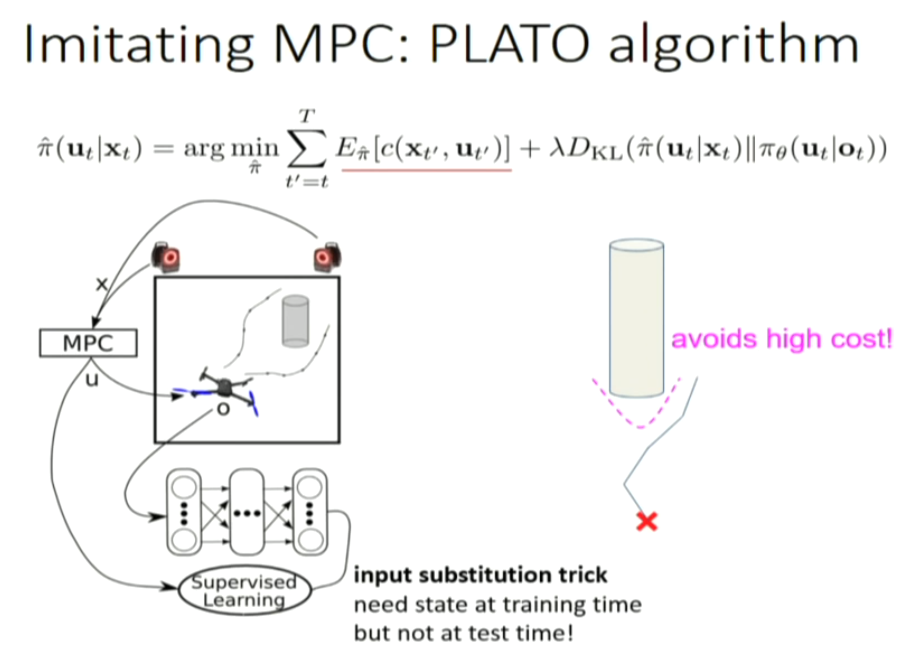


There are some problems: mismatch of model and reality; gradient explosion
扫描二维码关注公众号,回复:
996227 查看本文章

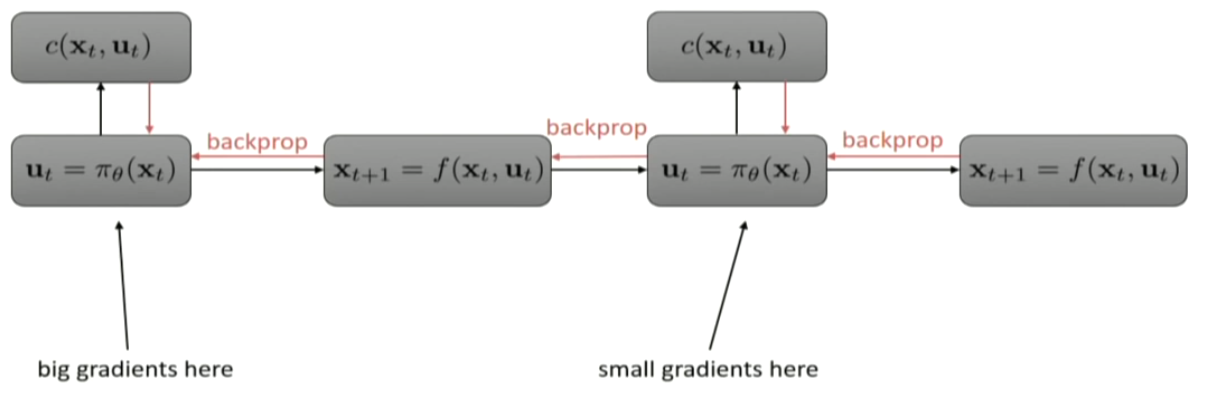
