目录
绝对值技巧(只考虑了p的值,即与y轴的距离,q的值不在考虑范围)
分类和回归的主要区别在于:分类预测一个状态;回归预测一个值。
线性回归
观察数据,绘制出点最适合的直线。
绝对值技巧(只考虑了p的值,即与y轴的距离,q的值不在考虑范围)
某个点:M(p, q),直线:,为了让直线更靠近点M,将
,得到
,但是这样变换后,直线超过点M。为了移动较小的步,引入学习率:learing rate:
,


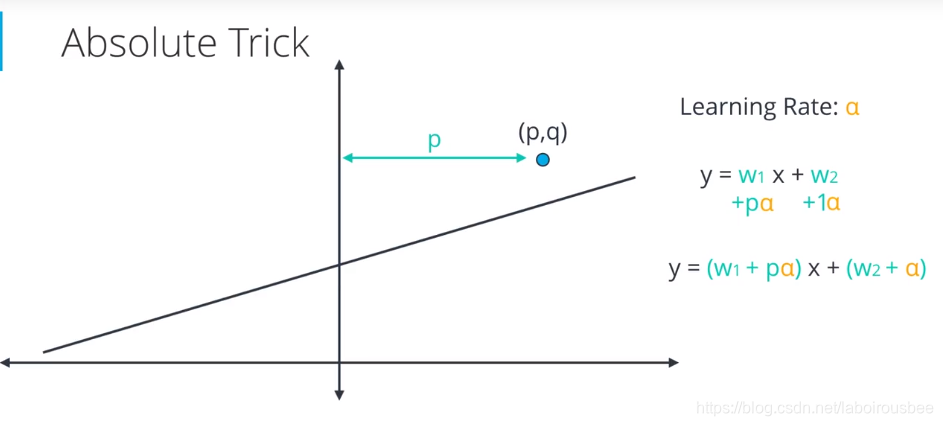
对于M点在直线的上面,进行上面的变换,在直线的下面,做如下变换:

对于在y轴右侧的是加号,在左侧的依然是加号,所以叫绝对值方法。

平方技巧
此方法不分点在直线的上方还是下方,同时将q的值也考虑进去。变换后的方程:

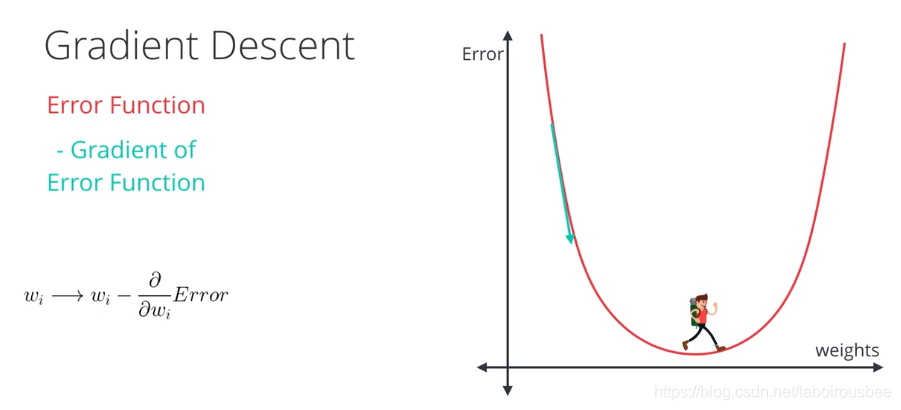
梯度下降法
减少误差,用梯度下降法。达到如图中的最低点时,变成线性问题的较优解。
平均绝对值误差
误差函数:平均绝对值误差、平均平方误差。

平均平方误差

最小化误差函数
最小化平均绝对误差,使用了梯度下降法,梯度下降法与绝对值技巧完全相同。最小化平方误差,梯度下降法与平方技巧完全相同。




均方误差与总平方误差

小批量梯度下降法
批量梯度下降法与随机梯度下降法

小批次梯度下降法
实际操作中,大部分情况下,上面两种方法都不用。如果你的数据十分庞大,两种方法的计算速度都将会很缓慢。线性回归的最佳方式是将数据拆分成很多小批次。每个批次都大概具有相同数量的数据点,然后使用每个批次更新权重,这种方法叫做小批次梯度下降法。
绝对值误差VS平方误差
上图中的三个绝对值误差是相等的。但是直线B是平方误差最小的,均方误差实际是二次函数。



