第十一章 如何确定网页和查询的相关性
如今影响搜索引擎质量(除了点击数据之外)的四大类:
1.完备的索引
2.对网页质量的度量
3.用户偏好
4.确定一个网页和某个查询的相关性的方法
1 搜索关键词权重的科学度量TF-IDF
度量网页和查询的相关性,有一个简单的方法,就是直接使用各个关键在网页中出现的总词频。
即TF1 + TF2 + ... + TFN
当然,要去除“停止词”(stop word)。例如“的”这样的词
词与词的权重也不同,这个权重的设定必须满足两个条件:
①一个词预测主题的能力越强,权重越大,反之,越小。
②停止词的权重为零。
如果一个词只在很少的网页中出现,通过它很容易锁定搜索目标,它的权重就大。反之,就小。
在信息检索中,使用最多的权重是“逆文本频率指数”(Inverse Document Frequency,IDE),公式为log(D/Dw),其中D是全部网页数。
利用IDE,相关性计算的公式就由词频的简单求和变成了加权求和,即
TF1*IDE1 + TF2*IDE2 + ... + TFN*IDEN
IDE的概念就是一个特定条件下关键词的概率分布的交叉熵(Kullback-Leibler Divergence)
2 延伸阅读:TF-IDF的信息论依据
一个查询中每一个关键词w的权重应该反映这个词对查询来讲提供了多少信息。
简单的方法就是用每个词的信息量作为它的权重,即:
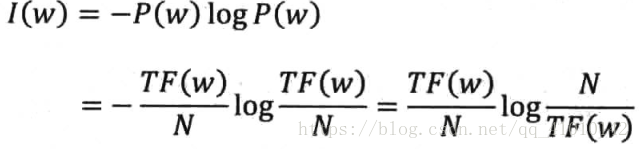
其中,N是整个语料库的大小,是个可以省略的常数。上面的公式可以简化成:
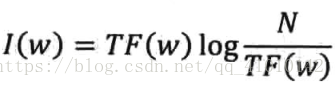
上述公式存在一个缺陷就是无法反应关键词的分辨率(两个关键词的TF相同)
做一些理想的假设:
①每个文献的大小基本相同,均为M个词,即
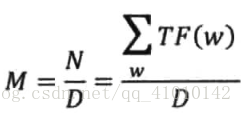
②一个关键词在文献一旦出现,不论多少次,贡献等同,这样一个词要么在一个文献中出现c(w)= TF(w)/D(w)次,要么为零。注意,c(w) < M。那么:

推出:

可以得出,一个词的信息量I(w)越多,TF-IDF值就越大;同时w命中的文献中w平均出现的次数越多,第二项越小,TF-IDF也越大。