当前业务场景中Mongodb的IOPS经过压测后的最大峰值为20000/s,在系统上线后,通过mongostat工具监控发现操作数经常会飙升至30000+。由于主要的操作是Spark流处理业务的insert操作,因此本文主要从Spark-Streaming方面来讨论优化Mongodb的性能。
spark-streaming 限速
背景
业务的主要流程是flower->kafka->spark-streaming->Mongodb。
采集端现状:
由于采集器端flower的业务限制,基本的采集频率为分钟级别,同时,由于flower采用C语言开发的单机程序,将采集的数据发送到kafka时存在性能瓶颈(因为一台采集器要发送多种数据,量大且种类繁多),也就将数据进行了压缩,每100条数据压缩成1条发送到kafka。
spark-streaming现状
流处理部分则是使用了1分钟甚至10分钟窗口来获取kafka的数据,最后写入到mongodb中。
Mongodb现状
mongodb采用了主从模式,使用容器的形式部署,限制了内存和存储。通过iostat工具发现mongodb所处的磁盘%util长时间处于100%
分析
将mongostat工具的打印结果进行趋势绘图。命令如下
mongostat --port26000 –discover
每条数据的结果为:

这里只取主分片(26011、26022、26033)的观测结果,如下图所示:
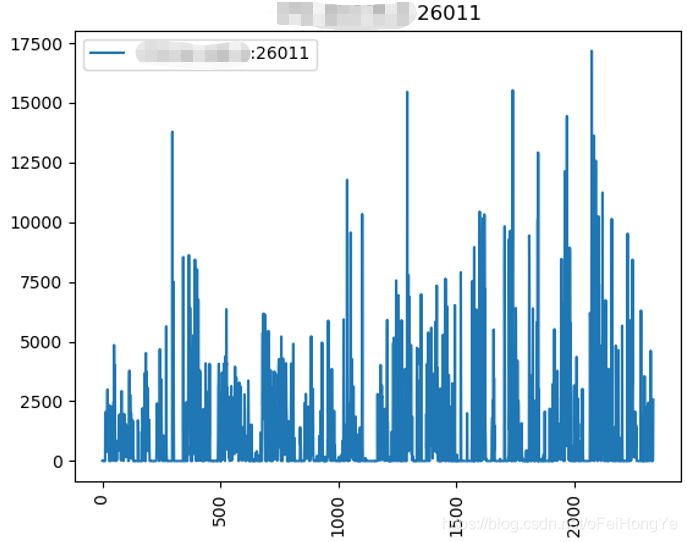
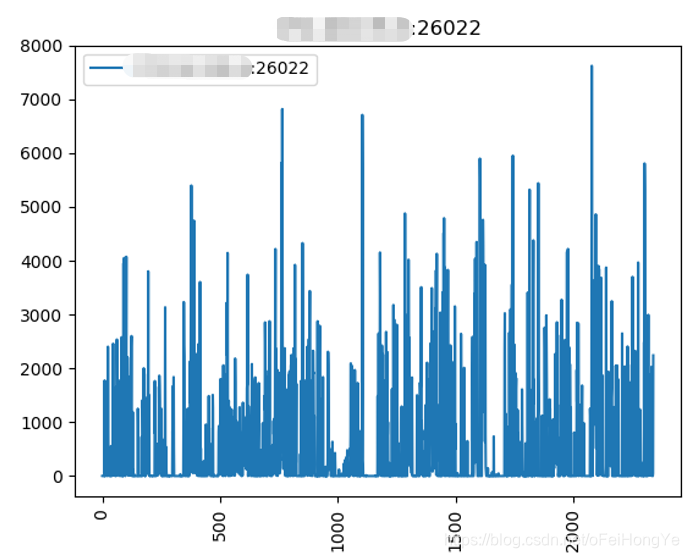
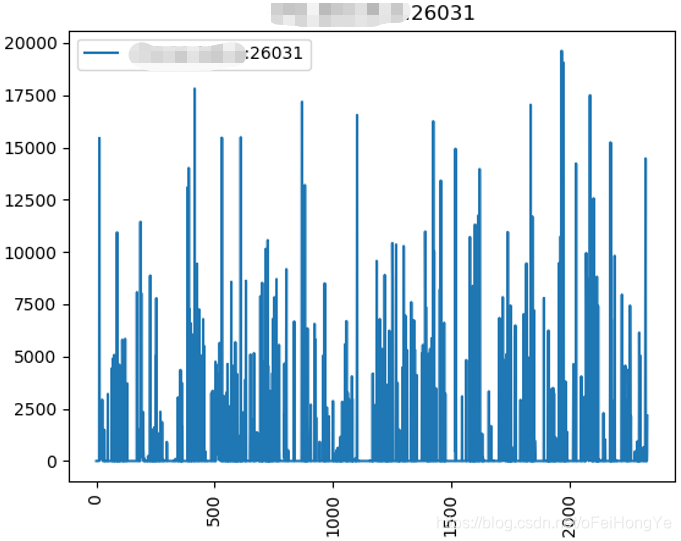
从趋势来看这种写入明显存在突发的流量,为了观测这种突发情况,特意进行了隔离实验,仅运行一个Spark任务,且重新部署一套新的mongodb。而且,将Spark-Streaming的窗口时间设置为1秒,再次观察mongodb的写入趋势。为了简洁起见,这次只看主分片的总趋势:
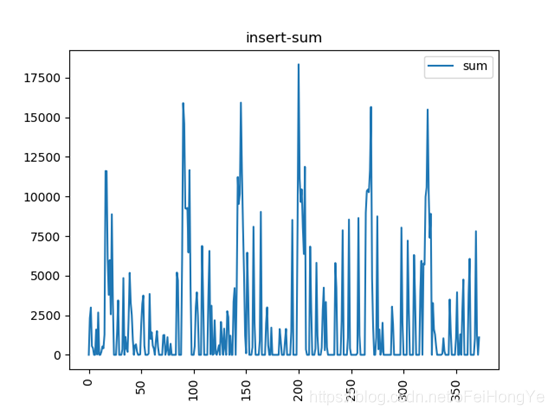
发现将流的窗口设置为1秒了,数据依然呈现出突发的写入情况,这个是我们所不希望看到的。同时监控Spark每秒从kafka收到的数据量,该收集方法是“dStream.count().print()”,不属于shuffle,因此不影响性能。
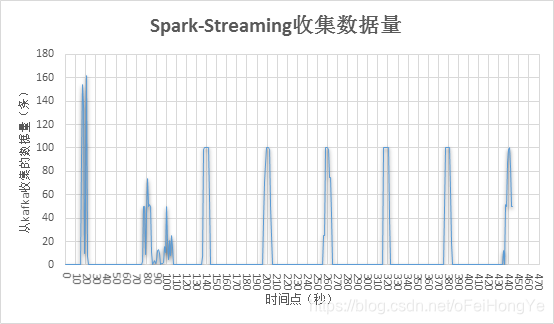
该图中前期存在消费不规律,这是因为当前kafka消费组中存在资源堆积。而在多次窗口消耗掉kafka堆积的数据后,则明显的呈现出规律性。即这个主题的数据是每分钟发送一次的。这个从上图中能够看到每次数据的波动正好是1分钟。
现在就能够解释清楚突发写入的主要原因了。spark的窗口短时间内从kafka中接受到100条数据,每条数据在写入数据库前要分解为100条(原来是100倍压缩),那么突发写入量就是10000条,而且这是一个spark作业的写入量。也就不难解释从Mongodb侧观察到的突发写入现象。
解决方案
为此考虑到对spark从kafka接收的数据量降低,修改变量为
“spark.streaming.kafka.maxRatePerPartition=10”(原来业务设置为3000),表示每秒spark的分区从kafka最多拉取10条数据,本测试中kafka共四个分区,而Spark使用了kafka的分区,也就是最多拉取40条数据。
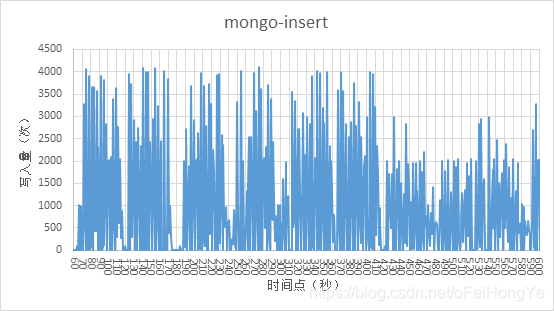
从波峰和波谷角度出发,可以发现波峰比原来变低了,而且波谷的间隔减少了。由于kafka的数据是100条压缩为10条,所以看到这个插入量最大值在4000条,也就是Spark从kafka拉取了40条/秒。下面看Spark的拉取数量。
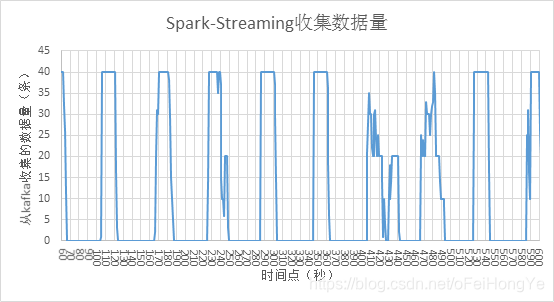
因此得出结论:Spark流处理的波峰是可以控制的,且时间窗口可以压缩到秒级别。
修改Spark的流处理参数“spark.streaming.kafka.maxRatePerPartition=1”,发现Spark仍然是每分区收集1条消息,如下所示:
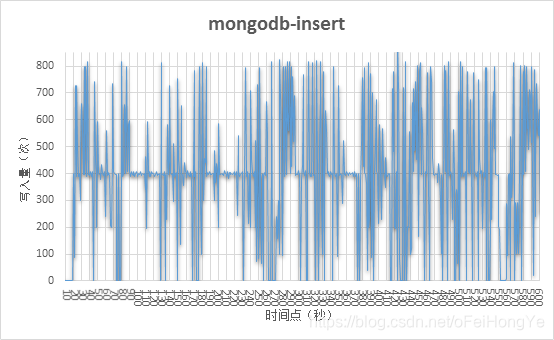
