首先看下图
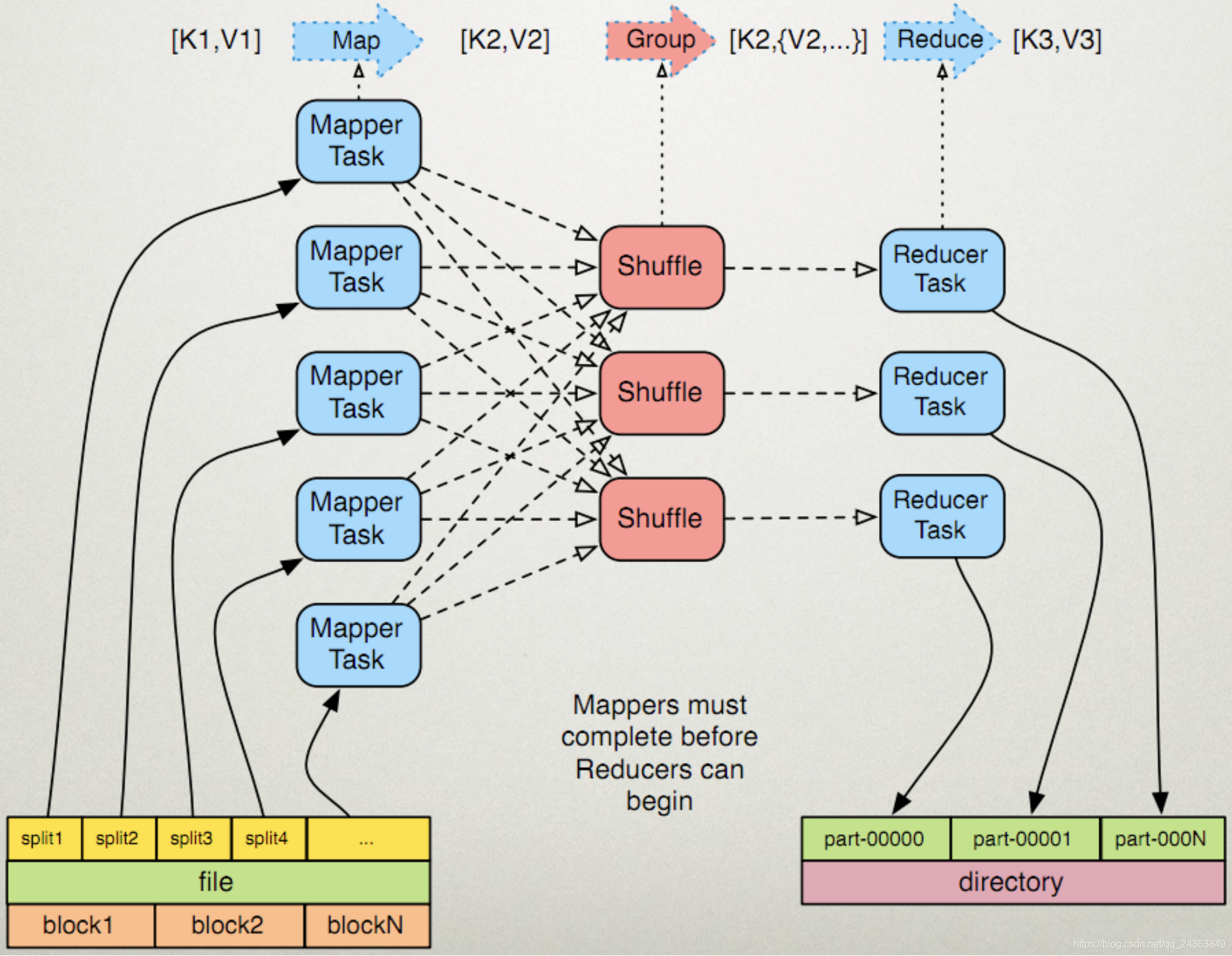
1.Split个数的确定
由图可知,一个split对应一个MapperTask,一个ReducerTask对应的输出为一个partition。是故,nums of splits,即可理解成为nums of map,即map的个数等于split的个数。
MapReduce在处理大文件的时候,会根据一定的规则把大文件切分成多个,这样能够提高map的并行度。
划分出来的就是InputSplit,每个map处理一个InputSplit.因此,有多少个InputSplit,就有多少个map数。
2.Split的划分规则
主要是InputFormat来划分,将输入的数据切分为多个逻辑上的InputSplit,每一个InputSplit对应一个map的输入。
2.1如何计算splitsize
划分split时会按照splitsize进行大文件的切分,划分的主要逻辑是FileInputFormat类中的getSplits(JobContext job),详见Hadoop源码(截取关键部分如下):
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
各个值的解释:
minSize:每个split的最小值,默认值为1,getFormatMinSplitSize()为代码中写死,固定返回1,可通过修改Hadoop源码进行修改,getMinSplitSize(job)则是返回mapreduce.input.fileinputformat.split.minsize,如果没有设置该参数,返回1,所以minSize默认为1(byte),可在mapred-site
.xml文件中设置该参数
maxSize:每个split的最大值,同样可以在mapred-site.xml文件中通过设置mapreduce.input.fileinputformat.split.maxsize来修改该值,默认情况下为Long的最大值,Long.MAX_VALUE=9223372036854775807
blockSize:默认为128M,可以通过修改hdfs-site.xml中的dfs.block.size参数来设置
splitSize:根据公式,可以通过minSize,maxSize,blockSize的大小来推导出splitSize,默认情况下是blockSize。
举几个例子来说明minSize,maxSize,blockSize取不同的值时,splitSize的变化:
由此可以看出两个可以自定义的值(minSize和maxSize)与blockSize之间的关系如下:
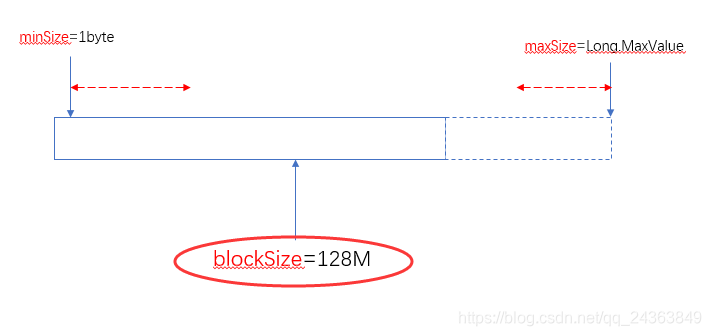