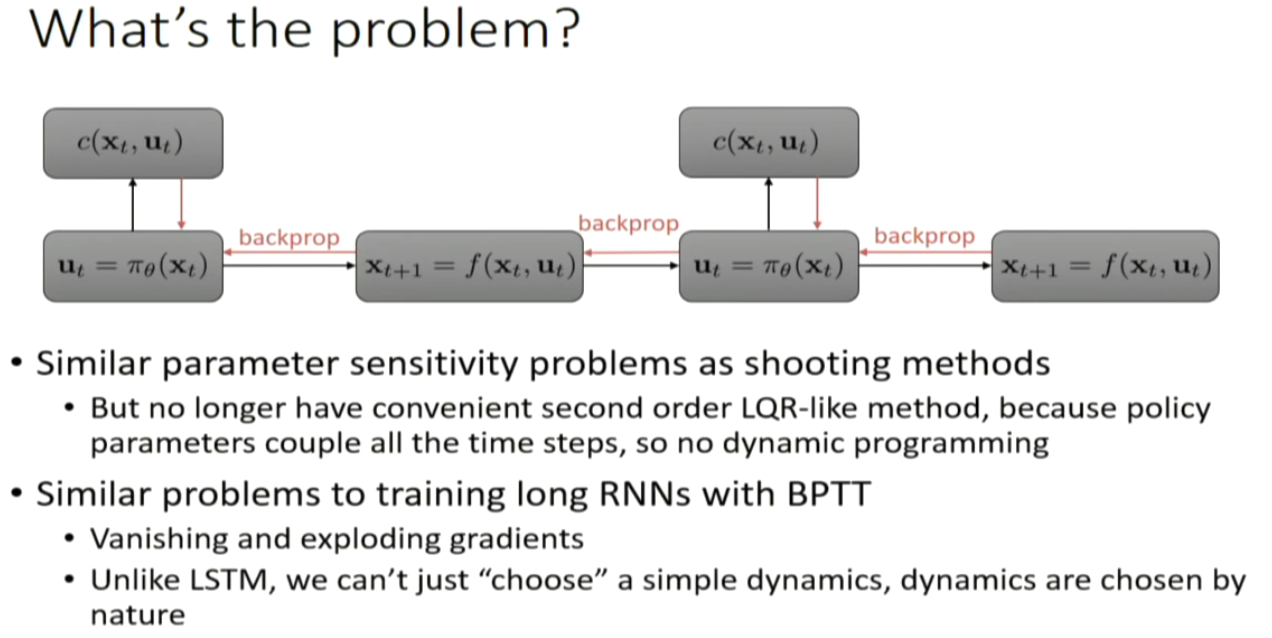
so, the dynamics can be quite messy, and backpropogating can be quite problematic.
sudden change in velocity