2-2(1)-4_创建、调整以及删除表格
#1 生成数据表结构
CREATE TABLE users(
user_id INT PRIMARY KEY,
name VARCHAR(20),
age INT,
city VARCHAR(20),
state VARCHAR(20),
monthly_active INT
#PRIMARY KEY(user_id),
);
# 描述下 表格结构
DESCRIBE users;
#2. 删除一个数据表
DROP TABLE users;
#3 调整一个数据表
ALTER TABLE users ADD gender CHAR(1);
ALTER TABLE users DROP COLUMN gender;
2-2(1)-5_为创建的表格插入数据
#1 像空表中插入数值
INSERT INTO users
VALUES
(1,'Jack',19,'Dallas','Texas',22),
(2,'Lucy',20,'Boston','Massachusetts',15),
(3,'Tom',13,'Los Angeles','California',8),
(4,'Alice',22,'San Jose','California',17),
(5,'Zhang',32,'Chicago','Illinois',22);
#选择表看一看
SELECT * FROM users;
#2 为Table加上一些限制
CREATE TABLE users2(
user_id INT,
name VARCHAR(20) NOT NULL,
age INT,
city VARCHAR(20) UNIQUE,
state VARCHAR(20),
monthly_active INT,
PRIMARY KEY(user_id)
);
#插入有空的
INSERT INTO users2 VALUES (1,NULL,19,'Dallas','Texas',22);
INSERT INTO users2 (user_id,age,city,state,monthly_active)
VALUES (1,19,'Dallas','Texas',22);
#插入不独特的
INSERT INTO users2 VALUES (1,'Tom',19,'Dallas','Texas',22);
INSERT INTO users2 VALUES (2,'Jerry',19,'Dallas','Texas',22);
DROP TABLE users2;
#3 为Table加上缺省值
CREATE TABLE users3(
user_id INT,
name VARCHAR(20) NOT NULL,
age INT,
city VARCHAR(20) DEFAULT 'unknown',
state VARCHAR(20),
monthly_active INT,
PRIMARY KEY(user_id)
);
INSERT INTO users3 (user_id,name,age,state,monthly_active)
VALUES (1,'Tom',19,'Texas',22);
# Auto增加主键,可以输入重复的进去了
CREATE TABLE users4(
user_id INT AUTO_INCREMENT,
name VARCHAR(20),
age INT,
city VARCHAR(20),
state VARCHAR(20),
monthly_active INT,
PRIMARY KEY(user_id)
);
INSERT INTO users4 (name,age,city,state,monthly_active) VALUES ('Jerry',19,'Dallas','Texas',22);