当blockSize位于minSize和maxSize 之间时,认blockSize:
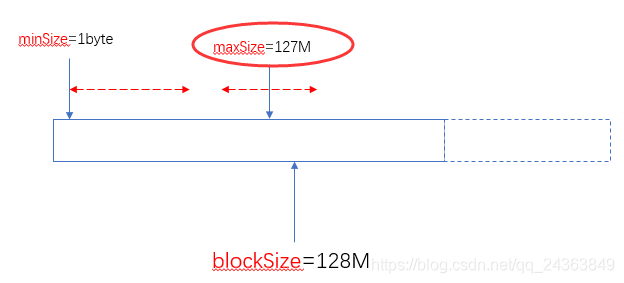
当maxSize小于blockSize时,认maxSize:
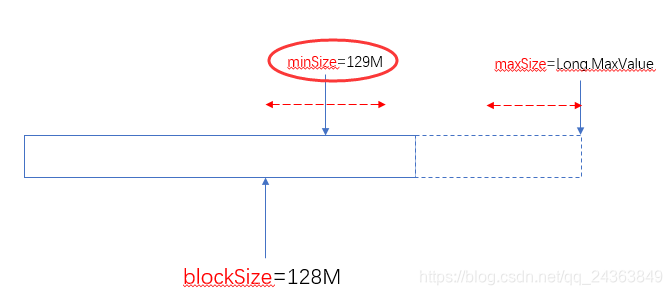
当minSize大于blockSize时,认minSize:
另外一个极端的情况,maxSize小于minSize时,认minsize,可以理解为minSize的优先级比maxSize大:
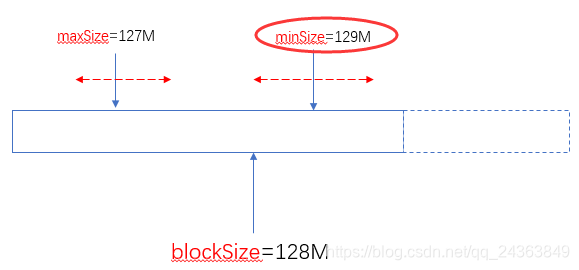
实际使用中,建议不要去修改maxSize,通过调整minSize(使他大于blockSize)就可以设定分片(Split)的大小了。
总之通过minSize和maxSize的来设置切片大小,使之在blockSize的上下自由调整。
2.2 split划分流程
1) 遍历输入目录中的每个文件,拿到该文件
2)计算文件长度,A:如果文件长度为0,如果mapred.split.zero.file.skip=true,则不划分split ; 如果mapred.split.zero.file.skip为false,生成一个length=0的split .B:如果长度不为0,跳到步骤3
3)判断该文件是否支持split :如果支持,跳到步骤4;如果不支持,该文件不切分,生成1个split,split的length等于文件长度。
4)根据当前文件,计算splitSize,本文中为100M
5 ) 判断剩余待切分文件大小/splitsize是否大于SPLIT_SLOP(该值为1.1,代码中写死了) 如果true,切分成一个split,待切分文件大小更新为当前值-splitsize ,再次切分。生成的split的length等于splitsize; 如果false 将剩余的切到一个split里,生成的split length等于剩余待切分的文件大小。之所以需要判断剩余待切分文件大小/splitsize,主要是为了避免过多的小的split。比如文件中有100个109M大小的文件,如果splitSize=100M,如果不判断剩余待切分文件大小/splitsize,将会生成200个split,其中100个split的size为100M,而其中100个只有9M,存在100个过小的split。MapReduce首选的是处理大文件,过多的小split会影响性能。
本文根据https://blog.csdn.net/wisgood/article/details/79178663
https://www.cnblogs.com/huqiaoblog/p/8064182.html
总结归纳而来。
(博客内容为笔者在学习过程中的总结与归纳,如有错误,恳请指正,万分感谢! )