
今天课的主要内容是TensorFlow的教程和深度神经网络,由助教Greg Kahn主讲。
在开始之前,想继续讲一下上周的一些讨论,因为上次最后没有讲完的所有理论,这是上星期的课程的一点尾巴。在很多场景下,模仿学习是一个学习策略的合适方法,但是在另外一些场景,模仿学习就力不从心了,这也是课程要讲强化学习的理由。如果你想超越模仿学习,非常重要的是确切的定义出一个决定是好是坏,而不是仅仅说采取的行动符合在采样中学习到的,你需要公式化目标函数,在强化学习中称之为奖赏函数或者损失函数。
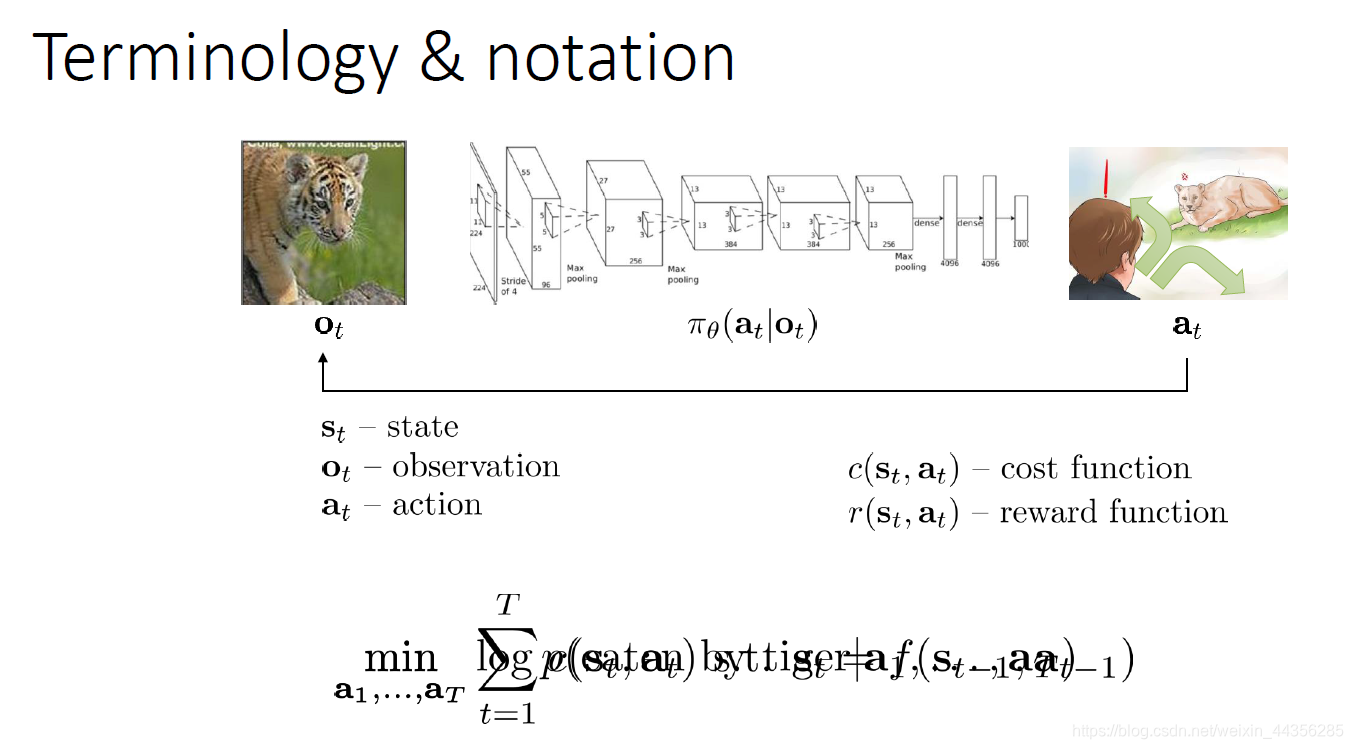
上周用的例子就是这样的。如果你处在例子中所说的老虎在一起,需要立刻采取动作,根本不会想策略是什么或者它代表什么意思,只是需要知道什么是好决定,什么是坏决策。真正关心的是将要发生什么或者不会发生什么,最关心的是会不会被老虎吃掉。动作的目标应该就是最小化被老虎吃掉的概率。概括来讲,在决策问题,你可以写一个损失函数或者奖赏函数,它可以告诉某个状态或者动作有多好,你在所有的时间上最大化奖赏函数或者最小化损失函数。我想最小化,不仅仅是现在而是未来任何一个时刻被老虎吃掉的概率。如果我不跑,即使老虎不会立刻吃掉我,也会在几秒后吃掉我,因此我需要超前看去找出我该怎么做,这也是课程剩余部分的基本问题,怎么解决这些问题。

然后稍微有一点偏离一些这些内容,但是我们也讲到损失函数和奖赏函数是对模仿学习的扩展。因为我们讲到模仿学习的过程中如何定义真实的目标是不清楚的,所以通过引入损失函数和奖赏函数可以重新回到模仿学习的过程中写下价值函数或者代价函数,就可以据此优化模仿学习。

一个简单的例子,价值函数有一些选择。一种听起来比较合理的做法是模仿学习中的奖赏函数是在状态上专家采取某个动作的对数似然函数,这里π*就是一个决策函数,这是个未知的决策函数,本质上人类专家决策过程是一个未知的过程。你的目标是最大化,专家选择的任何动作的对数似然概率,这个目标有一个很重要的方面不是说匹配(训练)数据中的动作,而是说匹配任何你实际遇到的状态下采取的动作,所以如果你发现处于一个之前训练中从来没见过的状态,如果你仍然把这个当做目标,你也许就不会得到这个状态下正确的动作,即使你在专家经历的状态选对了正确的动作。当然,这就导致上周我们讲过的整个分布的不匹配。我们也提到一个非常简单的目标函数,我把它写成代价函数,你也可以作为奖赏函数,反一下就行,这就是0-1,是相对于对数似然函数利用0-1损失函数分析损失边界的时候更容易。你当然可以用对数似然函数分析这些边界问题,用0-1损失函数更容易一点。0-1损失函数意思是如果你的动作匹配专家的,你的损失就是0,否则就是1。基本上就是为每一个错误付出代价1,分析问题简单一点,更直接。

然后我们在走钢丝绳这个例子中做了进一步分析。在这个例子用0-1损失函数非常适合。我们要做一些设定,如果你想界定一下你的损失函数,必须要做设定。这里设定非常简单,在你训练的所有的状态中,你犯错的概率小于ε,这是一个合理设定,因为在你训练的状态中你必须设定你的训练误差很小,你必须要能界定你的犯错的概率。基本上说我有一个很好的模型,有一个足够好的学习算法,因此最后我的训练误差很低。另外就是关于走钢丝绳,这个问题很简单,也很具体。你有一系列状态,中间的是好的状态,示范人总是走的对这样,他们永远不会掉到红色区域,一旦进入红色区域,你就永远不会回来了,所以这是一个有意思的走钢丝者,他不担心掉下去,他担心的是犯错误,他不高兴的原因是他掉到了红色区域,因为这些状态下他不知道该怎么办,所以他会一直犯错。基于这个设定我们说可以我们能够界定在走钢丝项目中我们能损失多少吗?
我们说整个事情需要T个时间步骤,在训练过程中出现的所有状态上都有概率为ε犯错的可能性,也就是图中这些灰色的状态,而在我们没见过的状态中,如果我们进入训练中,我们没有见过的状态,肯定会犯错。因为我们没法界定错误,我们提到在第一个状态中我们犯错的概率是ε,那么如果我们在概率ε的情况下犯了错误,就进入到这些红色的状态之一,剩下的t个时间周期上我们只能不断的犯错。因为在红色的状态下总会犯错,在第一个时间片,你会以概率ε付出T的代价,那么剩下的1-ε概率,你会继续。这个时候,你会继续以概率ε犯错,进入红色的状态,付出T-1的代价,ε因为剩下的时间一直都会犯错,就这样继续下去,所有的项中都有T的乘积,这些都有T,所以T的倍数之和意味着代价是T的平方,并且左边都是乘的ε,所以T乘以每个时间片的εT,意味着总的代价是εT2。这基本上就是你能做到的边界了,除非你增加额外的设定,所以如果你有一个分布是会以εT2的上限不匹配的高绿,你必须担心一下你的代价,这个代价非常大。因为它意味着你的是任务耗时越长,代价增加是线性增长的,所以足够长时间的任务,即使你使用强大的误差非常小的神经网络,你仍然会付出非常大的代价,但是这个分析非常简单,这个分析适合那种你只能在训练中出现状态上界定误差,这甚至没有利用监督学习的放法的结果。这就是上周五剩下的部分。