INSERT INTO users4 (name,age,city,state,monthly_active) VALUES ('Jerry',19,'Dallas','Texas',22);
INSERT INTO users4 (name,age,city,state,monthly_active) VALUES ('Jerry',19,'Dallas','Texas',22);
SELECT * FROM users4;
2-2(1)-6_更新和删除表格里的数据
SELECT * from users;
# Close safe 模式,在Myworkbench那个tab下preference下的SQL Editor,
# 把最后一项check去除,从新连接workbench。
#1 将California设置为CA
UPDATE users
SET state='CA'
WHERE state='California';
#将id=1的名字和年龄修改下
UPDATE users
SET name='Jackie',age=29
WHERE user_id=1;’
#2 删除符合某种条件的record
DELETE FROM users
WHERE user_id=4;
2-2(1)-7_基本SQL查询语句
# 重新构建users table
DROP TABLE users;
CREATE TABLE users(
user_id INT PRIMARY KEY,
name VARCHAR(20),
age INT,
city VARCHAR(20),
state VARCHAR(20),
monthly_active INT
#PRIMARY KEY(user_id),
);
INSERT INTO users
VALUES
(1,'Jack',19,'Dallas','Texas',22),
(2,'Lucy',20,'Boston','Massachusetts',15),
(3,'Tom',13,'Los Angeles','California',8),
(4,'Alice',22,'San Jose','California',17),
(5,'Zhang',32,'Chicago','Illinois',22);
####正式开始####
#1. SELECT Sentence
#全选
SELECT * FROM users;
#选名字变量
SELECT name FROM users;
#选多变量
SELECT name, age,city FROM users;
#
SELECT users.name, users.age
FROM users;
#2.Order语句排序
#排序
SELECT users.name, users.age
FROM users
ORDER BY name;
#多变量排序
SELECT *
FROM users
ORDER BY state,age;
#3 LIMIT 语句 选择出年龄最大用户记录
SELECT *
FROM users
ORDER BY age DESC
LIMIT 1;
#4 WHERE 语句,选出年龄在18到22间的人(包括18和22)
SELECT *
FROM users
WHERE age>=18 AND age<=22;
#或者写 WHERE age BETWEEN 18 AND 22; (包括18和22)
SELECT *
FROM users
WHERE age>=18 AND age<=22
ORDER BY age;
SQL实战
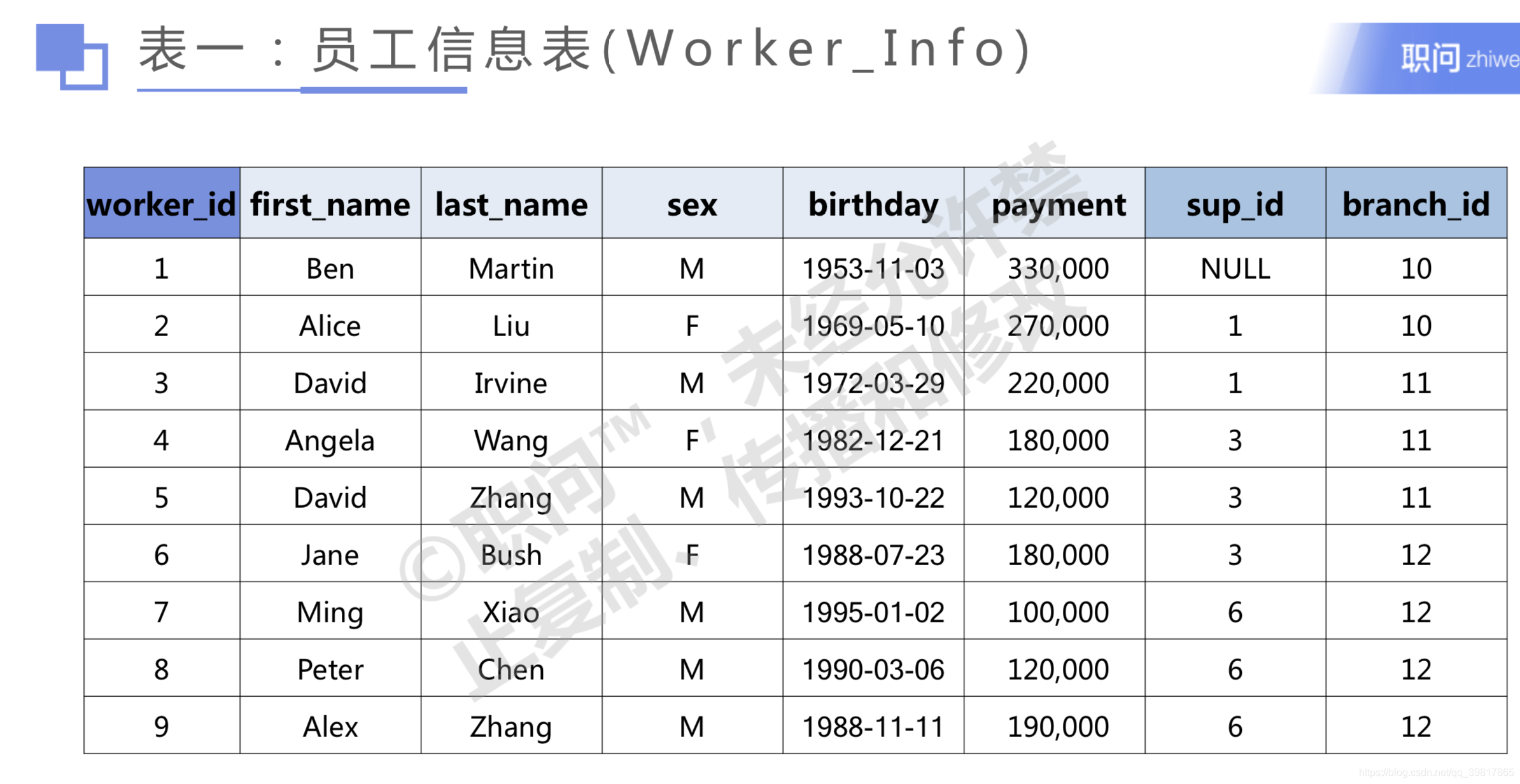
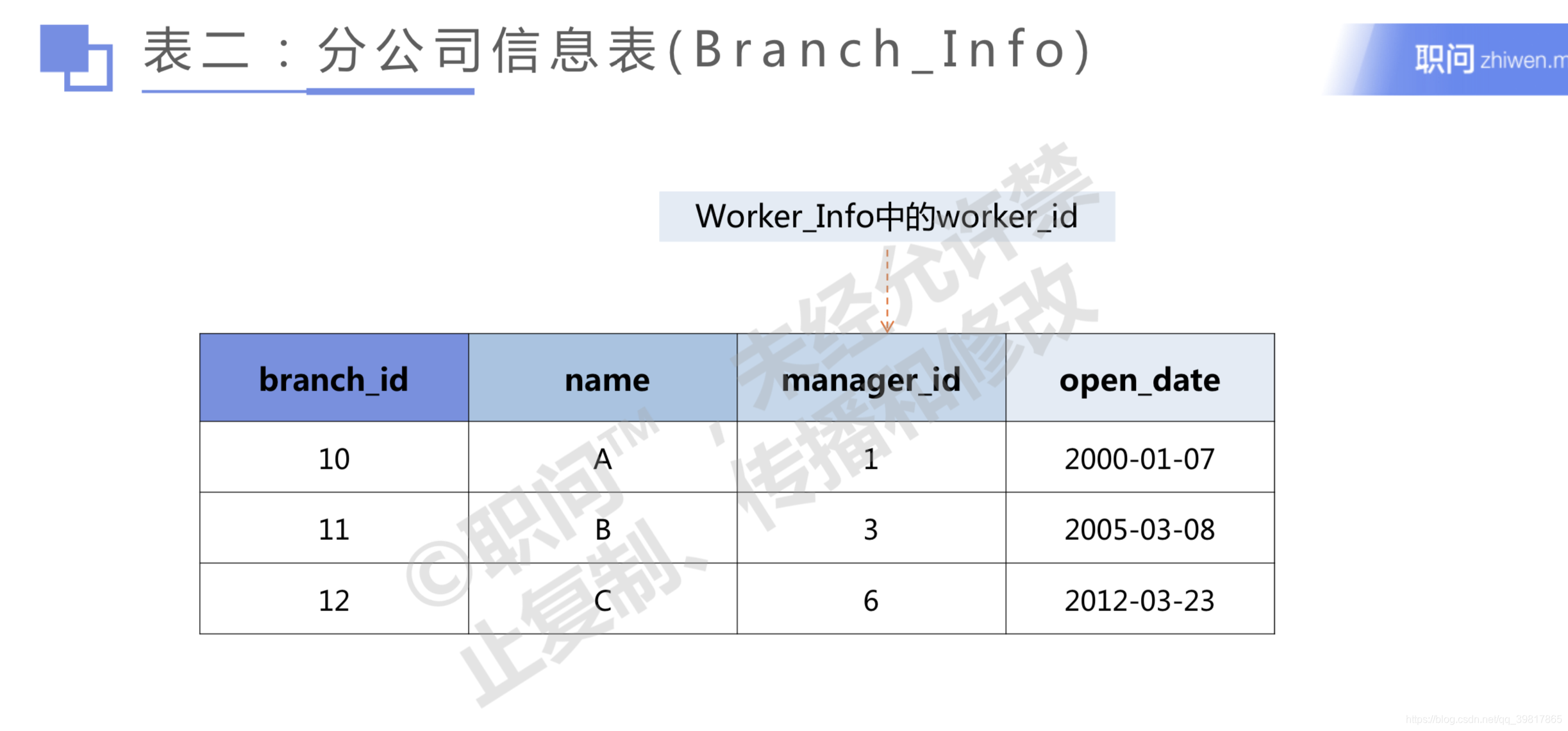
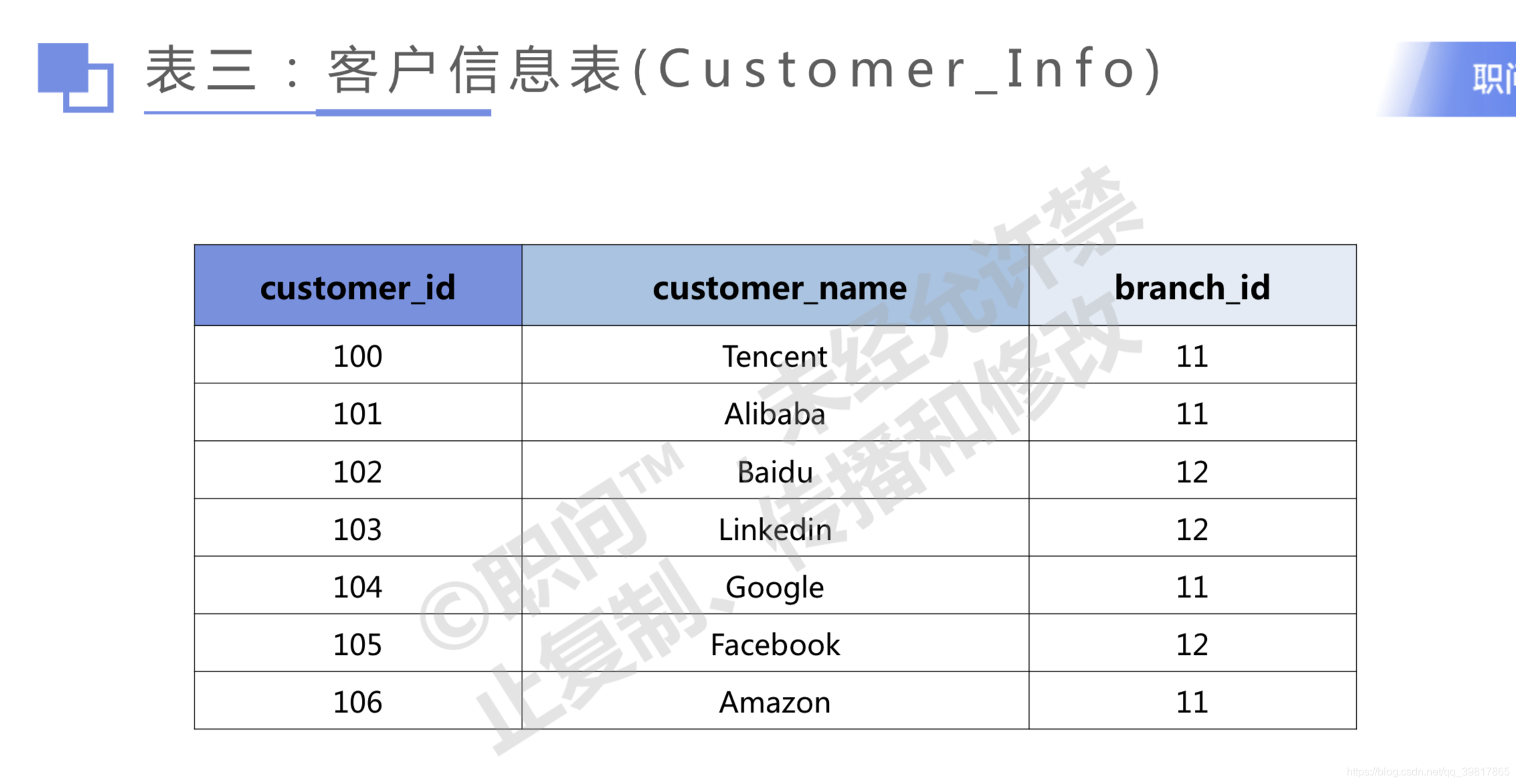


