Hadoop业务的整体开发流程:
Flume数据采集——MapReduce数据清洗——存入Hbase——Hive统计分析——存入Hive表——Sqoop导出数据——Mysql数据库——Web展示
总结来说分为以下几个步骤:数据采集,数据ETL,数据存储,数据计算/分析,数据展示。
数据来源大体包括:
- 业务数据
- 爬虫爬取的网络公开数据
- 购买数据
- 自行采集手机的日志数据
Flume
Flume是一个分布式,可靠,高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据,同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。
和Sqoop同属于数据采集系统组件,但是Sqoop用来采集关系型数据库数据,而Flume用来采集流动型数据。
Flume的优势:可横向扩展,延展性,可靠性。
1.x版本之后由Flume OG(最后的版本为0.94)改名为Flume NG(O和N是old和new的意思)
Flume的数据源可以是:console(控制台),RPC(Thrift-RPC),text(文件),tail(UNIX tail),syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等
Flume的数据接受方可以是:console(控制台),RPC(Thrift-RPC),text(文件),dfs(HDFS文件)和syslogTCP(TCP syslog日志系统)等。最常用的是Kafka
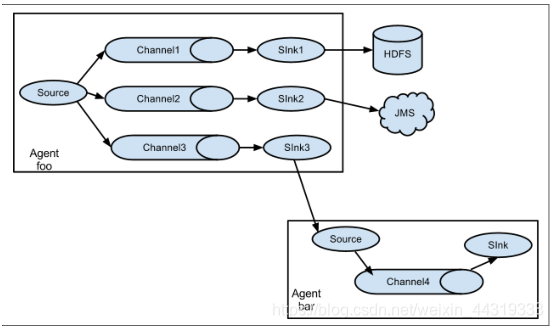
Flume体系结构/核心组件
Flume的数据流由事件(Event)贯穿始终,事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并携带有头信息,这些Event由Agent内部的Source接收或通过特殊机制生成,当Source捕获事件后回进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件知道Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
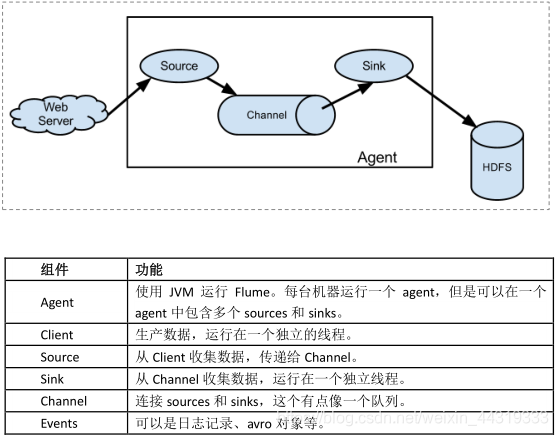
Flume以Agent为最小的独立运行单位。
一个Agent就是一个JVM。
单个Agent是由Source,Channel和Sink三大组件组成。
各个组件的介绍
Event:
- Event是Flume数据传输的基本单位。
- Flume以事件的形式将数据从源头传送到最终的目的地。
- Event由可选的Header和载有的一个Byte Array构成。
- 载有的数据的Flume是不透明的。
- Header是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
- Header可以在上下文路由中使用扩展。
Client:
- Client是一个将原始log包装成Events并且发送他们到一个或者多个Agent的实体中,目的是从数据源系统中解耦Flume。
- Client在Flume的拓扑结构中不是必须的。
Agent:
- 一个Agent包含Source,Channel和Sink和其他组件。
- 它使用这些组件经Events从一个节点传输到另一个节点或最终目的地。
- Agent是Flume流的基础部分。
- Flume为这些组件提供了配置,声明周期管理,监控支持。
Source:
- Source负责接收Event或通过特殊机制产生Event,并将Events批量的放到一个或多个。
Channel:
- 包含Event驱动和轮询两种类型。
- 不同类型的Source:
- 1. 与系统集成的Source:Syslog,Netcat,检测目录池
- 2. 自动生成事件的Source:Exec
- 3. 用于Agent和Agent之间的通讯的IPC source:avro,thrift
- Source必须至少和一个Channel关联。
Agent之Channel:
- Channel位于Source和Sink之间,用于缓存进来的Event。
- 当Sink成功的将Event发送到下一个的Channel或最终目的地,Event从Channel中删除。
- 不同的Channel提供的持久化水平也是不一样的:
- Channel支持事务,提供较弱的顺序保证。
- 可以和任何数量的Source和Sink工作
Agent之Sink:
- Sink负责将Event传输到下一个Agent或者最终目的地,成功后将Event从Channel移除。
- 不同类型的Sink:
- 1. 存储Event到最终目的地的终端Sink,比如HDFS,Hbase
- 2. 自动消耗的Sink,比如Null Sink
- 3. 用于Agent之间通信的IPC sink,比如:avro
- 4. 必须作用于一个确切的Channel
Iterator:
- 作用于Source,按照预设的顺序在必要的地方装饰和过滤Events。
Channel Selector:
- 允许Source基于预设的标准,从所有Channel中,选择一个或者多个Channel。
Sink Processor:
- 多个Sink可以构成一个Sink Group。
- Sink Processor可以通过组中所有的Sink实现负载均衡。
- 也可以在一个Sink失败是转移到另一个。
Agent核心组件的类型:

Flume经典部署方案
- 单Agent采集数据
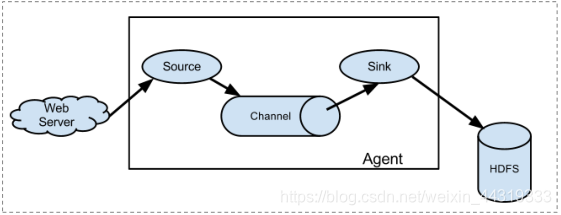
- 多Agent串联
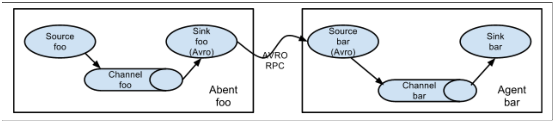
- 多Agent合并串联
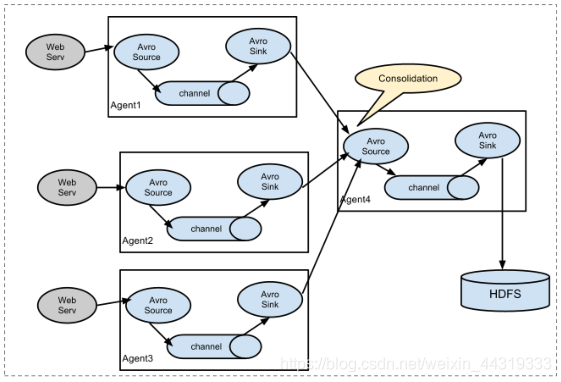
- 多路复用
Flume的使用
// 简单试用
-
在$FLUME_HOME/agentconf目录下创建一个根据数据采集的需求配置采集方案(文件名可以任意定义),即从一个网络端口收集数据。文件内容如下:

-
启动Agent去采集数据:
在$FLUME_HOME下执行如下命令:
bin/flume-ng agent -c conf -f agentconf/文件 -n a1 -Dflume.root.logger=INFO,console
-c conf 指定Flume自身的配置文件所在的目录
-f agentconf/… 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字 -
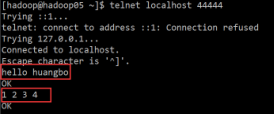
测试:
先往Agent的Source所监听的端口上发送数据,让agent有数据可采。
(打开这个端口的方式: telnet localhost 44444。如果这个命令的执行过程中发现抛出异常说:command not found,那么请使用:sudo yum -y install telnet 这个命令进行 telnet 的安装)
输入:
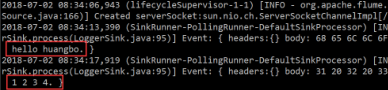
结果:
配置文件写法总结
//采集目录到HDFS
- 需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去。
- 根据需求,首先定义一下3大要素:
数据源组件,即Source——监控文件目录:spooldir
spooldir特性:
1 监视一个目录,只要目录中出现新文件,就会采集文件中的内容
2 采集完成的文件,会被Agent自动添加一个后缀:.COMPLETED
3 所监视的目录中不允许重复出现相同的文件名的文件
下沉组件,即Sink——HDFS文件系统:hdfs
通道组件,即Channel——可用file channel或者内存 channel
文件内容:


- 测试
启动:bin/flume-ng agent -c conf -f agentconf/… -n agent1
注意:
如果HDFS集群为HA集群,那么必须要放入core-site.xml 和 hdfs-site.xml 文件到$FLUME_HOME/conf目录中。
//采集文件到HDFS,比如业务系统使用log4j生成保存到磁盘的日志
//高可用部署采集
案例场景:
A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log
现在要求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上然后统一收集到 HDFS
中。
但是在 hdfs 中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**