什么是凸集、凸函数、凸学习问题?
凸集:若对集合C中任意两点u和v,连接他们的线段仍在集合C中,那么集合C是凸集。
公式表示为:αu+(1-α)v∈C α∈[0, 1]
凸函数:凸集上的函数是凸函数。凸函数的每一个局部极小值也是全局极小值( f(x) = 0.5x^2 )。
公式表示为:f(αu + (1-α)v) ≤ αf(u)+ (1-α)f(v)
无监督学习方法有哪些?
强化学习、K-means 聚类、自编码、受限波尔兹曼机
简述回归,分类,聚类方法的区别和联系并分别举出一个例子,简要介绍算法思路
回归:
对连续随机变量建模预测的监督学习算法;
经典案例:房价预测;
算法举例:线性回归,建立数据的拟合曲线作为预测模型(y = wx + b);
分类:
对离散随机变量建模预测的监督学习算法;
经典案例:垃圾邮件分类;
算法举例:支持向量机,寻找二类支持向量的最大切分超平面;
聚类:
基于数据的内部规律,寻找其属于不同族群的无监督学习算法;
算法举例:k-means;
逻辑回归和SVM的区别和联系
1.损失函数不同,LR损失函数是对数损失;SVM损失函数时合页损失;
2.LR考虑了所有点的损失,但通过非线性操作大大减小离超平面较远点的权重;SVM仅考虑支持向量的损失
3.LR受类别平衡的影响;SVM则不受类别平衡的影响;
4.LR适合较大数据集;SVM适合较小数据集
从变换矩阵和变换效果等方面阐述相似变换、仿射变换、投影变换的区别。
等距变换:图像旋转+平移
相似变换:图像旋转+平移+缩放(放大或缩小原图)
仿射变换:图像旋转+平移+缩放+切变(虽改变图像的形状,但未改变图像中的平行线)
投影变换:图像旋转+平移+缩放+切变+射影(不仅改变了图像的形状,而且改变了图像中的平行线)
Bagging和Boosting之间的区别?
1.从样本选择角度:
Bagging采用随机有放回的采样方式(Boostraping);Boosting使用所有样本,但每个样本的权重不同;
2.从决策方式角度:
Bagging分类预测采用大多数投票选举法,回归预测采用各基分类器预测结果的平均值;Boosting采用各基分类器在不同权重作用下预测结果的累加和;
3.从方差、偏差角度:
Bagging以减小方差为目的;Boosting以减少偏差为目的; 模型过拟合,则方差大,Bagging以随机采样样本的方式减少异常样本的选择比例,从而可以降低过拟合,随之也就减小了方差; Boosting的损失函数就是以减少偏差为目的来训练下一个基分类器;
4.从权重角度:
Bagging各个样本的权重相同,各个基分类器权重相同;Boosting各个样本的权重不同,正确预测的样本权重减小,错误预测的样本权重增大;各个基分类器的权重不同,预测准确率高的权重大,预测准确率低的权重小;
生成模型和判别模型
生成方法是首先基于数据学习联合概率分布P(X,Y),然后获得条件概率分布P(Y|X)作为预测模型。
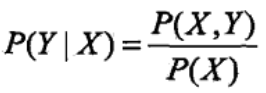
常用模型:隐马尔可夫模型(HMM)、朴素贝叶斯
判别方法是直接基于数据学习到决策函数F或条件概率分布P(Y|X)作为预测模型。
常用模型:支持向量机、K近邻算法、决策树、逻辑回归、感知机、最大熵等
交叉熵和相对熵(KL散度)?

SVM与树模型之间的区别
(1)SVM
SVM是通过核函数将样本映射到高纬空间,再通过线性的SVM方式求解分界面进行分类。对缺失值比较敏感可以解决高纬度的问题,可以避免局部极小值的问题,可以解决小样本机器学习的问题
(2)树模型
可以解决大样本的问题,易于理解和解释,会陷入局部最优解、易过拟合
朴素贝叶斯的朴素是什么意思?
朴素指的是各个特征之间相互独立。
解释贝叶斯公式和朴素贝叶斯分类。
贝叶斯公式,
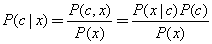 ,
,
最小化分类错误的贝叶斯最优分类器等价于最大化后验概率。
基于贝叶斯公式来估计后验概率的主要困难在于,条件概率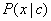 是所有属性上的联合概率,难以从有限的训练样本直接估计得到。朴素贝叶斯分类器采用了属性条件独立性假设,对于已知的类别,假设所有属性相互独立。这样,朴素贝叶斯分类则定义为
是所有属性上的联合概率,难以从有限的训练样本直接估计得到。朴素贝叶斯分类器采用了属性条件独立性假设,对于已知的类别,假设所有属性相互独立。这样,朴素贝叶斯分类则定义为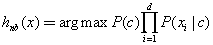
如果有足够多的独立同分布样本,那么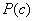 可以根据每个类中的样本数量直接估计出来。在离散情况下先验概率可以利用样本数量估计或者离散情况下根据假设的概率密度函数进行最大似然估计。朴素贝叶斯可以用于同时包含连续变量和离散变量的情况。如果直接基于出现的次数进行估计,会出现一项为0而乘积为0的情况,所以一般会用一些平滑的方法,例如拉普拉斯修正,
可以根据每个类中的样本数量直接估计出来。在离散情况下先验概率可以利用样本数量估计或者离散情况下根据假设的概率密度函数进行最大似然估计。朴素贝叶斯可以用于同时包含连续变量和离散变量的情况。如果直接基于出现的次数进行估计,会出现一项为0而乘积为0的情况,所以一般会用一些平滑的方法,例如拉普拉斯修正,
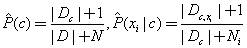
这样既可以保证概率的归一化,同时还能避免上述出现的现象。
随机森林的随机性指的是?
1.决策树训练样本是有放回随机采样的;
2.决策树节点分裂特征集是有放回随机采样的;
随机森林和GBDT算法的区别?
1.并行和串行
随机森林是并行算法,GBDT算法是串行算法
2.决策方式
随机森林分类问题采用大多数投票选举法,回归问题采用各基分类器结果的平均值;GBDT算法采用各基分类器预测结果的累加和;
3.样本选择
随机森林各基分类器采用有放回随机采样的方式;GBDT则使用所有的样本;
4.偏差、方差
随机森林通过降低方差提高性能;GBDT通过降低偏差提高性能;
5.异常值
随机森林对异常值不敏感;GBDT对异常值敏感;
用其他方式实现字典的功能(哈希表)
链表时一种常用的数据结构,是通过“链”来建立起数据元素之间的逻辑关系,这种用链接方式储存的线性表简称链表(Link List)。
机器学习(问题集)
猜你喜欢
转载自blog.csdn.net/weixin_44356285/article/details/87922892
今日推荐
周排行