原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
一、Background and Introduction

Zipf's law states that given some corpus (语料库)of natural language utterances(自然语言), the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, etc.
齐普夫定律是美国学者G.K.齐普夫于20世纪40年代提出的词频分布定律。它可以表述为:如果把一篇较长文章中每个词出现的频次统计起来,按照高频词在前、低频词在后的递减顺序排列,并用自然数给这些词编上等级序号,即频次最高的词等级为1,频次次之的等级为2,……,频次最小的词等级为D。若用f表示频次,r表示等级序号,则有fr=C(C为常数)。人们称该式为齐普夫定律。
Zipf’s law, an empirical law formulated using mathematical statistics, refers to the fact that many types of data studied in the physical and social sciences can be approximated with a Zipfian distribution, one of a family of related discrete power law probability distributions. The law is named after the American linguist George Kingsley Zipf (1902 1950), who first proposed it (Zipf 1935, 1949).
For example, in the Brown Corpus of American English text,the word “the” is the most frequently occurring word, and by itself accounts for nearly 7% of all word occurrences (69,971out of slightly over 1 million). True to Zipf’s Law, the second-place word “of” accounts for slightly over 3.5% of words (36,411 occurrences), followed by “and” (28, 852).Only 135 vocabulary items are needed to account for half theBrown Corpus.
The Brown University Standard Corpus of Present-Day American English (or just Brown Corpus) was compiled in the 1960s by Henry Kucera and w. Nelson Francis at Brown University as a general corpus (text collection) in the field of corpus linguistics. It contains 500 samples of English-language text, totaling roughly one million words, compiled from works published in the United States in 1961.
例如,在美国英语文本的布朗语料库中,单词“the”是最常出现的单词,并且其自身占所有单词出现的近7%(69,971输出略高于100万)。 按照Zipf定律,第二个单词“of”占据了超过3.5%的单词(36,411次出现),其次是“and”(28,852)。只需要135个词汇项来占据布朗语料库的一半。
布朗大学标准语料库的现代美国英语(或简称布朗语料库)是由亨利·库塞拉和世界于20世纪60年代编制的。 布朗大学的尼尔森弗朗西斯作为语料库语言学领域的一般语料库(文本集)。 它包含500个英文文本样本,总计约100万字,根据1961年在美国出版的作品编制而成。
二、verification
Zipf定律指出,在文本中,标识符出现的频率与其在排序列表中的排名或位置成反比。这个定律描述了标识符在文本中是如何分布的,即一些标志符出现的频次很大,另一些出现的频次较低,还有一些基本不出现。它是自然语言处理中,非常重要的一个定律,它的数学语言可以这样描述:在给定的语料库里,对于任意的一个term,它的频度f与这个频度在语料库中的排名r的乘积近似一个常数。即f正比于1/r。以英语语料库为例,其他语料库一样遵循zipf定律,表明在英语单词中,只有极少数的词被经常使用,而绝大多数词很少被使用。事实上,它是一个很普遍的规律,比如网站的访问者数量、每个国家公司的数量都近似服从zipf定律。下面用nltk来获取基于zipf定律的双对数图,代码如下:
#coding:UTF-8
# Python3
#nltk自然语言处理工具包,使用nltk获取基于zipf定律的双对数图
from nltk import FreqDist #用来记录语料库中词频的分布
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TkAgg')#防止matplotlib 命令行执行报错
f = open('C:/Users/Administrator/Desktop/novel.txt', 'r',encoding = 'utf-8') # 打开小说
string = f.read()
f.close()
words = []#定义一个列表存放汉字
for word in string:
if word >= u'\u4e00' and word <= u'\u9fff': # 判断是否为汉字
words.append(word)
print(len(words)) # 小说总字数
fdist = FreqDist(words) # FreqDist()获取语料库中的词的频率分布
ranks=[]#设置变量作为词频的排名
freqs=[]#设置变量统计词频
for sample in fdist:
freqs.append(fdist[sample])#获取频率值也就是词频
#print(sample,fdist[sample])
for rank in range(len(freqs)):#生成排名
rank += 1
ranks.append(rank)
freqsStatic = sorted(freqs,reverse=True)#当reverse = TRUE时是按照从大到小的顺序排列
plt.loglog(ranks, freqsStatic)#生成双log线,plt.loglog(x,y)
plt.xlabel('词语频数', fontsize=14, fontweight='bold', fontproperties='SimHei')
plt.ylabel('词语名次', fontsize=14, fontweight='bold', fontproperties='SimHei')
plt.grid(True)#显示网格线
plt.show()
结果如下图所示:

通过以上验证,基本符合Zipf’s Law。
Zipfs law is most easily observed by plotting the data on a log-log graph, with the axes being log (rank order) and log(frequency).