该图中可以看出写入量在400左右波动,最高值有达到800,猜测这个是mongodb的延迟引起的(待考证)。实际上,400条是数据量较少的。下图显示Spark从kafka获取的数据情况。
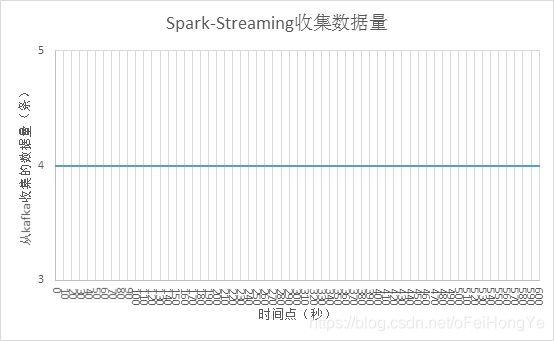
可以发现Spark收集数据稳定在4条左右。那么突发流量就可以通过此方式“削峰”了。
然而实际中却存在一些取舍,如:1分钟的窗口中将A数据统计为B后,将B落盘,而且业务要求展示1分钟的数据。那么使用1秒钟的窗口仅将A数据落盘不仅提高了IOPS,也没有业务价值,这个时候不得不使用1分钟窗口。
因此该方法主要适用于简单的流处理业务进行限速。
附录
mongostat监控代码
主要方式是将mongostat工具的输出写入到一个文件中,然后使用python分析该文件
注意:文件格式要另存为utf-8格式,可以使用记事本的“另存为”方式,或者notepad++的编码设置
#! /usr/bin/env python
# -*- coding: utf-8 -*-
"""
@time: 2018/12/26 11:47
@desc: 用于将mongostat工具的统计结果绘制为时间趋势图
"""
import os
import matplotlib.pyplot as plt
import numpy
import pandas
class Mongostat:
OPT_TYPE = ["insert", "query", "update", "delete", "net_in", "net_out"]
input_path = "E:/data/mongo/mongostat.log"
output_path = "E:/data/mongo"
def __init__(self, input_path, output_path):
self.input_path = input_path
self.output_path = output_path
def get_mongostat(self):
file = open(self.input_path)
file_list = file.readlines()
file.close()
for lineNum, line in enumerate(file_list):
if line.startswith("\n"): # 删除空白行
file_list.pop(lineNum)
mongo_infos = {"host": [], "insert": [], "query": [], "update": [], "delete": [], "net_in": [], "net_out": []}
for ele in file_list:
if ele.startswith("192.168"):
ele_list = ele.split()
if len(ele_list) != 4:
mongo_infos["host"].append(ele_list[0])
if ele_list[1].startswith("*"):
mongo_infos["insert"].append(int(ele_list[1][1:]))
else:
mongo_infos["insert"].append(int(ele_list[1]))
if ele_list[2].startswith("*"):
mongo_infos["query"].append(int(ele_list[2][1:]))
else:
mongo_infos["query"].append(int(ele_list[2]))
if ele_list[3].startswith("*"):
mongo_infos["update"].append(int(ele_list[3][1:]))
else:
mongo_infos["update"].append(int(ele_list[3]))
if ele_list[4].startswith("*"):
mongo_infos["delete"].append(int(ele_list[4][1:]))
else:
mongo_infos["delete"].append(int(ele_list[4]))
mongo_infos["net_in"].append(self.net_out_format(ele_list[15]))