and so on. schochastic system. gradient descent can be tough.
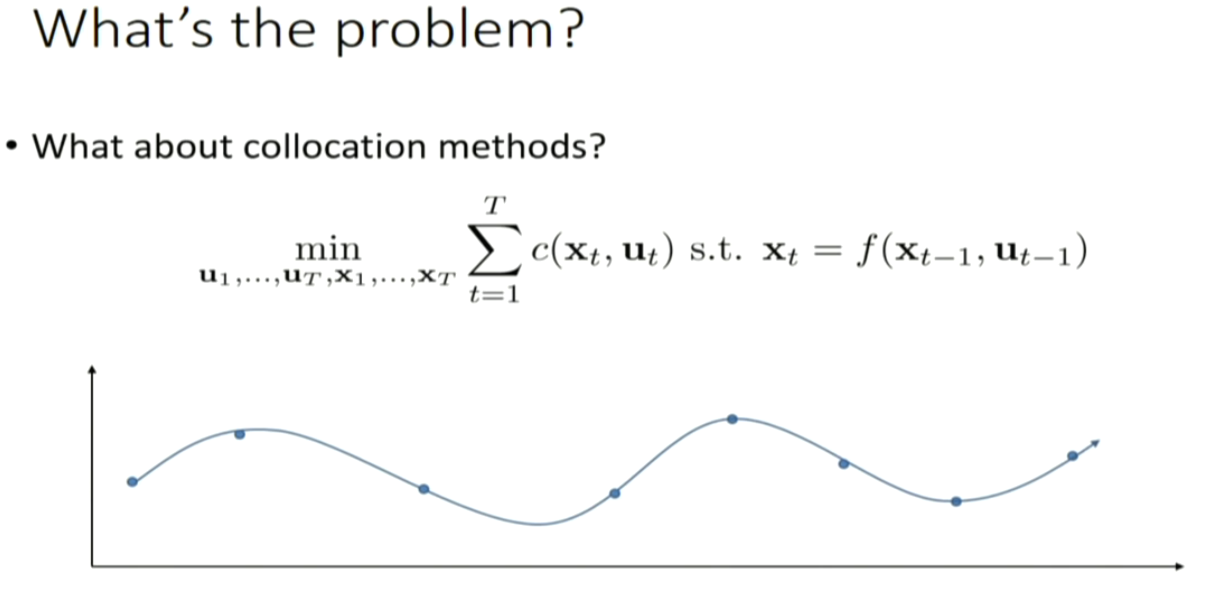
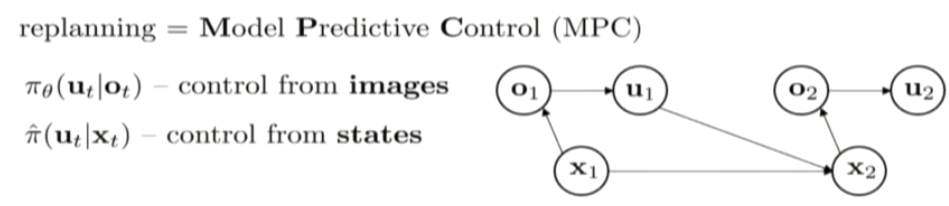
