原数据(前2行):
"1",2683657840,140100,"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36 SE 2.X MetaSr 1.0","Windows XP","785022225.1422973265","785022225.1422973265",1422973268278,"2015-02-03
22:21:08","/info/hunyin/hunyinfagui/201404102884290_6.html",20150203,"http://www.lawtime.cn/info/hunyin/hunyinfagui/201404102884290_6.html","107001","www.lawtime.cn","广东省人口与计划生育条例全文2014 - 法律快车婚姻法",31,"故意伤害","计划生育",NA,NA,NA,NA
"2",973705742,140100,"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36","Windows 7","2048326726.1422973286","2048326726.1422973286",1422973268308,"2015-02-03 22:21:08","/ask/exp/17199.html",20150203,"http://www.lawtime.cn/ask/exp/17199.html","1999001","www.lawtime.cn","非广州户籍人员可以在广州申请出入境证件吗? - 法律快车法律经验",20,"劳资纠纷","出入境","baidu","http://www.baidu.com/s?wd=%E9%9D%9E%E5%B9%BF%E5%B7%9E%E6%88%B7%E7%B1%8D%E4%BA%BA%E5%91%98%E6%80%8E%E4%B9%88%E7%94%B3%E8%AF%B7%E9%A2%84%E7%BA%A6%E5%87%BA%E5%85%A5%E5%A2%83&ie=utf-8","非广州户籍人员怎么申请预约出入境","baidu"
预处理
将原数据中的无用数据及数据中的“,”去除,避免导入数据库时将其分辨为分割符
#!/bin/bash
infile=$1
outfile=$2
#sed 's/"\([^",]*\),\([^"]*\)"/"\1;\2"/g' $infile > $outfile
awk -F "\"" '{
str = $1;
for(i=2; i<=3;i++){ str = str$i };
for(i=5; i<=NF;i++){ str = str$i };
print str;
}' $infile > tempfile1
awk -F "," 'BEGIN{
}
{
str = $1
for(i=2; i<=3; i++){ str = str"\t"$i };
for(i=5; i<=NF; i++){ str = str"\t"$i };
print str;
}' tempfile1 > $outfile
#sed 's/\"//g' tempfile2 > $outfile
rm tempfile1
#rm tempfile2
导入到HDFS、HIVE、MYSQL
数据探索分析
针对原始数据中用户点击的网页类型进行统计

可以得到用户点击的页面类型的排行榜,可以初步得出用户更喜欢浏览咨询性页面
网页类型分析
对于101开头的咨询类型,浏览101003(内容页)最多

对于107开头的只是类型,知识内容页最多

网页存在带”?”的情况,共有65477条记录,占所有记录的7.82%,出现在1999001
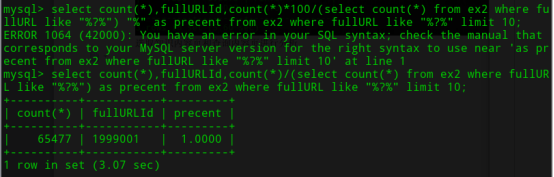
1999001中,快车律师助手标题比较多’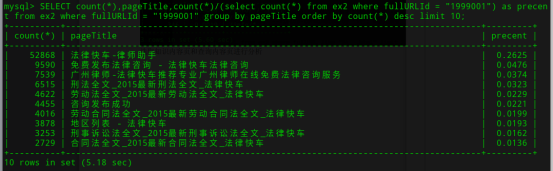
点击次数分析,浏览一次的用户占所有用户的65%左右,大部分用户浏览次数在1次,用户浏览的平均次数是2.3919次

