这是一个心情愉悦的周六下午,在免费给公司加了几个小时班后,突然想看电影了,但是作为一个junior engineer,我怎么能像那些senior engineer一样拿着轻松赚来毛爷爷去电影院挥霍呢?(看官COS:电影都舍不得看,还说的这么冠冕堂皇,真特么屌丝!)
首先我们先来学习一下复联4的英文名字Avengers: Endgame
Avengers: 复仇者
Endgame:最后阶段,尾声
那么从这里开始我们就称这个电影为AE吧。
AE上映于xxx年xx月xx日,导演XXX,算了我不编了,自己点击下方的链接进行阅读吧。
https://movie.douban.com/subject/26100958/
反正那几个演员的名字除了小罗伯特唐尼其他都记不住,因为这人演的钢铁侠据说原型是特斯拉的创始人XXX,好吧,其实记外国人的人名对我来说是有一定困难的。
收,下面正式开始我的用数据看电影之旅。
第一步 我们需要采集数据,这里就用爬虫来抓取豆瓣网的数据吧。
在爬取数据之前,需要先看一下网站上数据长什么样子,预估一下什么数据可以爬取到手。

上面这个截图出自之前的那个介绍链接,图中红色区域的数据是本次所必须爬取的数据,而黄色的则是Nice to have.
除了这个基本介绍页面,豆瓣还有一个专门的影评页面:
https://movie.douban.com/subject/26100958/reviews
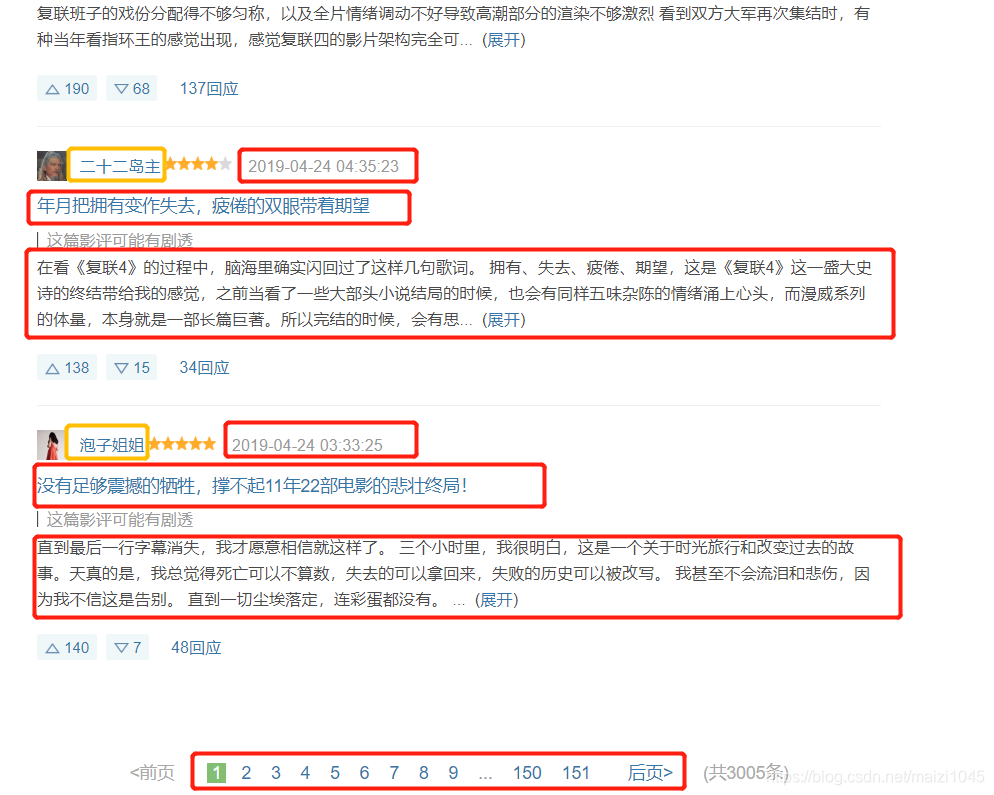
这里同样用红色和黄色的框框标出了需要爬取的数据。
好的,到这里第一步的目标就确定了,接下来用工具看一下豆瓣网页的源码。
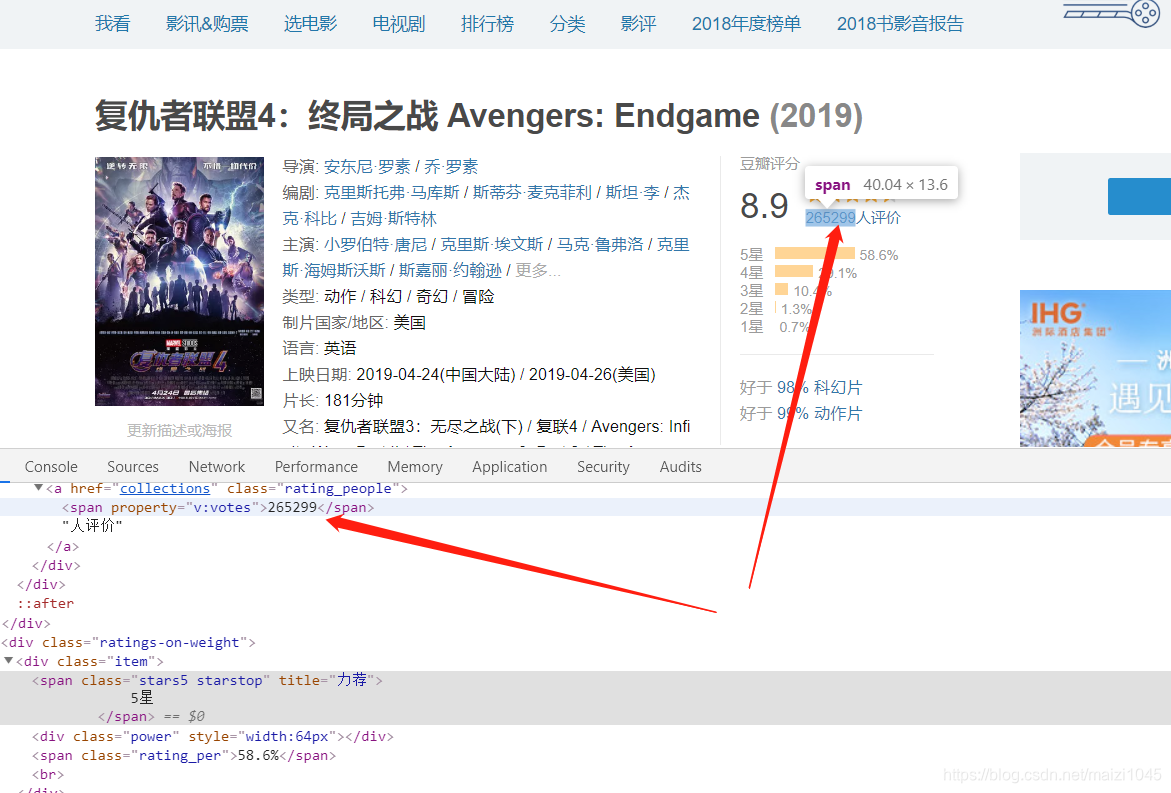
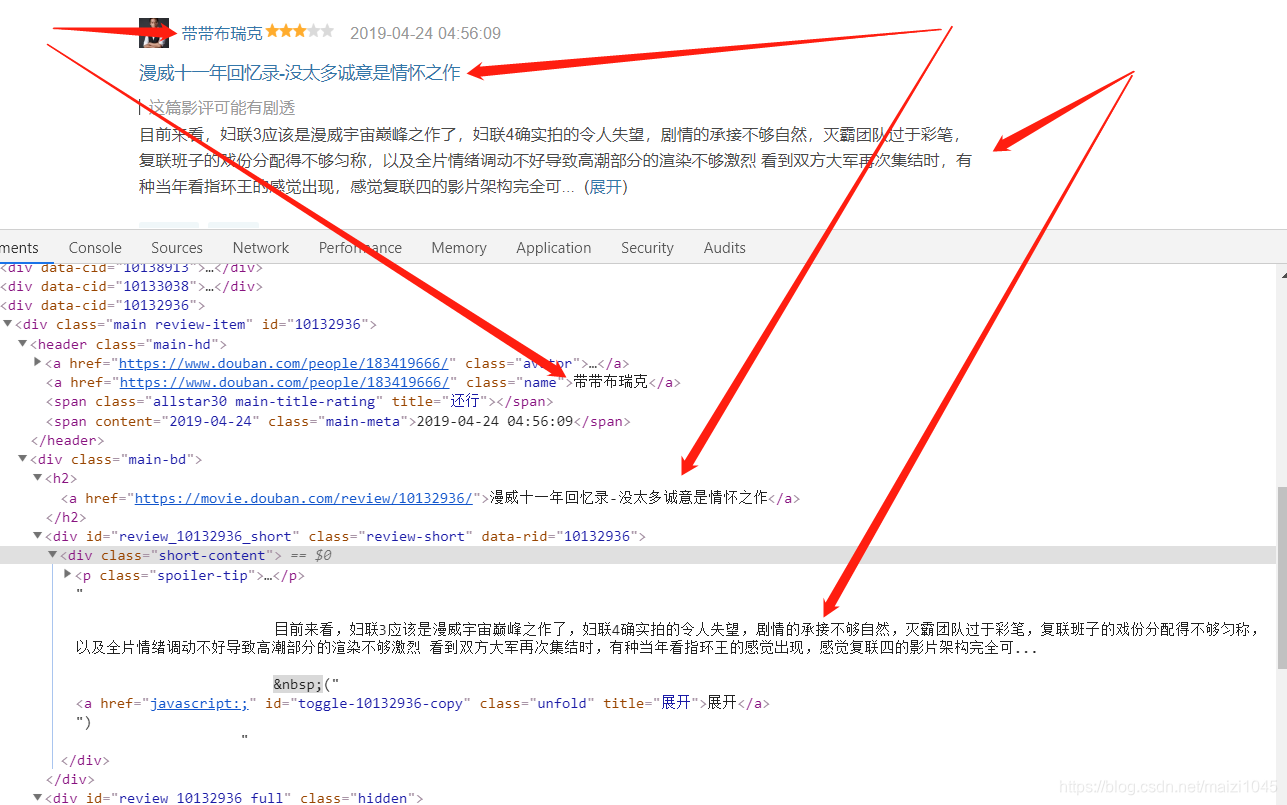
从源码来看基本上设定的目标数据都能够爬取到,除了那个影评的展开功能,那本次爬取就先不获取全部影评了。当然,目前的设想也是没有考量豆瓣网在反爬虫的技术所做的工作的。(非技术人员可以跳过这个部分了O(∩_∩)O哈哈~)
下面废话不多说,开始写爬虫(写完才发现豆瓣做了反爬虫,至今还没想到如何解决,但是小弟表示不服,这个flag先立在这了····)。
1. 获取自己的cookie

打开Chrome,找到开发者工具或者按F12,选到cookie标签页,输入document.cookie即可获得你自己这个时刻访问所使用的cookie,这个cookie只有几分钟的时效,会经常变,所以每次跑程序之前先获取一下这个cookie。
