一.超参数:
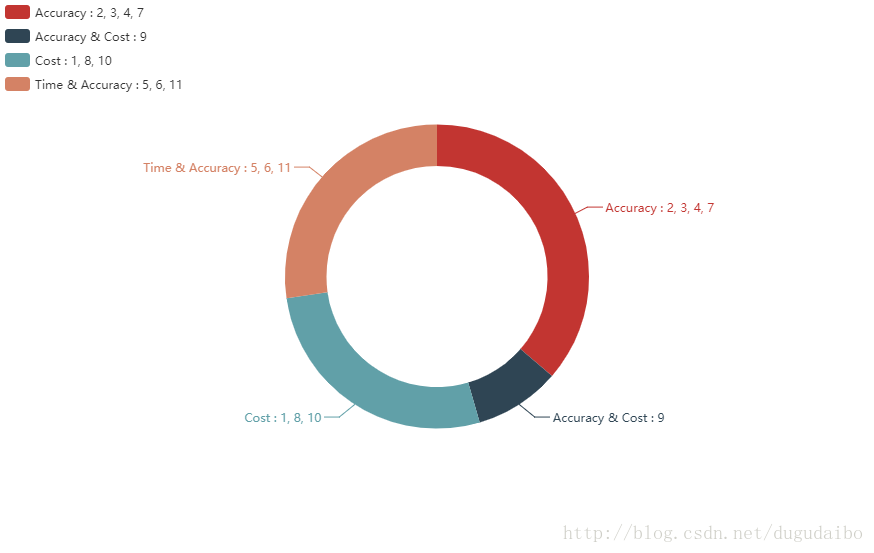
影响时间和准确率:5)学习迭代次数 epoch
6)miniBatch :批量数据大小
11)样本数量
影响学习速度: 1)学习率 η
8)代价函数选择
10)神经激活函数种类(隐含层sigmod ,输出层softmax)
准确率和学习速度:9)初始化权重
分类的正确率:2)正则化参数λ、
3)4)7)骨干网络选择
二.初次训练
精简:精简检验集中数据的数量,因为真正验证的是网络的性能,选择泛化网络
三.学习率选择(通常学习率倾向于更小而非更大)
1)选择 一个η阈值的估计,使得训练数据代价函数立刻下降(非增加,非震荡)(矫正量级即可)
1.若在多个回合才Cost才开始下降,则增大η
2.若一开始cost就震荡或增加,则减小η
四.迭代次数
每训练n次,进行一次验证,当acc多回合不在上升,则停止训练
方案:在初始阶段使用 10 回合不提升规则,然后逐步地选择更久的回合,比如 20 回合不提升就终止,30回合不提升就终止
五.正则化参数
1)开始时代价函数不包含正则项,先确定 η 的值
2)确定 η后,用验证数据来选择好的 λ(尝试λ=1开始,根据验证集上的性能,每次变化10)
六.miniBatch选取(幸运的是,小批量数据大小的选择其实是相对独立的一个超参数)
方法同学习率调整
七.大神从头调参
1)确定激活函数的种类,之后确定代价函数种类和权重初始化的方法,以及输出层的编码方式
2)自己构建网络(定神经网络中隐层的数目以及每一个隐层中神经元的个数),进行二步骤来验证
3)先不考虑正则项,得到一个η的阈值,取η/2 作为初始化参数
4)确定miniBatch
5)确定λλ
6)重新优化η
习惯:
1)画图:
一般是训练数据遍历一轮以后,就输出一下训练集和验证集准确率。同时画到一张图上。
2)经验参数
1.learning rate:0.1
2.每层结点数: 16 32 128
3.batch size: 128
4.dropout: 0.5
5.L2正则:1.0
6.clip c(梯度裁剪): 限制最大梯度:5,10,15
3)自动调参
Gird Search:每种参数确定好几个要尝试的值,然后组合遍历
Random Search:从候选参数中随机选择进行训练
Bayesian Optimization.(贝叶斯优化):推荐两个实现了贝叶斯调参的Python库
2.fmfn / BayesianOptimization, 比较复杂,支持并行调参
心得:
1)用normal初始化cnn的参数,最后acc只能到70%多,仅仅改成xavier,acc可以到98%
2)可视化取调参:
1.某个feature map的activation matrix可视化后跟原始输入长得一样,说明没有学到东西
2.可视化隐藏层的模型weight矩阵也能帮助我们获得一些insights
3..Embedding the Hidden Layer Neurons with t-SNE :通过t-SNE[10]对隐藏层进行降维,然后以降维之后的两维数据分别作为x、y坐标(也可以使用t-SNE将数据降维到三维,将这三维用作x、y、z坐标,进行3d clustering),对数据进行clustering,人工review同一类图片在降维之后的低维空间里是否处于相邻的区域。