scikit-learn中的线性回归
>>>from sklearn.linear_model import LinearRegression
>>># 线性回归模型,使用scikit-learn的LinearRegression
>>>model = LinearRegression()
>>># fit()将模型与数据进行拟合
>>>model.fit(x_values, y_values)
>>>#predict()函数做出预测
>>>print(model.predict([ [127], [248] ]))
[[ 438.94308857, 127.14839521]]线性回归练习
你需要完成以下步骤:
1. 加载数据
- 数据位于文件
bmi_and_life_expectancy.csv中。 - 使用 pandas
read_csv将数据加载到数据帧中(别忘了导入 pandas!) - 将数据帧赋值给变量
bmi_life_data。
2. 构建线性回归模型
- 使用 scikit-learn 的
LinearRegression创建回归模型并将其赋值给bmi_life_model。 - 将模型与数据进行拟合。
3. 使用模型进行预测
- 使用值为 21.07931 的 BMI 进行预测,并将结果赋值给变量
laos_life_exp。
# TODO: Add import statements
import pandas as pd
from sklearn.linear_model import LinearRegression
# Assign the dataframe to this variable.
# TODO: Load the data
bmi_life_data = pd.read_csv('bmi_and_life_expectancy.csv')
# Make and fit the linear regression model
#TODO: Fit the model and Assign it to bmi_life_model
bmi_life_model = LinearRegression()
x_values = bmi_life_data[['BMI']]
y_values = bmi_life_data[['Life expectancy']]
bmi_life_model.fit(x_values, y_values)
# Make a prediction using the model
# TODO: Predict life expectancy for a BMI value of 21.07931
laos_life_exp = bmi_life_model.predict([[21.07931]])
高维度
为了找到权重W1到Wn,这个算法与包含两个变量的算法完全相同,可以使用绝对值技巧或平方技巧,或者计算平均绝对值或平方误差。

多元线性回归
如果你使用 n个预测器变量,那么模型可以用以下方程表示:
如果模型有多个预测器变量,则很难用图形呈现,但幸运的是,关于线性回归的所有其他方面都保持不变。我们依然可以通过相同的方式拟合模型并作出预测。
解数学方程租(未完待续......)
线性回归注意事项
线性回归隐含一系列前提假设,并非适合所有情形,因此应当注意以下两个问题。
最适用于线性数据
线性回归会根据训练数据生成直线模型。如果训练数据包含非线性关系,你需要选择:调整数据(进行数据转换)、增加特征数量或改用其他模型。

容易受到异常值影响
线性回归的目标是求取对训练数据而言的 “最优拟合” 直线。如果数据集中存在不符合总体规律的异常值,最终结果将会存在不小偏差。

但若添加若干不符合规律的异常值,会明显改变模型的预测结果。

在大多数情况下,模型需要基本上能与大部分数据拟合,所以要小心异常值!
多项式回归(非线性数据)

解决4个权重,只需要求出平方误差的平均值或绝对值,对4个变量求导,使用梯度下降法,修改4个权重,最小化误差,这种算法称为多项式回归。
正则化
正则化,改善模型,确保不会过度拟合的有效技巧,这个概念可以用于回归和分类。用分类问题解释正则化。

利用绿色的系数,把他们转化为误差的一部分。
L1正则化:


复杂的模型得到较大的误差。L1正则化与绝对值相关。
L2正则化:


复杂模型受到的惩罚更多。
如果调优这些绿色参数?
参数,
乘以这个绿色参数,得到的情况如下:如果有个大的
,更多地惩罚复杂性,拾取更简单的模型。如果有个小的
,会较小数量惩罚复杂性,使用更复杂的模型。

L1和L2的对比
一、L1实际算起来效率不高,虽然看起来更简单,但是绝对值很难求导(求微分);L2平方是不错的导数,计算起来更加容易。
二、只有数据稀疏时,L1正则化会比L2正则化更快。例如(有1000次数据运算,但只有10个具有相关性,其中包含很多0,则L1会更好。)L1适合稀疏输出,L2适合非稀疏输出。
三、如果多列包含0,那么L1正则化更好些。但是如果数据均匀分布在各列,L2正则化更好些。
四、L1正则化最大的好处在于提供特征选择。如果有1000列数据,但只有10列数据相关,其他都是噪音,L1可以注意到这一点,把不相关的数据转换为0,L2无法做到这一点,L2会对所有列平等对待,并且给我们所有数据的总和作为结果。

神经网络回归
解决非线性数据的另一种方法:分段线性函数。

使用神经网络,并不是为了分类,而是为了回归,只需要删除最后一个激活函数。
尝试神经网络
Jay Alammar 创建了这个神奇的神经网络 “游乐场”,在这里你可以看到很棒的可视化效果,并可以使用参数来解决线性回归问题,然后尝试一些神经网络回归。https://jalammar.github.io/visual-interactive-guide-basics-neural-networks/