#Task 1 获取全部Worker_Info信息
SELECT *
FROM Worker_Info;
#Task 2 从Worker_Info中获取3到5号员工信息
SELECT *
FROM Worker_Info
WHERE worker_id in (3,4,5);
#Task 3 获取Worker_Info中表格员工的first_name,并按照最后两个字母进行升序排序(相同的按Worker_id)
SELECT first_name, worker_id
FROM Worker_Info
ORDER BY first_name, worker_id;
#Task 4 查找年龄最小的入职员工信息
SELECT *
FROM Worker_Info
ORDER BY birthday DESC
LIMIT 1;
#Task 5 查找年龄第三小的员工入职信息
SELECT *
FROM (SELECT *
FROM Worker_Info
ORDER BY birthday DESC
LIMIT 3) AS t
ORDER BY t.birthday
LIMIT 1;
#Task 6 获取所有非supervisors的员工编号(两种方法)
# 方法一:使用NOT IN
SELECT worker_id
FROM Worker_Info
WHERE worker_id NOT IN
(SELECT DISTINCT sup_id
FROM Worker_Info
WHERE sup_id IS NOT NULL);
# 方法二:用LEFT JOIN匹配没有被匹配到的就不是supervisor
#先看看Join后的效果
SELECT t1.worker_id,t2.sup_id
FROM Worker_Info as t1
LEFT JOIN
(SELECT DISTINCT sup_id as sup_id FROM Worker_Info) as t2
ON (t1.worker_id=t2.sup_id);
#正式写
SELECT t1.worker_id
FROM Worker_Info as t1
LEFT JOIN
(SELECT DISTINCT sup_id as sup_id FROM Worker_Info) as t2
ON (t1.worker_id=t2.sup_id)
WHERE t2.sup_id IS NULL;
# Task 7获取所有员工编号为偶数的员工信息
SELECT * FROM Worker_Info
WHERE MOD(worker_id,2)=0;
SELECT * FROM Worker_Info
WHERE worker_id%2=0;
# Task 8找出每个员工的销售额,NULL记为0
# t2表格group每个有销售额的员工销售总和,中间的t3为了处理NULL视作0的问题,然后拿出来在做一层
SELECT t3.worker_id,t3.total/t3.payment as ratio
FROM
(SELECT t1.worker_id,
(CASE
WHEN t2.total IS NULL THEN 0
ELSE t2.total
END) as total,t1.payment
FROM Worker_Info as t1
LEFT JOIN
(SELECT worker_id, SUM(total_revenue) as total
FROM Sales_Info
GROUP BY worker_id) as t2
ON(t1.worker_id=t2.worker_id)) as t3
ORDER BY ratio DESC;
# Task 9找出公司最大客户的名字
#先试试select * 给大家看
SELECT t2.customer_name,t1.total
#2