For example, the word “the” (as described above) would appear at x = log(1), y = log(69971). The data conform to Zipf’s law to the extent that the plot is linear.
三、类zipf’s Law
3.1 Introduction
用公式表达为:
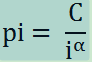
p 是可能性 i是排名,pi是排名第一的占比,C是一个常量,i属于正整数,当α 是一个趋近于1的数时。
当i = 1 p1 = c / 1 = c
当i = 2 p1 = c / 2
.
.
.
当i = i pi = c / i
由此可知排名第一的比第二的多一倍,一次类推。
3.2 The Difference between Zipf’s Law and Pareto Principle
简单的说:Pareto Principle也就是常说的20%-80%定律,粗略的说明了分布(粗线条)。而Zipf’s Law对分布的描述更加的精确
四、zipf’s Law应用
4.1 利用ZIPF定律建立有效的WEB对象缓存机制
这个是我们老师的一篇文章,文章内容可参考石磊老师的文章
摘要:
通过对Web通信量的分析,人们发现用户对Web对象的访问模式服从Zipf定律或类Zipf定律。在Web缓存的设计中,为得到所期望的Web对象命中率的要求,设计人员可以根据Zipf定律近似计算出相应的缓存大小。因此,Zipf定律为web缓存结构的设计提供了重要的依据。适当的缓存大小结合P-LFU替换策略可以得到很高的Web缓存命中率。
分析:
如上图所示,传统的Web缓存方法假设的前提是所处理的对象比较小,就象典型的HTML网页一样,一般都小于1K字节。例如,Harvest/Squid系统是一个著名的Web缓存系统,它采取一种代理缓存的层次结构,对于未被缓存的对象的请求可以传递到层次结构的任意位置直到获取所请求的对象为止。得到的请求对象被缓存在源和目标之间的每一个中间代理服务器缓存上。这种方法一般称作cache- everywhere策略。当所处理的Web对象比较小时,cache-everywhere会取得比较好的效果。
然而,对于网上的多媒体数据来说,对它们的处理比对简单的文本网页要困难得多。若也采用cache-everywhere策略,则会占用过多的网络资源:缓存磁盘空间和带宽。由于音视频对象一般占用的存储空间都比较大,即使数量不多也会占据大量的缓存空间;再者,传输大文件显然要占用较多的网络带宽。
通过对Web通信量的分析,人们发现用户访问模式服从Zipf或类Zipf分布定律,利用Zipf或类Zipf分布定律的固有属性,就可以建立有效的缓存机制。Zipf 定律可以帮助有效地选择哪些对象需要缓存,所以对于Web对象,尤其是对于多媒体信息,利用Zipf定律建立有效的Web对象缓存机制有重要的意义
结论:
Zipf定律为Web缓存结构的设计提供了重要的依据。在Web缓存的设计中,为得到所期望的Web对象命中率的要求,可以根据Zipf定律近似计算出相应的缓存大小。
有效的缓存机制对于提高网络性能是非常重要的。多媒体对象一般占用空间比较大,当缓存时若不加区分则要占用大量的缓存空间和带宽。所以,Zipf定律对Web对象的缓存特别是基于Web的多媒体应用开发很有帮助,其为有效利用网络缓存资源提供了一条新的思路。

4.2 Benford law
在自然形成的十进制数据中,任何一个数据的第一个数字d出现的概率大致log10(1+1/d)
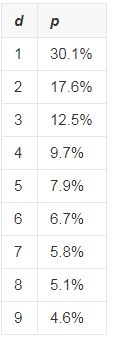
1938年,物理学家Frank Benford发现了一个有趣的数字规律(Benford Law) ——现实生活中数字的首字母是“1”的概率要远远大于“9”。仔细研究后发现,从1~9出现的概率符合对数分布,“1”出现的概率为30.1%,“2”出现的概率为17.6%,而“9”的概率只有4.6%,详细见下图,纵坐标是概率,横坐标是数字。
这是一个令人迷惑,违反直觉的发现,为什么数字的出现概率要这样分布呢? 一个可能的解释是符合这个规律的数据有尺度不变的性质,比如一组数据如果以英寸作为单位时符合Benford规律,那个把这组数据换成厘米为单位时仍然符合Benford规律。换个角度,如果把尺度不变作为基础,那么只有对数分布才能导致尺度不变。虽然这个理由看上去很合理,但只能说是自洽的,仍然没有直接回答“为什么要出现这种分布?”或者“为什么要求尺度不变?”