2. 爬取home页面的basic info
首先右键download一下这个页面,这样的话你在本地就可以看到源码,方便自己调试。
这里直接贴上爬取数据的代码,至于别的代码可以去我的GitHub上下载。
# 获取主页的的信息
def get_home_info(url):
html = get_html(url)
doc = pq(html)
# movie_name = doc('#content h1 span').text()
movie = doc('#content h1 span').items()
movie_info = [x.text() for x in movie]
final_rate = doc('.ll.rating_num').text()
total_people = doc('.rating_people span').text()
rating = doc('.item span').items()
rating_info = [x.text() for x in rating]
res = [movie_info, final_rate, total_people, rating_info]
return res
3. 爬取comments页面的user,time,comments
这个页面稍微复杂些,其实最大的问题还是那个只能访问12页的问题,希望各位大虾能够给点指导意见。
# return a dataframe
def parse_content(html):
doc = pq(html)
users = doc('.avatar a').items()
users_herf = doc('.avatar a').items()
comment_votes = doc('.comment-vote span').items()
comment_time = doc('.comment-time').items()
comment_content = doc('.comment-item p').items()
res_df = df(columns=['user_name', 'user_url', 'comment_votes', 'comment_time', 'comment_content'])
res_df['user_name'] = [u.attr('title') for u in users]
res_df['user_url'] = [h.attr('href') for h in users_herf]
res_df['comment_votes'] = [v.text() for v in comment_votes]
res_df['comment_time'] = [h.attr('title') for h in comment_time]
res_df['comment_content'] = [v.text() for v in comment_content]
return res_df
4. 爬取user主页的basic info
根据前面爬取到的user Home 页面的URL,再去爬取其的基础信息,这里只爬取了用户注册的地址。
# Get user's location
def get_user_info(url):
html = get_html(url)
doc = pq(html)
location = doc('.user-info a')
return location.text(), location.attr('href')
5. 针对主页的几个基本信息爬取
这一步其实是个多余的操作,主页我需要的信息也不是很多,直接写死也就好了。
但是你们觉得我会只曾这一部电影的热度吗?呵o( ̄︶ ̄)o,年轻人!!!
def get_home_info(url):
html = get_html(url)
doc = pq(html)
# movie_name = doc('#content h1 span').text()
movie = doc('#content h1 span').items()
movie_info = [x.text() for x in movie]
final_rate = doc('.ll.rating_num').text()
total_people = doc('.rating_people span').text()
rating = doc('.item span').items()
rating_info = [x.text() for x in rating]
res = [movie_info, final_rate, total_people, rating_info]
return res
第二部分 数据分析阶段