can we apply this trajectory optimization method to optimize policy?

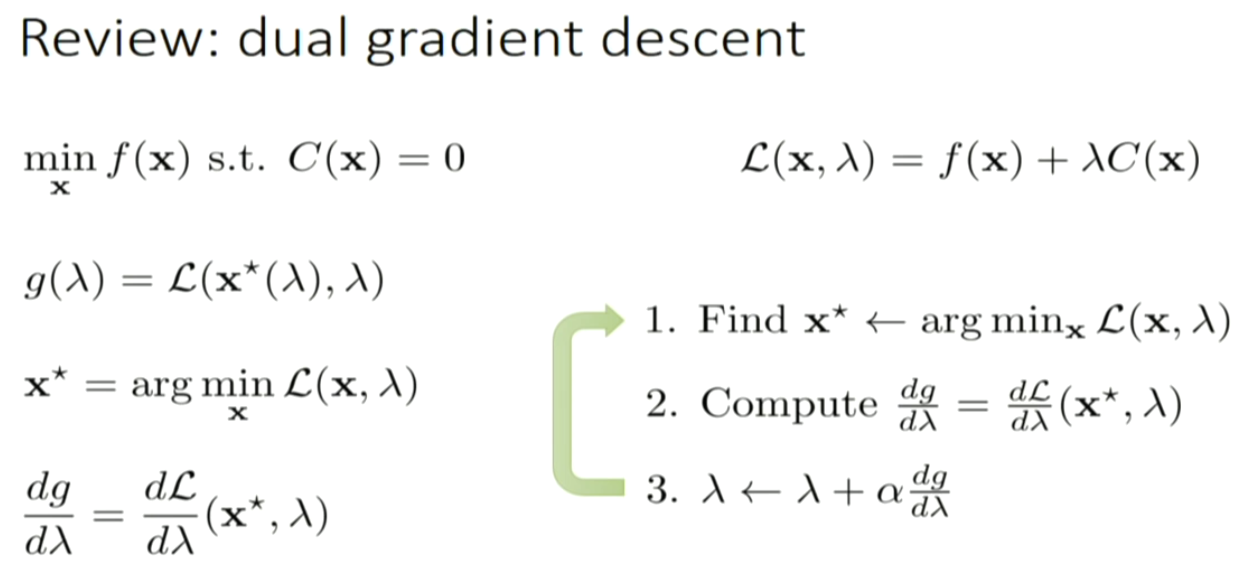




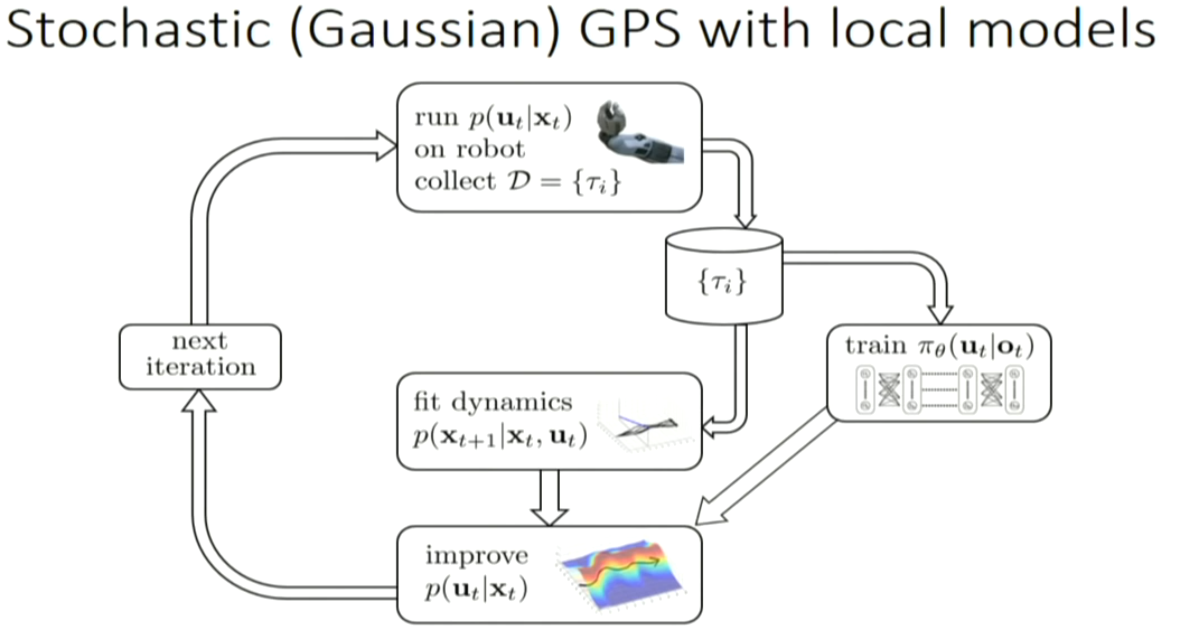
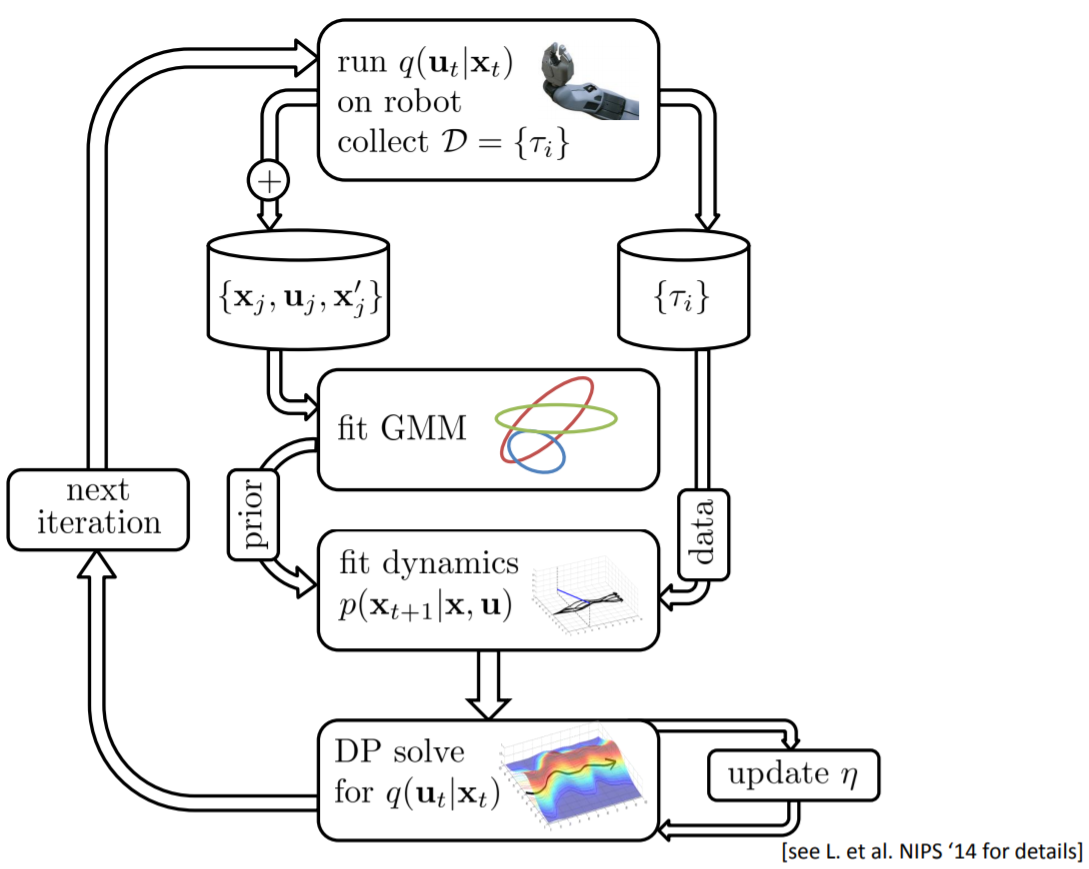
