




如果关闭了一个索引之后,那么这个索引是不会带来任何的性能开销了,只要保留这个索引的元数据即可,然后对这个索引的读写操作都不会成功。一个关闭的索引可以接着再打开,打开以后会进行shard recovery过程。比如说你在做一些运维操作的时候,现在你要对某一个索引做一些配置,运维操作,修改一些设置,关闭索引,不允许写入,成功以后再打开索引
压缩索引:
shrink命令可以将一个已有的索引压缩成一个新的索引,同时primary shard会更少。如果要减少index的primary shard,可以用shrink命令来压缩index。但是压缩后的shard数量必须可以被原来的shard数量整除。举例,一个有8个primary shard的index可以被压缩成4个,2个,或者1个primary shard的index。如果你的索引中本来比如是要保留7天的数据,那么给了10个shard,但是现在需求变了,这个索引只要保留3天的数据就可以了,那么数据量变小了,就不需要10个shard了,就可以做shrink操作,5个shard。
shrink命令的工作流程如下:
(1)首先,它会创建一个跟source index的定义一样的target index,但是唯一的变化就是primary shard变成了指定的数量
(2)接着它会将source index的segment file直接用hard-link的方式连接到target index的segment file,如果操作系统不支持hard-link,那么就会将source index的segment file都拷贝到target index的data dir中,会很耗时。如果用hard-link会很快
(3)最后,会将target index进行shard recovery恢复
如果要shrink index,那么这个index必须先被标记为read only,而且这个index的每个shard的某一个copy,可以是primary或者是replica,都必须被复制到一个节点上去。默认情况下,index的每个shard有可能在不同机器上的,比如说,index有5个shard,shard0和shard1在机器1上,shard2、shard3在机器2上,shard4在机器3上。现在还得把shard0,shard1,shard2,shard3,shard4全部拷贝到一个同一个机器上去,但是可以是shard0的replica shard。而且每个primary shard都必须存在。可以通过下面的命令来完成。其中index.routing.allocation.require._name必须是某个node的名称,这个都是可以自己设置的。

这个命令会花费一点时间将source index每个shard的一个copy都复制到指定的node上去,可以通过GET _cat/recovery?v命令来追踪这个过程的进度。等上面的shard copy relocate过程结束之后,就可以shrink一个index,用下面的命令即可:POST my_source_index/_shrink/my_target_index。如果target index被添加进了cluster state之后,这个命令就会立即返回,
不是等待shrink过程完成之后才返回的。当然还可以用下面的命令来shrink的时候修改target index的设置,在settings里就可以设置target index的primary shard的数量。

当然也是需要监控整个shrink的过程的,用GET _cat/recovery?v即可。
rollover index:
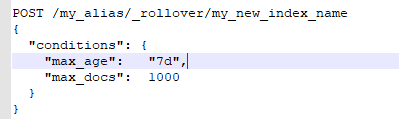
rollover命令可以将一个alias重置到一个新的索引上去,如果已经存在的index被认为太大或者数据太旧了。这个命令可以接收一个alias名称,还有一系列的condition。如果索引满足了condition,那么就会创建一个新的index,同时alias会指向那个新的index。比如下面的命令。举例来说,有一个logs-0000001索引,给了一个别名是logs_write,接着发起了一个rollover的命令,如果logs_write别名之前指向的那个index,也就是logs-0000001,创建了超过7天,或者里面的document已经超过了1000个了,然后就会创建一个logs-000002的索引,同时logs_write别名会指向新的索引。这个命令其实是很有用的,特别是针对这种用户访问行为日志的数据,或者是一些联机事务系统的数据的进入,你可以写一个shell脚本,每天0:00的时候就执行以下rollover命令,此时就判断,如果说之前的索引已经存在了超过1天了,那么此时就创建一个新的索引出来,同时将别名指向新的索引。自动去滚动创建新的索引,保持每个索引就只有一个小时,一天,七天,三天,一周,一个月。类似用es来做日志平台,就可能分布式电商平台,可能订单系统的日志,单独的一个索引,要求的是保留最近3天的日志就可以了。交易系统的日志,是单独的一个索引,要求的是保留最近30天的日志。
先创建了一个索引:

添加几数据:



开始rollover并添加条件


mapping管理

添加索引别名


删除别名

index template管理
我们可以定义一些index template,这样template会自动应用到新创建的索引上去。template中可以包含settings和mappings,还可以包含一个pattern,决定了template会被应用到哪些index上。而且template仅仅在index创建的时候会被应用,
修改template,是不会对已有的index产生影响的。