mongo_infos["net_out"].append(self.net_out_format(ele_list[16]))
else:
mongo_infos["host"].append(ele_list[0])
mongo_infos["insert"].append(0)
mongo_infos["query"].append(0)
mongo_infos["update"].append(0)
mongo_infos["delete"].append(0)
mongo_infos["net_in"].append(0)
mongo_infos["net_out"].append(0)
return mongo_infos
def net_out_format(self, net_str: str):
if net_str.endswith("k"):
return float(net_str[:-1])
if net_str.endswith("b"):
return float(net_str[:-1]) / 1024
if net_str.endswith("m"):
return float(net_str[:-1]) * 1024
def drawing(self, stat_info):
"""
绘制图形,主要使用DataFrame.plot,并保存为png图片
:param stat_info: 监控信息的dict对象
:return:
"""
# hosts = set(stat_info["host"]) # 全部分片
hosts = ["192.168.0.101:26011", "192.168.0.102:26022", "192.168.0.103:26033"] # 主分片
data = {}
df = pandas.DataFrame(stat_info)
for host in hosts:
data[host] = df[df.loc[:, "host"] == host].reset_index(drop=True)
for opt in self.OPT_TYPE:
self.get_opo_df(data, hosts, opt)
self.get_all_opt(data, hosts, opt)
def get_opo_df(self, data, hosts, opt_type):
opt_data = {}
for host in hosts:
opt_data[host] = list(data[host].loc[:, opt_type])
opt_df = pandas.DataFrame(opt_data)
for host in hosts:
# df_filter = opt_df[opt_df.loc[:, host] < 20000].reset_index(drop=True)
# df_filter.plot(y=host, kind="line", rot=90, use_index=True, title=host)
opt_df.plot(y=host, kind="line", rot=90, use_index=True, title=host)
png_name = '%s.png' % host[-5:]
plt.savefig(self.output_path + os.sep + png_name) # 保存图片
def get_all_opt(self, data, hosts, opt_type):
"""
统计每个时间点的每个分片的opt_type类型的操作总量
:param data:
:param hosts:
:param opt_type:
:return:
"""
opt_data = {}
for host in hosts:
opt_data[host] = data[host].loc[:, opt_type]
sum_opt_series = pandas.DataFrame(opt_data).agg(numpy.sum, axis=1)
all_opt_df = pandas.DataFrame({"sum": sum_opt_series})
# TODO 测试分钟级、时级的统计结果
self.get_time_level_opt_sum(all_opt_df, opt_type, 60, "one_minute_")