FROM Customer_Info as t2
INNER JOIN
#1
(SELECT customer_id, SUM(total_revenue) as total
FROM Sales_Info
GROUP BY customer_id) as t1
ON (t1.customer_id=t2.customer_id)
#3
ORDER BY t1.total DESC
LIMIT 1;
# date|post_id|action{open, close, report}|user_id|reason
#建立需要数据
CREATE TABLE view_post(
id INT AUTO_INCREMENT,
date DATE,
post_id INT,
action VARCHAR(10),
user_id INT,
reason VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (id)
);
INSERT INTO view_post (date,post_id,action,user_id,reason)
VALUES ('2010-10-20',1,'open',5,NULL),
('2010-10-20',1,'close',5,NULL),
('2010-10-20',2,'open',3,NULL),
('2010-10-20',2,'report',3,'SPAM'),
('2010-10-20',2,'close',3,NULL),
('2010-10-20',2,'open',5,NULL),
('2010-10-20',2,'report',5,'Advertising'),
('2010-10-20',2,'close',5,NULL),
('2010-10-20',3,'open',4,NULL),
('2010-10-20',3,'report',4,'SPAM'),
('2010-10-20',3,'close',4,NULL),
('2010-10-20',4,'open',5,NULL),
('2010-10-20',4,'report',5,'SPAM'),
('2010-10-20',4,'close',5,NULL),
('2010-10-20',4,'open',6,NULL),
('2010-10-20',4,'report',6,'SPAM'),
('2010-10-20',5,'open',3,NULL),
('2010-10-20',5,'report',3,'Inappropriate Content'),
('2010-10-19',5,'open',1,NULL),
('2010-10-19',5,'report',1,'Inappropriate Content'),
('2010-10-19',2,'report',5,'Advertising'),
('2010-10-19',2,'close',5,NULL),
('2010-10-19',3,'open',4,NULL),
('2010-10-19',3,'report',4,'SPAM'),
('2010-10-19',3,'close',4,NULL);
#越讲越简单,不断带大家看表的中间结果
# 方法一
SELECT * from view_post
WHERE reason is not NULL AND date='2010-10-20';
#多变量group其实就是去重操作
SELECT t1.post_id,t1.reason FROM
(SELECT * from view_post
WHERE reason is not NULL AND date='2010-10-20') as t1
GROUP BY t1.post_id,t1.reason;