技巧:
1)最初,先小数据集,大模型,能用256个filter你就别用128个,直接奔着过拟合去. 没错, 就是训练过拟合网络, 连测试集验证集这些都可以不用.就是为了看整体训练流程没有错误,假如loss不收敛就要好好反思了
2)观察loss胜于观察准确率
准确率虽然是评测指标,但会存在突变现象
3)心急的人, 总爱设个大点的LR, 初始情况下容易爆, 先上一个小LR保证不爆, 等loss降下来了, 再慢慢升LR
经验:
epoch:几十到几百
sgd,mini batch size:几十到几百
步长:0.1,可手动收缩
weight decay:0.005
momentum:0.9
dropout加relu
weight:高斯分布初始化
bias:始化为0
输入特征和预测目标:归一化
写两个脚本:1)给定参数的周期性评估结果 2)重新参数分配
自我总结:
准备:尽量选取大的网络(能用256个filter你就别用128个,直接奔着过拟合去)
1)参考论文,以论文给的参数作为初始化参数,若无,参数可使用均与分布初始化或高斯分布初始化)
2)判断这组初始化参数是否可行?
尝试训练法:用这组初始化参数,先减少训练集数目和训练类别数进行试探训练,观察结果(一般小数据集上合适参数,大数据集同样适用)
3)训练过程中,先使用较小的lr训练(但不能太小,容易达到局部最优),观察loss ,若果loss逐渐下降,说明学习的梯度方向正确,我们可以加大lr,增快训练速度 。 最后loss逐渐平稳的时候,再减小lr进行微调。
训练过程中,则先设置重要的参数(例如学习率等(0.001 0.01 0.1 1 10,一般从1开始,很少见大于10),学习率一般要随训练进行衰减,一般衰减系数为0.5(一般在验证机准确率不再上升时进行,或固定周期),不过一般adam,adadelta,rmsprop等,论文中都有默认值可直接使用),在设置次要参数(例如,dropout(0.3 0.5 0.7),正则化值(0.001 0.01 0.1 1 10)等
3-1)训练时,batch size尽可能大,最好在128以上(因为batch size太大,一般不会对结果有太大的影响,而batch size太小的话,结果有可能很差)
3-2)使用 梯度剪裁(clip c),限制最大梯度。(如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15)
3-3)初始化的dropout: 0.5,L2正则:1.0(很少超过10)
4)训练 过程中,周期进行验证,若COST没有下降,则学习率减半(可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好)
5)训练集loss不下降 (代码问题,数据问题,超参数有问题)。【正常情况应该是训练集的cost值不断下降,最后趋于平缓,或者小范围震荡,测试集的cost值先下降,然后开始震荡或者慢慢上升。】
6)最后,尝试用Highway Network 替代全连接层,尝试加入BN层
遇到Nan:
1)除0的可能。 查看代码,看看有除法的地方(例如softmax层)
2)梯度过大 。 1.减少学习率 2.用梯度剪裁
3)初始化参数过大 --考虑加入BN层