让我们想一个更泛化的分析,比如一个关于图像观察的例子。在图像观察的例子中,你会发现你不可能真的看到两个一模一样的状态,所以设定你的误差只是在训练数据集中出现的数据才能界定就失去意义了。因为你从来不会看到两次一样的状态,你可以看到差别很小的照片,我们需要做的设定是它是一个更标准的机器学习,也就是说我们可以界定泛化的误差。如果你看到和你的训练数据同一个分布的新的状态,你的误差仍然不大于ε,这是一个合理的设定。对于监督学习和一个简单的函数近似,只要有足够的训练数据和其他条件你就能把泛化误差限定在一个值,所以在大多数的例子中做这种设定是合理的。
关于dagger我们也讨论了一点,如果dagger能够做到,它设想的那样让测试数据的分布和Pθ的数据趋近一致,意味着分布不匹配问题就没有了,你就可以界定你的误差是εT。因为P训练数据和Pθ的数据一致,所以你犯错的概率永远是ε,你有t个时间,所以犯错的概率最大是εt,这就是你能做到的最大代价,这也是dagger算法想要的减少分布偏移的目标,这都不错。今天讲的例子就是p训练数据不等于Pθ数据,所以这个例子有助于我们理解,为什么我们需要担心,如果P训练不等于Pθ,dagger的效果就不好。我们会发现,我们就有非常差的边界值。这就是今天要讲的内容里会涉及一点代数知识,因为我们必须要处理分布的计算,但是我们会带过它,因为我们今天要做的分析知识泛泛的讲,分析序列的分布、决策过程,并且相同种类的概念也会出现在其他强化Opilk中,因此我希望通过这个在这里讲一下模仿学习B,其实很简单,但是基本的概念会在后面讲述,所以当我们分析训练分布不等于eθs的情况时。
顺便说一下,这个分析是在dagger论文的分析之后的,这是那篇论文的标题。我们要做的一件事情就是引入一个有趣的等式,并且这个等式允许我们将一次分布关联到另一个分布,我来解释一下这个方程的意思是Pθ(st)是指状态在某一时刻的分布,所以可能是走钢丝者开始走钢丝10秒后的状态分布,我们实际上可以写一个分布的方程,这个方程我们可以说可能是(1-ε)t,在第T步之前你不会犯任何错。在第一步时你犯错的概率是ε,也就是说你不会犯错的概率是1-ε,如果你没有在第一步出错,然后在第二步你的状态分布就和公式的一样,因为你没有犯错,这就意味着连续两次没有犯错的概率是(1-ε)2,然后在第三步你和公式处于相同的状态分布,所以在第t步以后你有(1-ε)t不出错的概率,而且如果你没有犯任何错,你和公式的状态分布是一样的。现在,还有一个相反的,就是1-(1-ε)t,这就是你至少犯了一个错误的概率,你可能犯了不止一个错误,但是这是你至少犯了一个错误的概率,当然你也可以构建一个变态的决定,让橡走钢丝一样的问题一旦你犯了一个错误,你就会处于跟公式完全不同的状态分布,所以我们可以称这个分布为“P错误”,这可能是一个非常复杂的分布,但这基本上是你犯了至少一个错误得到的分布,并且从走钢丝的例子中我们可以知道,我们可以构建一种变态的情况,在这种情况下即使你犯了一个错误,这个P错误也会和P序列完全不同,所以对于任意分布,我们都可以写出这样的方程,并且基本上我们不会对P错误做任何假设,我们只会说,好吧P错误可以任意出错的,但是P序列,我所知道的P序列是一个我可以纠正错误的地方,因此P序列是你没有犯错的概率并且这仅仅是另外潜在的非常糟糕的分布,现在我们可以开始把Pθ(st)和Ptrain(st)联系起来,我们要把他们联系起来,用总变差发散来表示。总变差发散是一种有趣的说法,取两个概率值差的绝对值,然后取其中一些绝对值除以所有状态,所以当你看到这种向量的时候,它的意思是用Pθ(st)-Ptrain(st),然后取差的绝对值,我们把Pθ(st)带入到公式中,可以得到什么?可以得到一个t-Ptrain,但是B序列抵消了,因为他们总是相等的,所以这一项就是0,然后我们就只有剩下的一项就是1-(1-ε)的t次方,乘以T错误这一项不会消失,因为P错误不等于B序列,所以我们可以写成Pθ(st)与Ptrain(st)之间的总变差发散等于1-(1-ε)的t次方乘以P错误和Ptrain之间的总变差发散,所以这个关系有点不简单。记住不能对P错误做任何的假设。