针对点击一次的用户浏览的网页进行统计分析,排名靠前的都是知识内容页面和查询内容页面,可以猜测

从原始数据中统计html后缀的网页的点击率,点击次数排名前20的是法规专题、知识内容页

数据清洗
咨询发布成功页面
hive> insert overwrite table dblab.ex2 select * from ex2 where pageTitle != "咨询发布成功";
中间类型网页
hive> insert overwrite table dblab.ex2 select * from ex2 where fullURL not like "%midques\_%";
带有”?”其他页面
hive> insert overwrite table dblab.ex2 select * from ex2 where fullURL not like "%?%" or fullURLId != "1999001" ;
重复数据
hive> insert overwrite table ex2 select * from ex2 where Id in (select min(Id) from ex2 group by userId,time_stamp,fullURL);
无html行为的用户记录
hive> insert overwrite table ex2 select * from ex2 where userId in (select userId from ex2 t1 where fullURL like "%.html");
律师的行为记录
hive> insert overwrite table ex2 select * from ex2 where pageTitle not like "%快车-律师助手%";
目录网页
hive> insert overwrite table ex2 select * from ex2 where Id not in (select Id from ex2 where fullURL like "http://www.lawtime.cn/%/" and fullURL not like "%.html" and fullURL not like "%?%" union select Id from ex2 where fullURL Like "http://www.lawtime.cn/%" and fullURL not like "http://www.lawtime.cn/%/%");
翻页网页
Hive> insert overwrite table ex2 select * from ex2 where fullURL not like "%\__.html"
数据变换
模型构建
代码(未完):
import numpy as np
from sklearn.model_selection import train_test_split
import heapq
fileList = ['ask20', 'ask80', 'info20', 'info80']
def initlist(file, list1):
# file为文件名 set1为urlset set2为userset list为alllist
f = open("Data/bigdatacase/" + file)
try:
while True:
s = f.readline()
if s == '':
break
templist = []
s = s.split("\t")
user = s.pop(0)
url = s.pop(0)
templist.append(user)
templist.append(url)
list1.append(templist)
finally:
f.close()
def initset(set1, set2, list1):
for v in list1:
set1.add(v[0])
set2.add(v[1])
def getlist(list1, set1):
for i, v in enumerate(set1):
list1[i] = v
def getmatrix(list1, list2, list3, matrix):
# list1为userlist list2为urllist list3为alllist
all = len(list3)
for i, v in enumerate(list3):
percent = int(i/all*100)
print("\r生成用户-网页矩阵" + "." * percent + str(percent) + "%", end=' ')
matrix[list1.index(v[0])][list2.index(v[1])] = 1
print()
def jaccard(matrix1, matrix2):
# 杰卡得相似度J(A1,AM) = |A1∩AM|/|A1∪AM|
urls = len(matrix1[0, :])
users = len(matrix1[:, 0])
all = urls*urls
for i in range(urls):
for j in range(urls):
'''
likes1 = 0
likes2 = 0
for l in range(users):
if matrix1[l][i] == 1 or matrix1[l][j] == 1:
likes1 = likes1 + 1
if matrix1[l][i] == 1 and matrix1[l][j] == 1:
likes2 = likes2 + 1
if likes2 != 0:
matrix2[i][j] = likes2/likes1
'''
AandB = np.dot(matrix1[:, i], matrix1[:, j])
AorB = np.sum(matrix1[:, i]) + np.sum(matrix1[:, j]) - AandB
if AorB == 0:
matrix2[i][j] = 0
else:
matrix2[i][j] = AandB/AorB
percent = int((i * urls + j) / all * 100)
print("\r计算jaccard相似度" + "." * percent + str(percent) + "%", end=' ')
print()
return
def cos(matrix1, matrix2):
# 余弦相似度cosΘ = A1·AM/|A1|*|AM|
urls = len(matrix1[0, :])
for i in range(urls):
for j in range(urls):
dot = np.dot(matrix1[:, i], matrix1[:, j])
product = np.sum(matrix1[:, i]**2)**0.5 * np.sum(matrix1[:, j]**2)**0.5
matrix2[i][j] = abs(dot)/product
return
def pearson():
# 两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商
return
def getlikematrix(matrix1, matrix2, matrix3):
urls = len(matrix1[0, :])
users = len(matrix1[:, 0])
all = users*urls
for i in range(users):
for j in range(urls):
if matrix1[i][j] == 0:
matrix3[i][j] = np.dot(matrix1[i, :], matrix2[j, :])
elif matrix1[i][j] == 1:
matrix3[i][j] = -1
percent = int((i * urls + j) / all * 100)
print("\r计算相似度矩阵" + "." * percent + str(percent) + "%", end=' ')
print()
def getrank(likematrix, recommendmatrix):
# 找出最大值
for i1, v1 in enumerate(likematrix):
b = heapq.nlargest(5, range(len(v1)), v1.take)
for i2, v2 in enumerate(b):
recommendmatrix[i1][i2] = v2
def printrecommend(likematrix, recommendmatrix, urllist, userlist, userurl):
for i1, v1 in enumerate(recommendmatrix):
print("用户" + str(userlist[i1]) + "浏览的网页")
for i2, v2 in enumerate(userurl[i1]):
if v2 == 1:
print(urllist[i2])
print("推荐的网页")
for i3, v3 in enumerate(v1):
if likematrix[i1][v3] != 0:
print(urlList[v3])
def gettp(test, urlset, userset, urllist, userlist, recommendmatrix):
tp = 0
for i, v in test:
if v[0] in userset and v[1] in urlset:
if urllist.index(v[1]) in recommendmatrix[userlist.index(v[0])]:
tp = tp + 1
return tp
urlSet = set()
userSet = set()
allList = []
initlist("info80", allList)
testsize = 0.98
print("训练集:测试集 = " + str((1-testsize)/testsize))
# 训练集和测试集 70%作为训练集
x1, x2 = train_test_split(allList, test_size=testsize)
initset(userSet, urlSet, x1)
print("url总数:")
print(len(urlSet))
print("user总数:")
print(len(userSet))
urlList = [0]*len(urlSet)
userList = [0]*len(userSet)
user_url = np.zeros((len(userList), len(urlList)), dtype=int)
url_url = np.zeros((len(urlList), len(urlList)), dtype=float)
user_url_like = np.zeros((len(userList), len(urlList)), dtype=float)
getlist(urlList, urlSet)
getlist(userList, userSet)
getmatrix(userList, urlList, x1, user_url)
print("用户列表:")
print(userList[0:30])
print("网页列表:")
print(urlList[0:30])
print("训练集:")
print(x1[0:30])
jaccard(user_url, url_url)
# cos(user_url, url_url)
print("用户-网页:")
print(user_url)
print("相似度矩阵:")
print(url_url)
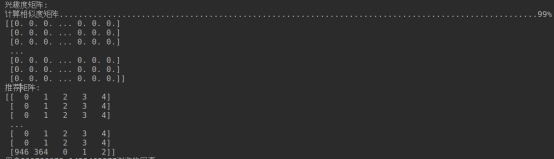
print("兴趣度矩阵:")
getlikematrix(user_url, url_url, user_url_like)
print(user_url_like)
recommend = np.zeros((len(userSet),5),dtype=int)
getrank(user_url_like, recommend)
print("推荐矩阵:")
print(recommend)
printrecommend(user_url_like,recommend,urlList,userList,user_url)
print("推荐正确数:")
print(gettp(x2,urlSet,urlList,urlList,userList,recommend))