indice stat
indice stat对index上发生的不同类型的操作都提供了统计。这个api提供了index level的统计信息,不过大多数统计信息也可以从node level获取。
curl -XGET 'http://192.168.93.129:9200/twitter/_stats?pretty'
curl -XGET 'http://192.168.93.129:9200/twitter/_segments?pretty'
shard存储信息
curl -XGET 'http://192.168.93.129:9200/twitter/_shard_stores?pretty'
curl -XGET 'http://192.168.93.129:9200/twitter/_shard_stores?status=green&pretty'
curl -XPOST 'http://192.168.93.129:9200/twitter/_cache/clear?pretty',这个命令可以清空所有的缓存
flush API可以让我们去强制flush多个索引,索引flush以后,就会释放掉这个索引占用的内存,因为会将os cache里的数据强制fsync到磁盘上去,同时还会清理掉translog中的日志。默认情况下,es会不定时自动触发flush操作,以便于及时清理掉内存。POST twitter/_flush,这条命令即可。
flush命令可以接受下面两个参数,wait_if_going,如果设置为true,那么flush api会等到flush操作执行完以后再返回,即使需要等待其他的flush操作先完成。默认的值是false,这样的话,如果有其他flush操作在执行,就会报错;force,如果没有必要flush的话,是不是会强制一个flush
curl -XPOST 'http://192.168.93.129:9200/twitter/_flush?pretty'
refresh
refresh用来显式的刷新一个index,这样可以让这个refresh之前执行的所有操作,都处于可见的状态。POST twitter/_refresh
curl -XPOST 'http://192.168.93.129:9200/twitter/_refresh?pretty'
force merge
force merge API可以强制合并多个索引文件,可以将一个shard对应的lucene index的多个segment file都合并起来,可以减少segment file的数量。POST /twitter/_forcemerge。
curl -XPOST 'http://192.168.93.129:9200/twitter/_forcemerge?pretty'
1、circuit breaker
es有很多的断路器,也就是circuit breaker,可以用来阻止各种操作导致OOM内存溢出。每个断路器都有一个限制,就是最多可以使用多少内存。此外,还有一个父断路器指定了所有断路器最多可以使用多少内存。
(1)父短路器
indices.breaker.total.limit,可以配置父短路器的最大内存限制,默认是jvm heap内存的70%
(2)fielddata短路器
field data短路器可以估算每一个field的所有数据被加载到内存中,需要耗费多大的内存。这个短路器可以组织field data加载到jvm内存时发生OOM问题。默认的值是jvm heap的60%。indices.breaker.fielddata.limit,可以用这个参数来配置。indices.breaker.fielddata.overhead,可以配置估算因子,估算出来的值会乘以这个估算因子,留一些buffer,默认是1.03。
(3)request circuit breaker
request circuit breaker会阻止每个请求对应的一些数据结构造成OOM,比如一个聚合请求可能会用jvm内存来做一些汇总计算。indices.breaker.request.limit,最大是jvm heap的60%。indices.breaker.request.overhead,估算因子,默认是1.
(4)in flight request circuit breaker
flight request circuit breaker可以限制当前所有进来的transport或http层的请求超出一个节点的内存总量,这个内存的使用量就是请求自己本身的长度。network.breaker.inflight_requests.limit,默认是jvm heap的100%。network.breaker.inflight_requests.overhead,估算因子,默认是1.
(5)script compilation circuit breaker
这个短路器可以阻止一段时间内的inline script编译的数量。script.max_compilations_per_minute,默认是1分钟编译15个。
2、fielddata
fielddata cache,在对field进行排序或者聚合的时候,会用到这个cache。这个cache会将所有的field value加载到内存里来,这样可以加速排序或者聚合的性能。但是每个field的field data cache的构建是很成本很高昂的,因此建议给机器提供充足的内存来保持fielddata cache。
indices.fielddata.cache.size,这个参数可以控制这个cache的大小,可以是30%这种相对大小,或者是12GB这种绝对大小,默认是没有限制的。
fielddata的原理之前讲解过了,其实是对分词后的field进行排序或者聚合的时候,才会使用fielddata这种jvm内存数据结构。如果是对普通的未分词的field进行排序或者聚合,其实默认是用的doc value数据结构,是在os cache中缓存的。
3、node query cache
query cache用来缓存query的结果,每个node都有一个query cache,使用的是LRU策略,会自动清理数据。但是query cache仅仅会对那些filter后的数据进行缓存,对search后的数据是不会进行缓存的。indices.queries.cache.size,控制query cache的大小,默认是jvm heap的10%。
如果只是要根据一些field进行等值的查询或过滤,那么用filter操作,性能会比较好,query cache
4、index buffer
index buffer用来存储最新索引的的document。如果这个buffer满了之后,document就会被写入一个segment file,但是此时其实是写入os cache中,没有用fsync同步到磁盘,这就是refresh过程,写入os cache中,就可以被搜索到了。然后flush之后,就fsync到了磁盘上。indices.memory.index_buffer_size,控制index buffer的大小,默认是10%。indices.memory.min_index_buffer_size,buffer的最小大小,默认是48mb。