事实上我们可以构建出变态案例,它与P序列尽可能的不同,那么谁能告诉我在两个总变差发散的概率分布中最大可能的总变差分配器是什么?概率分布必须和为1,所以在任何状态下的最大值都是1,并且它们必须大于0,因此我们假设说,我们有最坏的可能设置,比如说状态0的P错误是1.0,状态1的Ptrain是1.0,它们之间的总变差发散是多少?它们之间的绝对值差的和是多少?精确的说最大的总变差数可能是2,我们可以用2乘以1-(1-ε)的t次方来约束它,这是最大的可能差异,我们可以先暂停一下,我们可以说这是我们的绑定,我们可以把它化简一下,然后通过使用一个简洁的代数恒等式,这基本上是代数中的一个事实。对于0和1之间的任何值,(1-ε)的t次方大于或者等于(1-ε)乘以t,这就橡代数课上的一个朋友,并且你知道两边同时减去1取负数,这就可以使得你通过用2乘以ε的t次方来约束它,所以它只是一个更短更方便的表达方式,但是它也有很多可能的状态,假设世界上有三种状态,所以这是一个除以三个值的分布,或者是三个值的分布,我们假设这个是1.0和状态0,同时这个就是1点,这是所有状态的和。这是对的,现在我们有了两个分布的差的界限,并且这个界限看起来很简单,就是2乘以ε乘以t。
现在我们来分析一下,我们真正关心的量,也就是期望成本,这里我所做的就是求和然后用期望的线性化把它从期望中提出来,它就是期望成本的步数之和,所以它们两个完全一样,那么我们写出期望的定义就是Pθ(st)乘以Ct(st)的所有状态的和,这一点代换来代入。我们在这里看到的东西,那我们怎么做代换呢?我们说Pθ=Pθ+Ptrain-Btrain,你总是可以加上Ptrain—被训练,因为它们加起来等于0,所以你会得到Pθ+Ptrain-Btrain,Pθ-Btrain被Pθ-Btrain绝对值所限制,因为很明显绝对值会使负数变成正数,所以它会变大,所以你可以把绝对值放进去,这样做之后,你就可以得到这个时间项乘以CT,你会得到这一项乘以CT,最大可能的花费总是大于CT,所以我们总是可以用Cmax代替CT,这是一个有效的界限。
对于一个特定的状态,一个特定的时间步长最大的花费可能是多少吗?从定义上来看确实是1,否则你就会在0处出错,那么最大的代价是1,我可以忽略这一项,它是1.0,现在我通过用Ptrain乘以CT加这个量,乘以1来限制我的期望成本,Ptrain下的预期成本是多少?ε。对于单个时间的东西它是ε,但是总的时间是ε乘以T,这只是因为这个普遍化的界定,所以这一项对于任意时间步长都是ε,我们把时间步长求和,所以是ε乘以T,所以这一项是有用的一项,这一项虽然不会影响到我们,所以这一项是不好的一项,所以我们会得到ε的总和除以T,加上这个以2乘以εT为界的数值,ε的总和除以T,加2乘以εT,这当然是T的平方,我们有一个简单的向量,这是我们在一个困难项中不关注的,它是εT的平方的阶。现在我们可以看到,这是处理概率分布的一般情况,你的限制依旧是T的平方,事实上你可以证明这个界限和得到的一样好,这就有一点复杂了,但是你可以看看这篇论文来了解它的细节。这基本上就说明了,在一般情况下,如果你不匹配分布你仍然会得到二次成本,这是关于成本和回报函数的更一般分析。