GPS: guided policy search
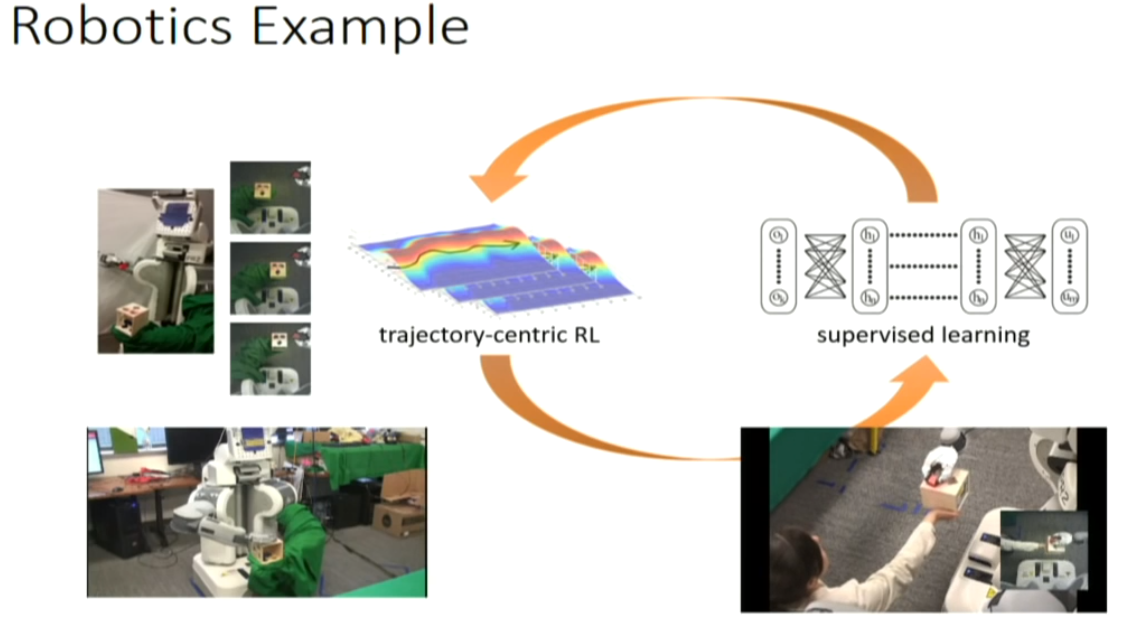
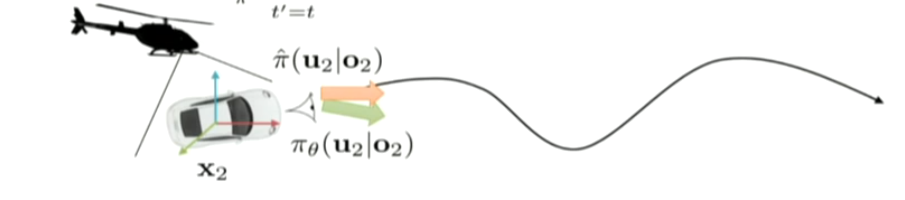
in this case, ot is from the camera and the joint velocity