层次数据模型
定义:层次数据模型是用树状<层次>结构来组织数据的数据模型。
满足下面两个条件的基本层次联系的集合为层次模型
1. 有且只有一个结点没有双亲结点,这个结点称为根结点
2. 根以外的其它结点有且只有一个双亲结点
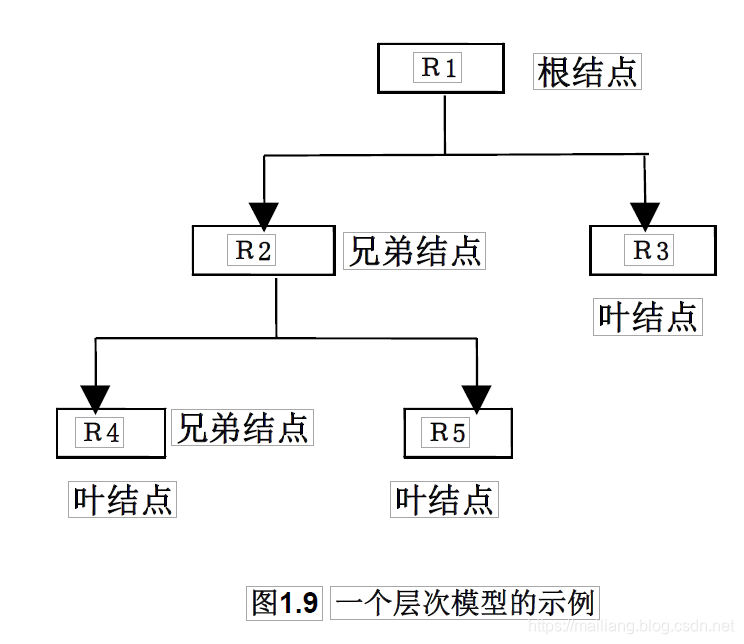
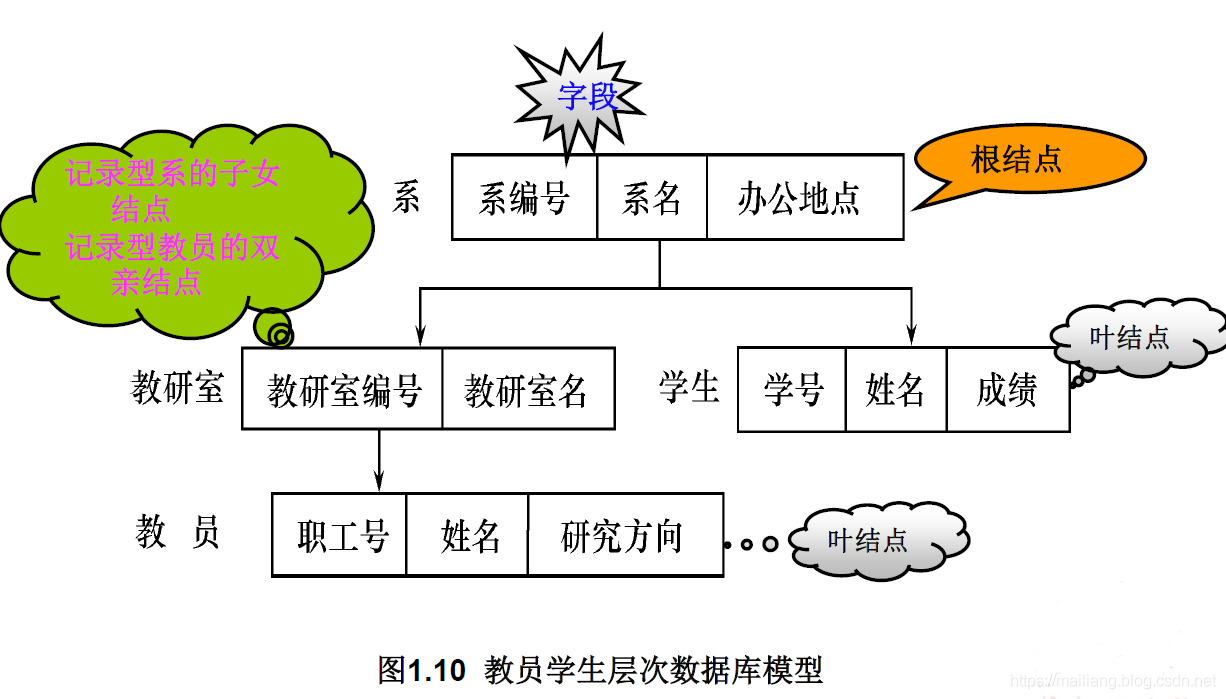
其实层次数据模型就是的图形表示就是一个倒立生长的树,由基本数据结构中的树(或者二叉树)的定义可知,每棵树都有且仅有一个根节点,其余的节点都是非根节点。每个节点表示一个记录类型对应与实体的概念,记录类型的各个字段对应实体的各个属性。各个记录类型及其字段都必须记录。
层次模型的特点:
结点的双亲是唯一的
只能直接处理一对多的实体联系
每个记录类型可以定义一个排序字段,也称为码字段
任何记录值只有按其路径查看时,才能显出它的全部意义
没有一个子女记录值能够脱离双亲记录值而独立存在
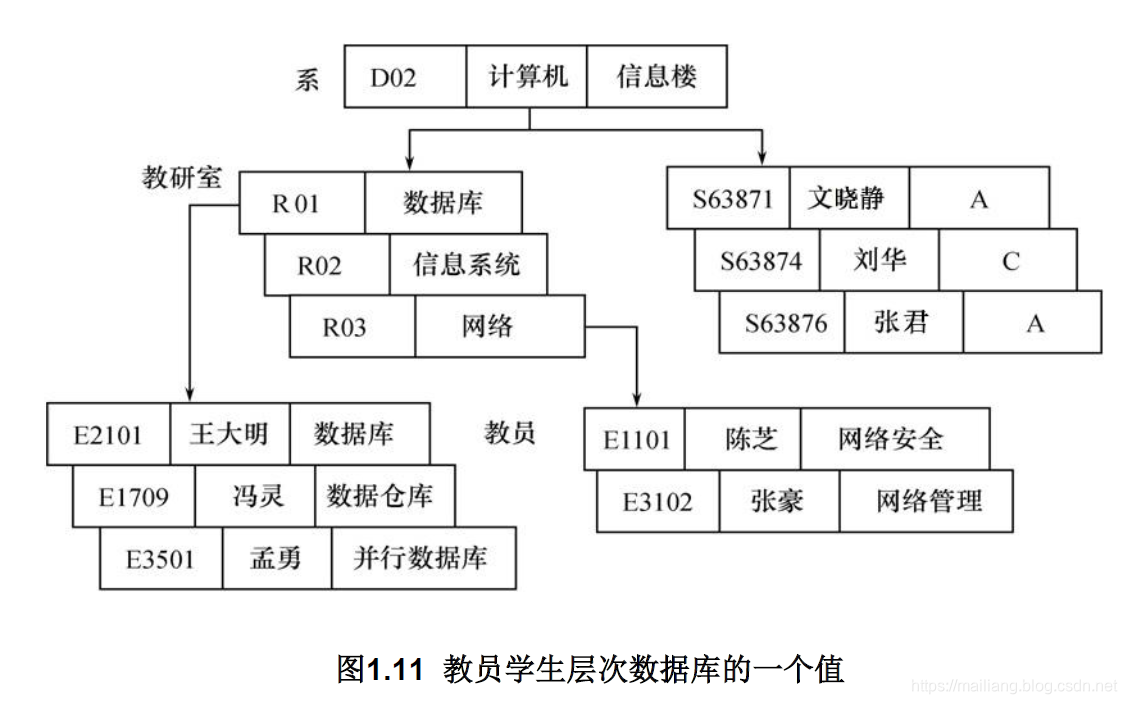
实例:
层次模型的完整性约束条件
无相应的双亲结点值就不能插入子女结点值
如果删除双亲结点值,则相应的子女结点值也被同时删除
更新操作时,应更新所有相应记录,以保证数据的一致性
优点
层次模型的数据结构比较简单清晰
查询效率高,性能优于关系模型,不低于网状模型
层次数据模型提供了良好的完整性支持
缺点
结点之间的多对多联系表示不自然
