实践1:wordcount
1.1本地跑wordcount代码(无状态):
package com.badou.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
object wordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: wordCount <hostname> <port>")
System.exit(1)
}
val sparkConf = new SparkConf().setMaster("local[2]")setAppName("wordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
wordCounts.saveAsTextFiles("hdfs://master:9000/stream_out", "doc")
ssc.start()
ssc.awaitTermination()
}
}
测试及结果:
![]()

1.2打jar包在本地spark上跑:
去掉setmaster参数:![]()
在脚本上指定master,run.sh脚本:
运行脚本:![]()
1>代表标准输出
2>代表错误输出
实践2:wordcount(有状态)
有状态代码:

完整代码:
WordCountState.scala:
package com.badou.streaming
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
object WordCountState {
def updateFunction(currentValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val current = currentValues.sum
val pre = preValues.getOrElse(0)
Some(current + pre)
}
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: WordCountState <hostname> <port>")
System.exit(1)
}
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("hdfs://master:9000/hdfs_checkpoint")
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
//val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
val wordCounts = words.map(x => (x, 1)).updateStateByKey(updateFunction _)
wordCounts.print()
wordCounts.saveAsTextFiles("hdfs://master:9000/stream_stats_out", "doc")
ssc.start()
ssc.awaitTermination()
}
}
运行脚本(本地):

实践3:时间窗口(自带有状态,每十秒更新一次数据,更新的数据是30秒内的结果)
代码:windowTest.scala
package com.badou.streaming
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
object windowTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("windowTest")
val ssc = new StreamingContext(sparkConf, Seconds(10))
ssc.checkpoint("hdfs://master:9000/hdfs_checkpoint")
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow((v1: Int, v2:Int) => v1 + v2, Seconds(30), Seconds(10))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
提交脚本:

测试及结果:


数据有少变多,又由多变少
实践4:kafka+streaming(Receiver模式)
4.1kafka准备:
启动kafka:
![]()
创建topic:
![]()
发送数据:
![]()
4.2spark-streaming代码:

完整代码:wordcountKafkaStreaming.scala
package com.badou.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object wordcountKafkaStreaming {
def updateFunction(currentValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val current = currentValues.sum
val pre = preValues.getOrElse(0)
Some(current + pre)
}
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("wordcountKafkaStreaming").set("spark.cores.max", "8")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("hdfs://master:9000/hdfs_checkpoint")
val zkQuorum = "master:2181,slave1:2181,slave2:2181"
val groupId = "group_1"
// val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
// val topicAndLine: ReceiverInputDStream[(String, String)] =
// KafkaUtils.createStream(ssc, zkQuorum, groupId, topic, StorageLevel.MEMORY_ONLY)
// params: [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]
val topicAndLine: ReceiverInputDStream[(String, String)] =
KafkaUtils.createStream(ssc, zkQuorum, groupId,
Map("topic_1013" -> 1), StorageLevel.MEMORY_AND_DISK_SER)
val lines: DStream[String] = topicAndLine.map{ x =>
x._2
}
val words = lines.flatMap(_.split(" "))
//val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
val wordCounts = words.map(x => (x, 1)).updateStateByKey(updateFunction _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
启动脚本:

测试及结果:


实践5:kafka+streaming(Direct模式,无状态)
代码:

完整代码:
wordcountKafkaStreamingDirect.scala:
package com.badou.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
object wordcountKafkaStreamingDirect {
def main(args: Array[String]) {
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("wordcountKafkaStreamingDirect")
.set("spark.cores.max", "8")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val brokers = "192.168.87.10:9092";
val topics = "topic_1013";
val topicSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicSet)
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x=>(x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
实践6:kafka集成streaming(从kafka消息读,再从kafka消息输出):
6.1:producer开发,代码:
kafkaProducer.scala:
package com.badou.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
object kafkaProducer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaProducer")
val sc = new SparkContext(conf)
val array = ArrayBuffer("111","222","333")
ProducerSender(array)
}
def ProducerSender(args: ArrayBuffer[String]): Unit = {
if (args != null) {
// val brokers = "192.168.87.10:9092,192.168.87.11:9092,192.168.87.12:9092"
val brokers = "192.168.87.10:9092"
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
val topic = "topic_1013"
// Send some messages
for (arg <- args) {
println("i have send message: " + arg)
val message = new ProducerRecord[String, String](topic, null, arg)
producer.send(message)
}
Thread.sleep(500)
producer.close()
}
}
}
6.2.kafka启动消费者及结果:
![]()
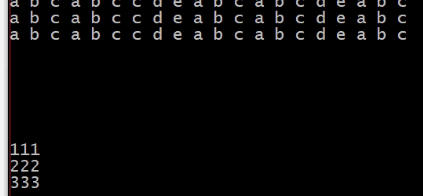
6.3实现kafka到streaming再到kafka的流程:

每个5秒完成一个批次
完整代码:
kafkaStreamKafka.scala:
package com.badou.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object kafkaStreamKafka {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("wordcountKafkaStreaming").set("spark.cores.max", "8")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("hdfs://master:9000/hdfs_checkpoint")
val zkQuorum = "master:2181,slave1:2181,slave2:2181"
val groupId = "group_1"
// val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
// val topicAndLine: ReceiverInputDStream[(String, String)] =
// KafkaUtils.createStream(ssc, zkQuorum, groupId, topic, StorageLevel.MEMORY_ONLY)
// params: [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]
val topicAndLine: ReceiverInputDStream[(String, String)] =
KafkaUtils.createStream(ssc, zkQuorum, groupId,
Map("topic_1013" -> 1), StorageLevel.MEMORY_AND_DISK_SER)
val lines: DStream[String] = topicAndLine.map{ x =>
x._2
}
val array = ArrayBuffer[String]()
lines.foreachRDD(rdd => {
val count = rdd.count().toInt
rdd.take(count + 1).take(count).foreach(x => {
array += x + "--read"
})
ProducerSender(array)
array.clear()
})
ssc.start()
ssc.awaitTermination()
}
def ProducerSender(args: ArrayBuffer[String]): Unit = {
if (args != null) {
// val brokers = "192.168.87.10:9092,192.168.87.11:9092,192.168.87.12:9092"
val brokers = "192.168.87.10:9092"
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
val topic = "topic_1013"
// Send some messages
for (arg <- args) {
println("i have send message: " + arg)
val message = new ProducerRecord[String, String](topic, null, arg)
producer.send(message)
}
Thread.sleep(500)
producer.close()
}
}
}
测试及结果:
