEncoder(sparse = False)
# 对鸢尾花数据集进行独热编码操作
x = enc.fit_transform(iris.data)
# 输出结果
x
array([[0., 1., 0., ..., 1., 0., 0.],
[1., 0., 0., ..., 1., 0., 0.],
[1., 0., 0., ..., 1., 0., 0.],
...,
[0., 0., 1., ..., 0., 0., 1.],
[0., 0., 1., ..., 0., 0., 1.],
[0., 1., 0., ..., 0., 1., 0.]])
四、时间数值转换:
在实际业务中,时间数据是经常用到的数据信息。在数据预处理中可能存在
日期格式 - 字符串格式 - 数值格式之间的相互转换。
Python中常用的datetime模块解决大多数日期和时间的处理问题。若需解决更复杂的时间问题,比如:日期计算,可用dateutil模块。
1.日期格式 – 字符串格式
>from datetime import datetime
#获取当前时间
>today = datetime.today()
#日期格式
>print(today)
Out:2018-12-18 11:23:34.908293
#转换成字符串格式
>today.strftime('%Y-%m-%d')
Out:'2018-12-18'
>today.strftime('%Y%m%d')
Out:'20181218'
2.字符串格式 – 日期格式
#datetime字符串转日期
>datetime.strptime('2018-12-18','%Y-%m-%d')
Out:datetime.datetime(2018, 12, 18, 0, 0)
#pandas字符串转日期
>import pandas as pd
>pd.to_datetime('2018-12-18')
Out:Timestamp('2018-12-18 00:00:00')
3.数值格式 – 日期格式
#定义数值日期
>today = 20181218
#数值格式转日期格式
>datetime.strptime(str(today),'%Y%m%d')
Out:datetime.datetime(2018, 12, 18, 0, 0)