对插入和删除操作的限制多,应用程序的编写比较复杂
查询子女结点必须通过双亲结点
层次命令趋于程序化
层次数据库系统的典型代表是IBM公司的IMS(Information Management System)数据库管理系统
网状数据模型
定义:用有向图表示实体和实体之间的联系的数据结构模型称为网状数据模型。
满足下面两个条件的基本层次联系的集合称为网状数据模型:
1. 允许一个以上的结点无双亲;
2. 一个结点可以有多于一个的双亲。
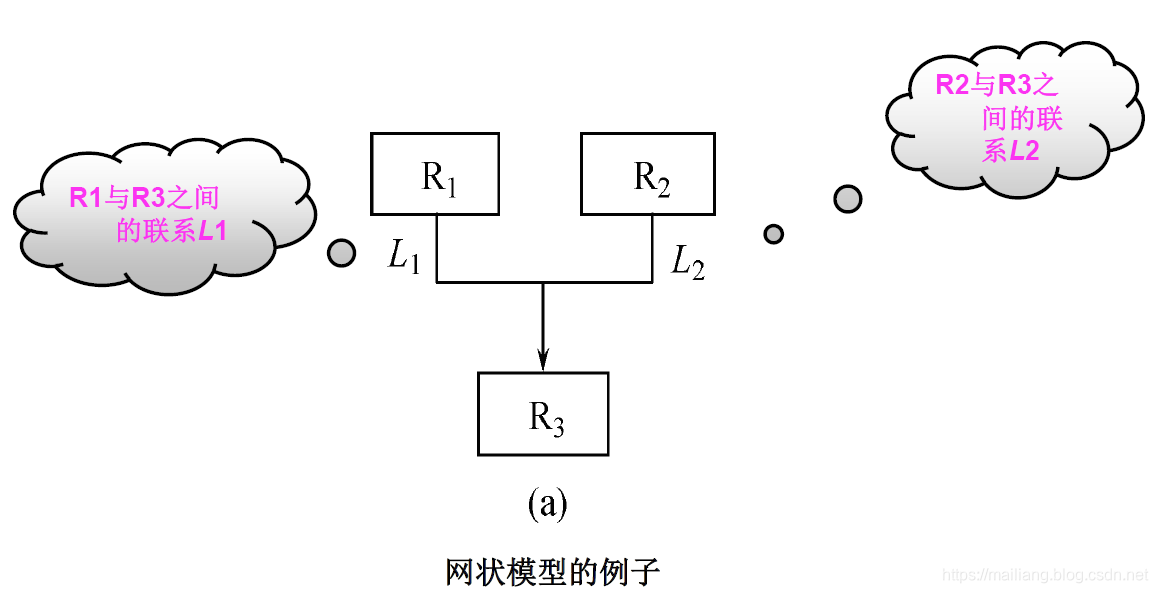
其实,网状数据模型可以看做是放松层次数据模型的约束性的一种扩展。网状数据模型中所有的节点允许脱离父节点而存在,也就是说说在整个模型中允许存在两个或多个没有根节点的节点,同时也允许一个节点存在一个或者多个的父节点,成为一种网状的有向图。因此节点之间的对应关系不再是1:n,而是一种m:n的关系,从而克服了层次状数据模型的缺点。
特征:
1. 可以存在两个或者多个节点没有父节点;
2. 允许单个节点存在多于一个父节点;
网状数据模型中的,每个节点表示一个实体,节点之间的有向线段表示实体之间的联系。网状数据模型中需要为每个联系指定对应的名称。
实例:
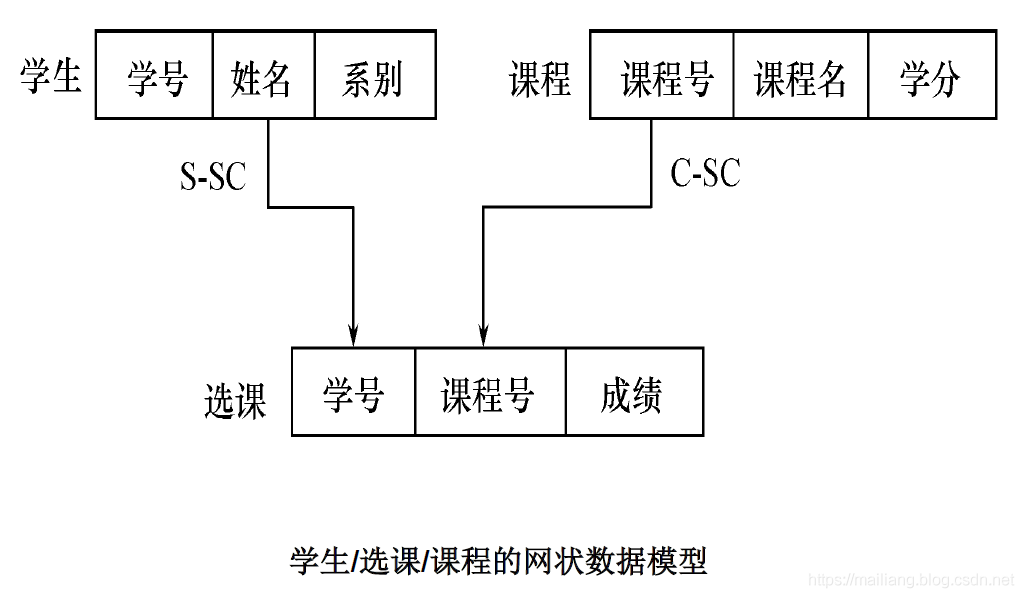
优点:
网状数据模型可以很方便的表示现实世界中的很多复杂的关系;
修改网状数据模型时,没有层次状数据模型的那么多的严格限制,可以删除一个节点的父节点而依旧保留该节点;也允许插入一个没有任何父节点的节点,这样的插入在层次状数据模型中是不被允许的,除非是首先插入的是根节点;
实体之间的关系在底层中可以借由指针指针实现,因此在这种数据库中的执行操作的效率较高;
缺点:
网状数据模型的结构复杂,使用不易,随着应用环境的扩大,数据结构越来越复杂,数据的插入、删除牵动的相关数据太多,不利于数据库的维护和重建。
网状数据模型数据之间的彼此关联比较大,该模型其实一种导航式的数据模型结构,不仅要说明要对数据做些什么,还说明操作的记录的路径;
DDL、DML语言复杂,用户不容易使用
记录之间联系是通过存取路径实现的,用户必须了解系统结构的细节
网状模型与层次模型的区别
网状模型允许多个结点没有双亲结点
网状模型允许结点有多个双亲结点
网状模型允许两个结点之间有多种联系(复合联系)
网状模型可以更直接地描述现实世界
层次模型实际上是网状模型的一个特例
典型代表是DBTG系统,亦称CODASYL系统,是20世纪70年代由DBTG提出的一个系统方案。实际系统:Cullinet Software公司的 IDMS、Univac公司的 DMS1100、Honeywell公司的IDS/2、HP公司的IMAGE。
三、关系型数据模型
关系型数据模型对应的数据库自然就是关系型数据库了,这是目前应用最多的数据库。
定义:使用表格表示实体和实体之间关系的数据模型称之为关系数据模型。
关系型数据库是目前最流行的数据库,同时也是被普遍使用的数据库,如MySQL就是一种流行的数据库。支持关系数据模型的数据库管理系统称为关系型数据库管理系统。
特征:
1. 关系数据模型中,无论是是实体、还是实体之间的联系都是被映射成统一的关系—一张二维表,在关系模型中,操作的对象和结果都是一张二维表,它由行和列组成;
2. 关系型数据库可用于表示实体之间的多对多的关系,只是此时要借助第三个关系—表,来实现多对多的关系;
3. 关系必须是规范化的关系,即每个属性是不可分割的实体,不允许表中表的存在;
实例:
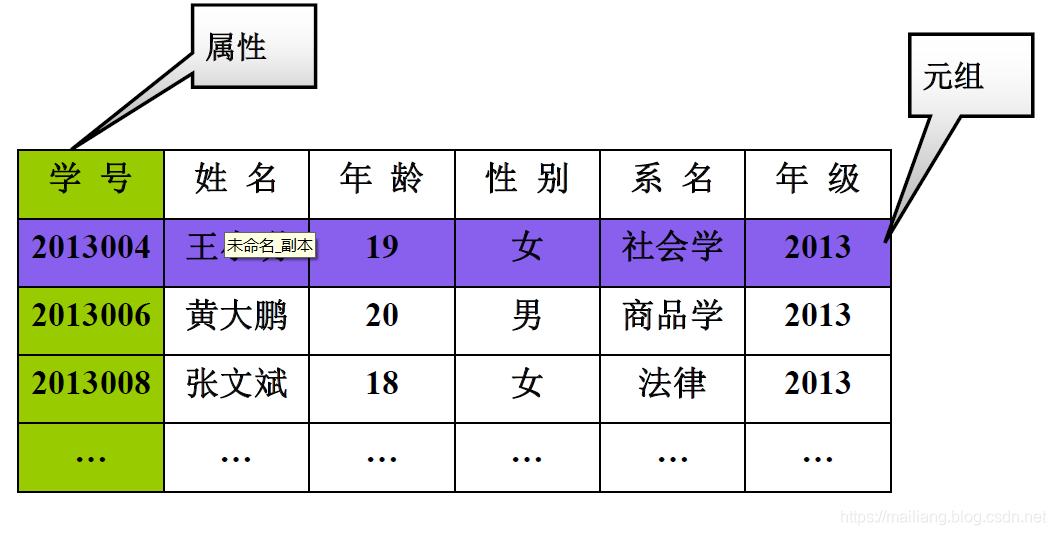
优点:
结构简单,关系数据模型是一些表格的框架,实体的属性是表格中列的条目,实体之间的关系也是通过表格的公共属性表示,结构简单明了;
关系数据模型中的存取路径对用户而言是完全隐蔽的,是程序和数据具有高度的独立性,其数据语言的非过程化程度较高;
操作方便,在关系数据模型中操作的基本对象是集合而不是某一个元祖;
有坚实的数学理论做基础,包括逻辑计算、数学计算等;
缺点:
查询效率低,关系数据模型提供了较高的数据独立性和非过程化的查询功能(查询的时候只需指明数据存在的表和需要的数据所在的列,不用指明具体的查找路径),因此加大了系统的负担;
由于查询效率较低,因此需要数据库管理系统对查询进行优化,加大了DBMS的负担;
相关概念:
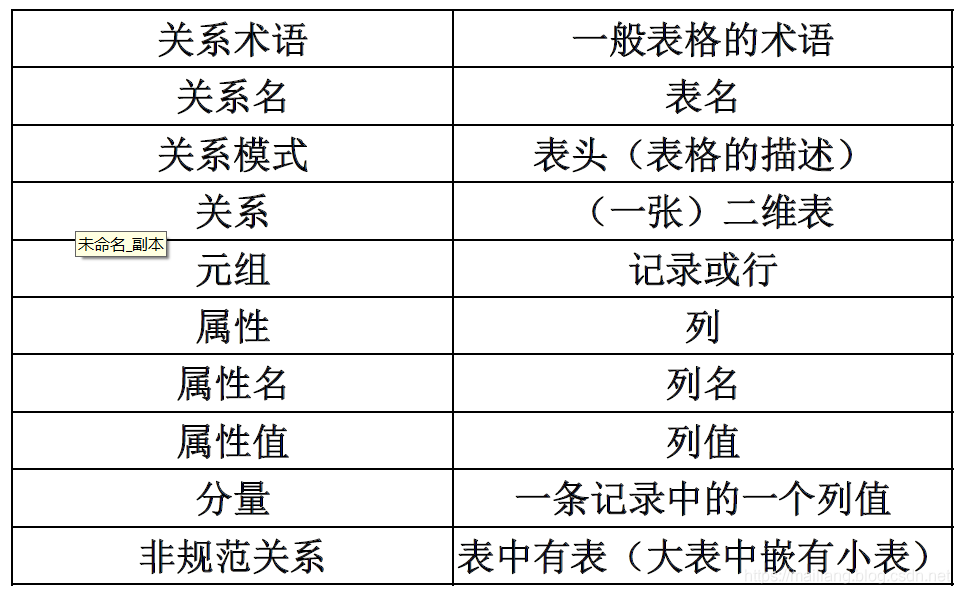
关系(Relation):一个关系对应通常说的一张表
元组(Tuple):表中的一行即为一个元组
属性(Attribute):表中的一列即为一个属性,给每一个属性起一个名称即属性名
主码(Key):也称码键。表中的某个属性组,它可以唯一确定一个元组
域(Domain):是一组具有相同数据类型的值的集合。属性的取值范围来自某个域。
分量:元组中的一个属性值。
关系模式:对关系的描述,关系名(属性1,属性2,…,属性n),如:学生(学号,姓名,年龄,性别,系名,年级)
关系必须是规范化的,满足一定的规范条件
最基本的规范条件:关系的每一个分量必须是一个不可分的数据项, 不允许表中还有表
术语对比
关系的完整性约束条件
实体完整性
实体完整性是指实体的主属性不能取空值。实体完整性规则规定实体的所有主属性都不能为空。实体完整性针对基本关系而言的,一个基本关系对应着现实世界中的一个主题,例如上例中的学生表对应着学生这个实体。现实世界中的实体是可以区分的,他们具有某种唯一性标志,这种标志在关系模型中称之为主码,主码的属性也就是主属性不能为空。
参照完整性
在关系数据库中主要是值得外键参照的完整性。若A关系中的某个或者某些属性参照B或其他几个关系中的属性,那么在关系A中该属性要么为空,要么必须出现B或者其他的关系的对应属性中。
用户定义的完整性
用户定义完整性是针对某一个具体关系的约束条件。它反映的某一个具体应用所对应的数据必须满足一定的约束条件。例如,某些属性必须取唯一值,某些值的范围为0-100等。
计算机厂商新推出的数据库管理系统几乎都支持关系模型