SELECT t2.reason,count(t2.reason) FROM
(SELECT t1.post_id,t1.reason FROM
(SELECT * from view_post
WHERE reason is not NULL AND date='2010-10-20') as t1
GROUP BY t1.post_id,t1.reason) as t2
GROUP BY t2.reason;
#方法二
SELECT DISTINCT date,post_id,action,reason
FROM view_post;
SELECT DISTINCT date,post_id,action,reason
FROM view_post;
WHERE action='report' AND date='2010-10-20';
SELECT t.reason,COUNT(t.reason) FROM
(SELECT DISTINCT date,post_id,action,reason
FROM view_post
WHERE reason IS NOT NULL AND date='2010-10-20') as t
GROUP BY t.reason;
#方法三
#先带大家看一下表的临时结果
SELECT *
FROM view_post
WHERE date='2010-10-20'
AND action='report';
#再group by reason,看每个reason下 "不同" 的post_id
SELECT reason, COUNT(DISTINCT post_id)
FROM view_post
WHERE date='2010-10-20'
AND action='report'
GROUP BY reason;
# 表一 adv_info:advertiser_id | ad_id | spend
# 表二 ad_id | payment
#建立需要数据,为了方便就不涉及主键外键
CREATE TABLE adv_info(
advertiser_id INT,
ad_id INT,
spend INT
);
CREATE TABLE ad_info(
ad_id INT,
payment INT
);
INSERT INTO adv_info
VALUES
(1,1,10000),
(1,2,5000),
(2,3,20000),
(3,4,30000),
(3,5,1000),
(4,6,100),
(5,7,0);
INSERT INTO ad_info
VALUES
(1,10000),
(2,12000),
(1,10000),
(3,60000),
(4,20000),
(5,3000),
(5,200),
(4,2000),
(6,0),
(7,0);
#1. 求广告上花费最高的雇主
SELECT advertiser_id, SUM(spend) as total_spend
FROM adv_info
GROUP BY total_spend
LIMIT 1;
#2. 求至少一次conversion的advertiser占总体百分比
#这里面从新命名是为了避免到后面临时表格中出现两个ad_id而无法select *
#查找每个广告的总收入
SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2
#将广告收入和广告主去匹配
SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id)
#统计每个广告主收入
SELECT t3.advertiser_id, sum(t3.total_payment) as total_payment
FROM
(SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id)) as t3