self.get_time_level_opt_sum(all_opt_df, opt_type, 600, "ten_minute_")
self.get_time_level_opt_sum(all_opt_df, opt_type, 3600, "one_hour_")
df_filter = all_opt_df[all_opt_df.loc[:, "sum"] < 20000].reset_index(drop=True)
# df_filter = all_opt_df.reset_index(drop=True)
print("########%s-mean#########" % opt_type)
print(all_opt_df.agg(numpy.mean, axis=0))
title = "%s-sum" % opt_type
df_filter.plot(y="sum", kind="line", rot=90, use_index=True, title=title) # 配置画布大小
# all_opt_df.plot(y="sum", kind="line", rot=90, use_index=True, title=title, figsize=(10, 5)) # 配置画布大小
png_name = '%s.png' % title
plt.savefig(self.output_path + os.sep + png_name) # 保存图片
csv_name = '%s.csv' % title
df_filter.to_csv(self.output_path + os.sep + csv_name)
def get_time_level_opt_sum(self, opt_df: pandas.DataFrame, opt_type: str, time_level: int, file_name_prefix: str):
"""
计算不同时间粒度的操作数之和
:param opt_df:
:param opt_type:
:param time_level:
:param file_name_prefix:
:return:
"""
field = file_name_prefix + opt_type
title = "%s%s-sum" % (file_name_prefix, opt_type)
res = {field: []}
df_length = int(int(opt_df.size) / time_level)
for i in range(0, df_length + 1):
if (i + 1) * time_level <= opt_df.size:
one_minute_opt_count = opt_df.loc[i * time_level + 1:(i + 1) * time_level].agg(numpy.sum, axis=0)
else:
one_minute_opt_count = opt_df.loc[i * time_level + 1:int(opt_df.size)].agg(numpy.sum, axis=0)
res[field].append(one_minute_opt_count[0]) # 取第一个值
res_df = pandas.DataFrame(res)
res_df.plot(y=field, kind="line", rot=90, use_index=True, title=title)
png_name = '%s.png' % title
plt.savefig(self.output_path + os.sep + png_name) # 保存图片
if __name__ == "__main__":
input_file = "E:/data/mongo/log//kafka_maxrate_1/mongostat.log"
output_file = "E:/data/mongo"
mongostat = Mongostat(input_file, output_file)
mongostat_infos = mongostat.get_mongostat()
mongostat.drawing(mongostat_infos)