index buffer,增删改document,数据先写入index buffer,写到磁盘文件里面去,不可见的,refresh刷入磁盘文件对应的os cache里面,还有translog一份数据
5、shard request cache
对于分布式的搜索请求,相关的shard都会去执行搜索操作,然后返回一份结果集给一个coordinate node,由那个coordinate node来执行最终的结果合并与计算。shard request cache会缓存每个shard的local result。那么对于频繁请求的数据,就可以直接从cache中获取了。与query cache不同的是,query cache只是针对filter的,但是shard request cache是针对所有search和聚合求的。
默认情况下,shard request cache仅仅会针对size=0的搜索来进行缓存,仅仅会缓存hits.total,聚合结果等等汇总结果,而不会缓存搜索出来的hits明细数据。
cache是很智能的,如果cache对应的doc数据被refresh,也就是修改了,那么cache就会自动失效。如果cache满了的话,也会自动用LRU算法来清理掉cache中的数据。
可以手动来启用和禁用cache:
PUT /my_index
{
"settings": {
"index.requests.cache.enable": false
}
}
在每个request中也可以手动启用或禁用cache:
GET /my_index/_search?request_cache=true
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "colors"
}
}
}
}
但是默认对于size>0的request的结果是不会被cache的,即使在index设置中启用了request cache也不行。只有在请求的时候,手动加入reqeust cache参数,才可以对size>0的请求进行result cache。
缓存用的key,是完整的请求json,因此每次请求即使json中改变了一点点,那么也无法复用上次请求的request cache结果。
indices.requests.cache.size,可以设置request cache大小,默认是1%
GET /_stats/request_cache?human,监控request cache的使用
如果是search,默认是不缓存的,除非你手动打开request_cache=true,在发送请求的时候
如果是aggr,默认是缓存的,不手动打开request_cache=true,也会缓存聚合的结果
6、索引恢复
indices.recovery.max_bytes_per_sec,每秒可以恢复的数据量,默认是40mb
1、merge
es里的一个shard,就是一个lucene index,每个lucene index都是由多个segment file组成的。segment file负责存储所有的document数据,而且segment file是不可变的。一些小的segment file会被merge成一个大的segment file,这样可以保证segment file数量不会膨胀太多,而且可以将删除的数据实际上做物理删除。merge过程会自动进行throttle限流,这样可以让merge操作和节点上其他的操作都均衡使用硬件资源。
merge scheduler会控制merge的操作什么时候执行,merge操作会在一些独立的后台线程中执行,如果达到了最大的线程数量的话,那么merg操作就会等待有空闲的线程出来再去执行。index.merge.scheduler.max_thread_count,这个参数可以控制每次merge操作的最大线程数量,默认的公式是Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)),对于SSD来说,表现是很好的。但是如果我们使用的是机械硬盘,建议将这个数量降低为1。
2、translog
(1)translog介绍
对lucene的磁盘持久化,可以通过一次lucene commit来提交,是一个很重的过程,所以是不可能在每次插入或者删除操作过后来执行的。所以在上一次提交和下一次提交之间的数据变更,都是在os cache中的,如果机器挂掉,可能导致数据丢失。为了避免这种数据丢失,每个shard都有一个transaction log,也就是translog,来写入write ahead log,预写日志。任何写入数据都会同时被写入translog。如果机器挂掉了,那么就可以重放translog中的日志来恢复shard中的数据。
一次es flush操作,都会执行一次lucene commit,将数据fsync到磁盘上去,同时清空translog文件。在后台会自动进行这个操作,来确保translog日志不会增长的太过于巨大,这样的话重放translog数据来恢复,才不会太慢。index.translog.flush_threshold_size,这个参数可以设置os cache中数据达到多大的时候,要执行一次flush,默认是512mb。
(2)translog设置
此外,默认情况下,es每隔5秒钟会在每个增删改操作结束之后,对translog进行一次fsync操作,但是要求index.translog.durability设置为async或者request(默认)。es只有在primary和每一个replica shard的translog fsync之后,才会对增删改操作返回的状态中显示为success。
index.translog.sync_interval:不考虑些操作,translog被fsync到磁盘的频率,默认是5秒
index.translog.durability:是否要在每次增删改操作之后,fsync translog。
默认是request,每次写请求之后,都会fsync translog,这样的话,即使机器宕机,但是只要是返回success的操作,就意味着translog被fsync到磁盘了,就可以保证数据不丢失
async,在后台每隔一定时间来fsync translog,默认是5秒,机器宕机的时候,可能导致5秒的数据丢失,可能有5秒钟的数据,数据本身是停留在os cache中的,数据对应的translog也停留在os cache中,5秒才能将translog从os cache输入磁盘
(3)translog损坏怎么办
如果硬盘损坏,可能导致translog出现损坏,es会自动通过checksum来捕获到这个问题,此时es就会认为这个shard故障了,而且禁止将shard分配给这个node,同时会尝试从其他replica shard来恢复数据。如果没有replica数据的话,那么用户可以手动通过工具来恢复,使用elasticsearch-translog即可。要注意的是,elasticsaerch-translog工具不能再elasticsearch运行的时候来使用,否则我们可能丢失数据。
bin/elasticsearch-translog truncate -d /var/lib/elasticsearchdata/nodes/0/indices/P45vf_YQRhqjfwLMUvSqDw/0/translog/
Checking existing translog files