GROUP BY t3.advertiser_id
#计算那些有收入的/全部广告主
SELECT SUM(CASE WHEN t4.total_payment!=0 THEN 1 ELSE 0 END)/COUNT(advertiser_id) as ratio
FROM
(SELECT t3.advertiser_id, sum(t3.total_payment) as total_payment
FROM
(SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id)) as t3
GROUP BY t3.advertiser_id) as t4;
#3 求每个广告主(advertiser)的ROI(回报率,就是payment/spend)
#根据上一题,我们看看t3是什么表
SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id);
# 直接按advertiser_id进行group,每个广告主用总收入/总费用
SELECT t3.advertiser_id, SUM(t3.total_payment)/SUM(t3.spend) as ROI
FROM
(SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id)) as t3
GROUP BY t3.advertiser_id;
#仅仅是为了将除以0以后是NULL的雇主变成文字‘unsure’.
SELECT t4.advertiser_id, (CASE WHEN t4.ROI is NULL THEN 'unsure' ELSE t4.ROI END) as ROI
FROM
(SELECT t3.advertiser_id, SUM(t3.total_payment)/SUM(t3.spend) as ROI
FROM
(SELECT *
FROM adv_info as t2
LEFT JOIN
(SELECT ad_id as ad_id2,SUM(payment) as total_payment
FROM ad_info
GROUP BY ad_id2) as t1
ON(t1.ad_id2=t2.ad_id)) as t3
GROUP BY t3.advertiser_id) as t4;
牛客网习题汇总:
1.查找入职员工时间排名倒数第三的员工所有信息
select * from employees order by hire_date desc limit 2,1;
数据如下:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no
select salaries.emp_no,salaries.salary,salaries.from_date,salaries.to_date,dept_manager.dept_no
from salaries inner join dept_manager
on dept_manager.emp_no = salaries.emp_no
and dept_manager.to_date = '9999-01-01'
and salaries.to_date = '9999-01-01';
select s.* ,d.dept_no
from salaries as s
join dept_manager as d
on s.emp_no=d.emp_no
where s.to_date = '9999-01-01'
and d.to_date='9999-01-01';
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