到目前为止,我们讨论了这种很好的理论,我们有简单的成本,一切都很容易分析,特别是在实践中。当然我们从周五开始讨论强化学习时,奖励功能会变得更复杂,所以你可能会想,你可以用简单得奖励函数,就像一个奖励函数,如果你做对了,就等于1,反之为0.如果你在0这个地方犯了错,就会得到-1。在实践中,对于强化学习的问题,往往有更复杂的成本和回报函数,如果你想要一个机械手臂来拿起一个物体,并且把它移动到一个目标位置,你认为可以给它一个1作为奖励,因为它把物体放到了正确的位置,并且明白了指令,或者其它原因,但是实际上,这是一个很难解决的强化学习问题,所以如果你看一点开放的资源中的关于公共强化学习算法和公共环境的实现,看看奖励函数,可能会看到一些非常复杂的东西,而不是橡你所期望的那个,如果你把它放在正确的地方,你可能会看到一些复杂的混乱的术语,有一些术语奖励你,是因为靠近了这个物体;一些术语奖励你,是因为让物体靠近了位置;一些术语是奖励你,让机械手臂有最小化的移动量等等。我们经常得到相当复杂的奖励函数的部分原因是这些非常简单的奖励函数提出了一个非常大的探索问题,强化学习发现一次成功的策略,所以他们可以开始进步,我们会在以后的课程中讨论探索问题。
如果想要Ptrain接近Pθ,那不意味着ε趋于0,它不适用dagger,dagger并没有试图改变Pθ,它试图通过增加Pθ的数据来改变D序列,如果你能让v趋于0,那么你也会匹配到分布,但是有了dagger你就不用这么做了。
实际上,如果你在做RL,奖励函数可能会复杂得多。另一个关于步行的例子,这实际上是来自一种步行测试基准的标准。如果你走路的时候,回报是0,相反情况下,你会认为回报是1,但是实际上你的奖励函数是一些复杂的项的组合、一些向前移动的东西、一些保持躯干直立的东西、所有这些不掉下去的东西。在实践中,我们这样做是因为探索可能非常困难。所以接下来几周,当讨论RL时,会学到更多关于奖励函数的知识。

大家好,我是Greg um one。今天将要讨论TensorFlow的综述,所以假设每个人都很熟悉机器学习,学过神经网络,在你知道像反向传播这种概念之前,仍然会去介绍一点关于他们的知识,然后用python notebook去测试代码。

在深入讨论tensorflow之前,需要明确一下这门课的目标,即训练一个代理去有效的得到任务目标,而不是去学习如何去训练一个神经网络,神经网络只是得到结果的一种方式。所以我们想要去训练一个代理,这个代理包含什么。

我们有一个代理,之后他会采取一些方法,我们也有一个数据集去训练一个代理会用到的模型。例如训练一个模仿专家的算法,所以你的模型是一些克隆行为。但是在强化学习中会有一个真实的代理去采取某种方式,他会得到更多的数据加入其中,然后再去训练你的模型,做多次相同的迭代更新。

可以在这个课程中去讨论如何训练模型。到目前为止,sergei想到了一种假设,可以这样去做。如果现在谈论的是如何去训练模型。

什么是训练模型?这是机器学习领域所需要解决的,所以通常情况下你尝试去训练一个学习函数fθ,这个学习函数的输入是x,想要输出的是y,然后你去训练一个关于x的模型fθ,去匹配一些真实的y标签
待续…