本福特定律说明一堆从实际生活得出的数据中,以1为首位数字的数的出现机率约为总数的三成,接近期望值1/9的3倍。推广来说,越大的数,以它为首几位的数出现的机率就越低。它可用于检查各种数据是否有造假。
-
1935年,美国的一位叫做本福特的物理学家在图书馆翻阅对数表时发现,对数表的头几页比后面的页更脏一些,这说明头几页在平时被更多的人翻阅。
-
本福特再进一步研究后发现,只要数据的样本足够多,数据中以1为开头的数字出现的频率并不是 1/9,而是30.1%。而以2为首的数字出现的频率是17.6%,往后出现频率依次减少,9的出现频率最低,只有4.6%。
-
本福特开始对其它数字进行调查,发现各种完全不相同的数据,比如人口、物理和化学常数、棒球统计表以及斐波纳契数列数字中,均有这个定律的身影。
-
1961年,一位美国科学家提出,本福特定律其实是数字累加造成的现象,即使没有单位的数字。比如,假设股票市场上的指数一开始是1000点,并以每年10%的程度上升,那么要用7年多时间,这个指数才能从1000点上升到2000点的水平;而由 2000点上升到3000点只需要4年多时间;但是,如果要让指数从10000点上升到20000点,还需要等7年多的时间。因此我们看到,以1为开头的指数数据比以其他数字打头的指数数据要高很多。
-
全世界200个左右国家地区,如果我们看面积的第一个数字出现的频率,1到9也遵守Benford定律,同样,这些国家地区的人口的第一个数字也遵守Benford定律,这是一件很奇妙的事情。
4.3 Matthew Effect
马太效应(Matthew Effect),是指好的愈好,坏的愈坏,多的愈多,少的愈少的一种现象。即两极分化现象。来自于圣经《新约•马太福音》中的一则寓言。
1968年,美国科学史研究者罗伯特·莫顿(Robert K. Merton)提出这个术语用以概括一种社会心理现象:“相对于那些不知名的研究者,声名显赫的科学家通常得到更多的声望即使他们的成就是相似的,同样地,在同一个项目上,声誉通常给予那些已经出名的研究者,例如,一个奖项几乎总是授予最资深的研究者,即使所有工作都是一个研究生完成的。”
此术语后为经济学界所借用,反映贫者愈贫,富者愈富,赢家通吃的经济学中收入分配不公的现象。
马太效应,名字来自圣经《新约·马太福音》一则寓言: “凡有的,还要加倍给他叫他多余;没有的,连他所有的也要夺过来”。表面看起来“马太效应”与“平衡之道”相悖,与“二八定则”类似,但是实则它只不过是“平衡之道”的一极。
4.4 scale - free network
传统的随机网络,尽管连接是随机设置的,但大部分节点的连接数目会大致相同,即节点的分布方式遵循钟形的泊松分布,有一个特征性的“平均数”。
无标度网络scale - free network,现实世界的网络大部分都不是随机网络,少数的节点往往拥有大量的连接,而大部分节点却很少,一般而 言他们符合zipf定律,(也就是80/20马太定律)。将度分布符合幂律分布的复杂网络称为无标度网络。无标度网络具有严重的异质性,其各节点之间的连接状况(度数)具有严重的不均匀分布性:网络中少数称之为Hub点的节点拥有极其多的连接,而大多数节点只有很少量的连接。少数Hub点对无标度网络的运行起着主导的作用。从广义上说,无标度网络的无标度性是描述大量复杂系统整体上严重不均匀分布的一种内在性质。
五、总结
这篇文章主要讲了Zipf’s Law、Zipf’s Law的验证,类Zipf’s Law,以及Zipf’s Law的应用。在Zipf’s Law应用中又介绍了一下四点内容:(1)利用ZIPF定律建立有效的WEB对象缓存机制,这个内容是我们老师发的一篇文章上的内容。(2)Benford law(3)Matthew Effect(4)scale - free network.以上内容参考教师课件。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
