算法简介 算法原理 样本构造 损失函数 使用细节
# ssd算法:
##简介
刘伟在2016年提出,发表在ECCV;是一种通过直接回归的方式去获取目标类别和位置的one-stage算法,不需要proposal;作用在卷积网络的输出特征图上进行预测,而且是不同尺度,因此能够保证检测的精度,图像的分辨率也比较低,属于端到端的训练;
input->CNN->Lreg,Lcls
CNN特征->区域分类,位置精修
##算法原理
输入是300x300,通过主干网络VGG-16(也可以是Resnet,MobileNet)得到feature map,然后通过下采样(Pooling层)得到6个不同尺度,38x38,19x19,10x10,5x5,3x3,1x1,将这6个不同尺度的feature map作为检测预测层的输入,最后用nms进行筛选和合并;
每一个feature map层都会进行default boundingbox的提取,针对每一个boundingbox都会有类别分数以及位置的偏移量,这里就有两个问题:
1.如何进行多个尺度的预测?(见下)
2.每个尺度上选择多少个bounding boxes?
答:通过ssd的相应的配置文件来进行配置,其实是通过相应层的name来进行配置,决定有多少个box,以及哪一层作为预测层的输入
###主干网络介绍
将VGG最后两个FC层(FC用来分类,映射每一类的概率)改成卷积层,并增加4个卷积层,增加了多次度预测,从而提升模型预测性能;
###多尺度feature map预测
(类似anchor机制)不同层的feature map(输入到相应的预测层),大小为mxn,以每一个点(cell,找到他在原图中的位置)为center,每个cell生成固定scale和aspect ratio的k个prior box,通过和GT的比较得到prior box的label,再对每一个prior box预测他们的类别score和坐标offset(x,y,w,h),得到维度为(4+C)xkxmxn的输出;
两个超参数:scale和aspect ratio

关于Prior box Layer:
上面说了,类似于anchor机制,shape数量越多,预测效果越好;
针对6种不同尺度的feature map层,提取的prior box的总数量为:38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732个
可以看到,这里每一个feature map cell并不是k个prior box都取,为什么呢,因为实际训练中,并不是每个prior box都去计算loss,那么具体怎么操作的呢?通过什么策略来进行筛选呢?接下来我们来看一下ssd的样本构造策略。
##样本构造
正样本:
从prio box集出发,寻找与GT box满足 IOU 大于0.5的最大prior box放入候选正样本集;
或者,从GT box出发,找到与之最为匹配的prior box放入候选正样本集;
负样本:
IOU小于0.5的作为负样本,而中间那些可以丢掉不考虑;一般正负样本比为1:3;
或者进行难例挖掘

注意:除了这种寻找正负样本的方法,还可以对正负样本做数据增强;
##损失函数
SSD的损失函数包含了两个部分:分类loss + 回归loss,其中前者一般用Softmax Loss,后者一般用Smooth L1 Loss,然后两者进行加权;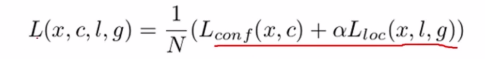

在训练过程中,我们只需要确保prior box的分类准确,并且让每一个prior box尽可能回归到GT box;
##SSD使用细节
1.注意分类和回归网络的权重分配;
2.注意正负样本之比;
3.难例挖掘默认只去64个最高预测损失来从中寻找负样本;
4.SSD输入尺寸越大,mAP越高,但是会导致检测速度的下降,因此要具体需求进行选择;
5.更多的feature map,更多的default box,都可以使得结果更好;