什么是InputSplit
InputSplit是指逻辑切片,在MapReduce当中作业中,作为map task最小输入单位,默认是split的大小与block的大小相等,均为128MB。分片是基于文件基础上出来的而来的概念,通俗的理解一个文件可以切分为多少个片段,每个片段包括了<文件名,开始位置,长度,位于哪些主机>等信息。map task的数量由输入文件总大小和分片大小确定的;hadoop2.2版本hdfs的数据块默认是128M。若一个文件大于128M,通过将大文件分解得到若干个数据块;若一个文件小于128M,则按它的实际大小组块存储;
因此可以解释为什么hdfs喜欢海量的大文件,而不喜欢海量的小文件:
(1)海量的小文件需要namenode存储较多的元数据信息记录块的位置(假如一个64M的数据块(大文件分解的块)需要1k的元数据信息,那么1M的数据块(小文件的块)仍需要1k的元数据信息)
(2)HDFS就是为流式访问大文件而设计的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
hdfs的一个数据块一定属于一个文件;
为什么map task分片大小最好和hdfs设置的块大小一致呢?
我们综合考虑两点:
(1)map task的个数=输入文件总大小(totalSize)/分片尺寸(splitSize)。也就是说分片尺寸越大,map task的个数就越少=>系统执行的开销越小,系统管理分片的开销越小。
(2)网络传输开销,如果分片太大以至于一个分片要跨越多个HDFS块,则一个map任务必须要由多个块通过网络传输,所以分片大小的上限是HDFS块的大小。
所以,map任务时的分片大小设置为HDFS块的大小是最佳选择。
决定分片大小的三个参数:
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。
流程
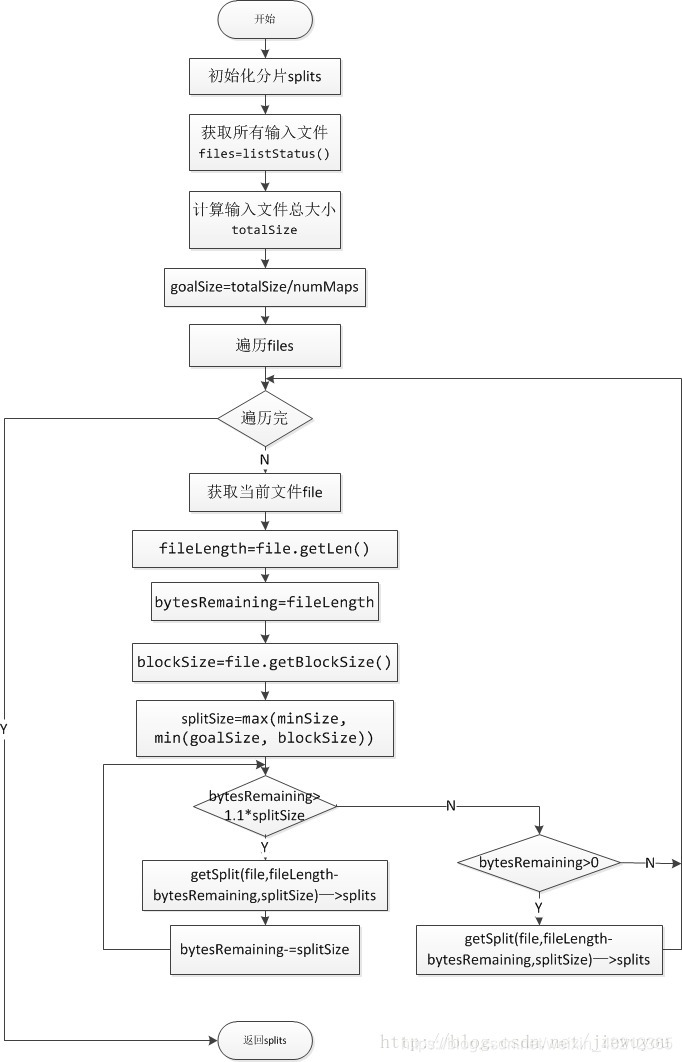
FileInputFormat.getSplits返回文件的分片数目
1)通过listStatus()获取输入文件列表files,其中会遍历输入目录的子目录,并过滤掉部分文件,如文件_SUCCESS
2)获取所有的文件大小totalSIze
3)goalSIze=totalSize/numMaps。numMaps是用户指定的map数目
4)files中取出一个文件file
5)计算splitSize。splitSize=max(minSplitSize,min(file.blockSize,goalSize)),其中minSplitSize是允许的最小分片大小,默认为1B
6)后面根据splitSize大小将file分片。在分片的时候,如果剩余的大小不大于splitSize*1.1,且大于0B的时候,会将该区域整个作为一个分片。这样做是为了防止一个7)mapper处理的数据太小
8)将file的分片加入到splits中
9)返回4,直到将files遍历完
10)结束,返回splits
PS:
如何在hadoop中控制map的个数:
http://blog.csdn.net/lylcore/article/details/9136555