Introduction
你花了多少时间在凌乱凌乱的房子里寻找丢失的房间钥匙?它发生在我们最好的人身上,直到约会仍然是令人难以置信的令人沮丧的经历。但是,如果一个简单的计算机算法可以在几毫秒内找到您的密钥怎么办?
这就是物体检测算法的力量。虽然这只是一个简单的例子,但物体检测的应用跨越多个不同的行业,从全天候监控到智能城市的实时车辆检测。简而言之,这些是强大的深度学习算法。
在本文中,我们将深入探讨可以用于对象检测的各种算法。我们将从属于RCNN系列的算法开始,即RCNN,快速RCNN和更快的RCNN。在本系列的即将发表的文章中,我们将介绍更多高级算法,如YOLO,SSD等。
我鼓励您阅读上一篇关于对象检测的文章,其中我们将介绍这种精彩技术的基础知识,并使用ImageAI库向您展示Python的实现。
Let’s get started!
Table of Contents
- A Simple Way of Solving an Object Detection Task (using Deep Learning)
- Understanding Region-Based Convolutional Neural Networks
- Intuition of RCNN
- Problems with RCNN
- Understanding Fast RCNN
- Intuition of Fast RCNN
- Problems with Fast RCNN
- Understanding Faster RCNN
- Intuition of Faster RCNN
- Problems with Faster RCNN
- Summary of the Algorithms covered
1. A Simple Way of Solving an Object Detection Task (using Deep Learning)
下图是说明对象检测算法如何工作的流行示例。 图像中的每个对象,从人到风筝,都以一定的精度定位和识别。
让我们从最简单的深度学习方法开始,用于检测图像中的对象 - 卷积神经网络或CNN。 如果您对CNN的理解有点生疏,我建议您阅读本文 第一。
但我将简要总结一下CNN的内部运作方式。 看看下面的图片: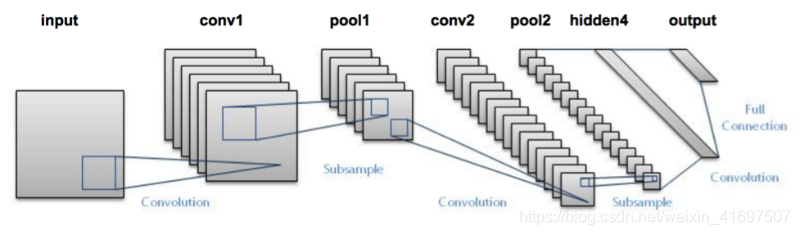
我们将图像传递到网络,然后通过各种卷积和池化层发送。 最后,我们以对象类的形式获得输出。 相当直白,不是吗?
对于每个输入图像,我们得到一个相应的类作为输出。 我们可以使用这种技术来检测图像中的各种对象吗? 我们可以! 让我们看看如何使用CNN解决一般对象检测问题。
- 首先,我们将图像作为输入:

2. 然后我们将图像划分为不同的区域:
3.然后,我们将每个区域视为单独的图像。
4.将所有这些区域(图像)传递给CNN,并将它们分类为各种类别。
5.一旦我们将每个区域划分为相应的类,我们就可以组合所有这些区域来获取具有检测到的对象的原始图像:

使用这种方法的问题是图像中的对象可以具有不同的宽高比和空间位置。 例如,在某些情况下,对象可能覆盖了大部分图像,而在其他情况下,对象可能只覆盖图像的一小部分。 对象的形状也可能不同(在现实生活中的用例中会发生很多)。
由于这些因素,我们需要大量的区域,导致大量的计算时间。 因此,为了解决这个问题并减少区域数量,我们可以使用基于区域的CNN,它使用提议方法选择区域。 让我们了解这个基于地区的CNN可以为我们做些什么。
2 理解基于区域的卷积神经网络
2.1 Intuition of RCNN
RCNN算法不是在大量区域上工作,而是在图像中提出了一堆框,并检查这些框中是否包含任何对象。 RCNN使用选择性搜索从图像中提取这些框(这些框称为区域)。
让我们首先了解选择性搜索是什么以及它如何识别不同的区域。 基本上有四个区域形成一个对象:不同的比例,颜色,纹理和外壳。 选择性搜索在图像中识别这些模式,并基于此,提出各种区域。 以下是选择性搜索如何工作的简要概述:
它首先将图像作为输入:

然后,它生成初始子分段,以便我们从此图像中有多个区域:
该技术然后组合相似区域以形成更大的区域(基于颜色相似性,纹理相似性,尺寸相似性和形状兼容性):

最后,这些区域然后产生最终的对象位置(感兴趣的区域)。
下面是RCNN检测对象的步骤的简要总结:
- 我们首先采用预先训练的卷积神经网络。
- 然后,这个模型被重新训练。我们根据需要检测的类的数量来训练网络的最后一层。
- 第三步是获取每个图像的感兴趣区域。然后我们重塑所有这些区域,以便它们可以匹配CNN输入大小。
- 获取区域后,我们训练SVM对对象和背景进行分类。对于每个类,我们训练一个二进制SVM。
- 最后,我们训练线性回归模型,为图像中每个识别出的对象生成更严格的边界框。
您可以通过可视化示例更好地了解上述步骤 下面显示的示例的图像来自[本文](http://www.robots.ox.ac.uk/~tvg/publications/talks/ fast-rcnn-slides.pdf)。所以我们拿一个吧!
- 首先,将图像作为输入:

- 然后,我们使用一些提议方法获得感兴趣区域(ROI)(例如,如上所示的选择性搜索):

- 然后根据CNN的输入对所有这些区域进行重新整形,并将每个区域传递给ConvNet:
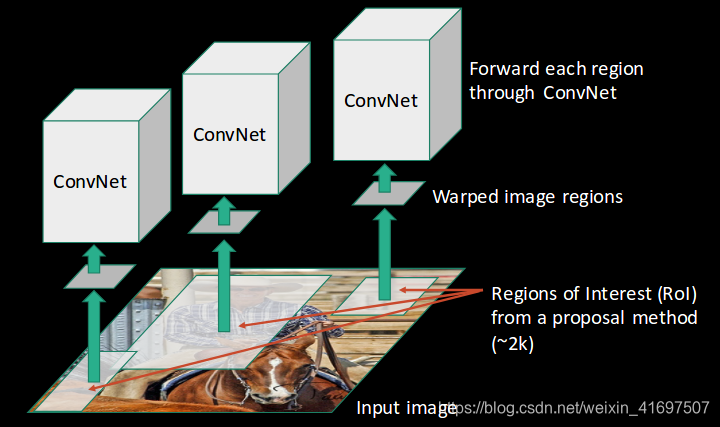
CNN然后提取每个区域的特征,SVM用于将这些区域划分为不同的类别:

最后,边界框回归(Bbox reg)用于预测每个已识别区域的边界框:
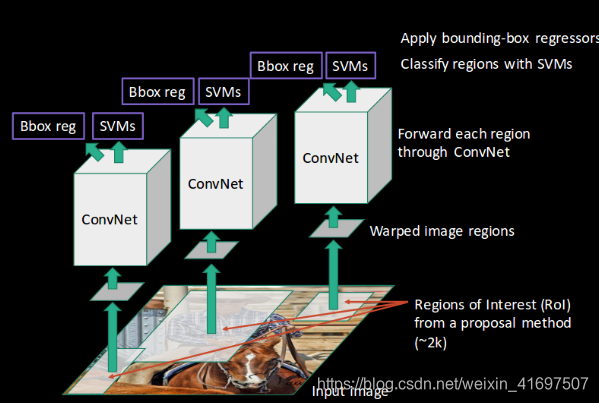
简而言之,这就是RCNN如何帮助我们检测物体。
2.2 Problems with RCNN
到目前为止,我们已经看到RCNN如何有助于对象检测。 但这种技术有其自身的局限性。 由于以下步骤,训练RCNN模型既昂贵又缓慢:
- 基于选择性搜索为每个图像提取2,000个区域
- 使用CNN为每个图像区域提取特征。 假设我们有N个图像,那么CNN特征的数量将是N * 2,000
- 使用RCNN进行物体检测的整个过程有三种模型:
- 用于特征提取的CNN
- 用于识别对象的线性SVM分类器
- 用于收紧边界框的回归模型。
所有这些过程结合起来使RCNN非常慢。 对每个新图像进行预测需要大约40-50秒,这实际上使得模型在面对巨大的数据集时变得麻烦且几乎不可能构建。
这是好消息 - 我们有另一种物体检测技术,它解决了我们在RCNN中看到的大部分限制。
3. Understanding Fast RCNN
3.1 Intuition of Fast RCNN
我们还能做些什么来减少RCNN算法通常需要的计算时间?我们可以每张图像运行一次,而不是每张图像运行2,000次CNN,并获得所有感兴趣的区域(包含某些对象的区域)。
RCNN的作者罗斯·吉尔希克(Ross Girshick)提出了这样的想法,即每张图像只运行一次CNN,然后找到一种方法在2,000个区域内共享该计算。在快速RCNN中,我们将输入图像馈送到CNN,CNN又生成卷积特征映射。使用这些地图,提取提案区域。然后,我们使用RoI池层将所有建议的区域重新整形为固定大小,以便将其馈送到完全连接的网络中。
让我们将其分解为简化概念的步骤:
- 与前两种技术一样,我们将图像作为输入。
- 此图像传递给ConvNet,后者又生成感兴趣的区域。
- 在所有这些区域上应用RoI池层,以根据ConvNet的输入对其进行重新整形。然后,每个区域被传递到完全连接的网络。
- 在完全连接的网络顶部使用softmax层来输出类。与softmax层一起,线性回归层也平行使用,以输出预测类的边界框坐标。
因此,快速RCNN不是使用三个不同的模型(如在RCNN中),而是使用单个模型从区域中提取特征,将它们分成不同的类,并同时返回所识别类的边界框。
为了进一步细分,我将可视化每个步骤,为解释添加实用角度。
- 我们遵循现在众所周知的将图像作为输入的步骤:

- 此图像传递给ConvNet,后者相应地返回感兴趣的区域:

- 然后我们在提取的感兴趣区域上应用RoI池层,以确保所有区域具有相同的大小:

- 最后,这些区域被传递到一个完全连接的网络,对它们进行分类,并同时使用softmax和线性回归层返回边界框:
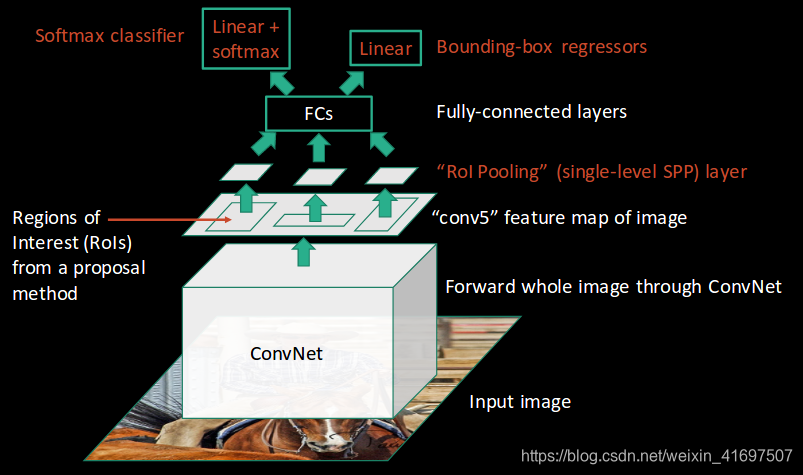
这就是快速RCNN如何解决RCNN的两个主要问题,即将每个图像的一个而不是2,000个区域传递给ConvNet,并使用一个而不是三个不同的模型来提取特征,分类和生成边界框。
3.2 Problems with Fast RCNN
但即使是快速RCNN也存在一定的问题。 它还使用选择性搜索作为查找感兴趣区域的提议方法,这是一个缓慢且耗时的过程。 每个图像检测对象大约需要2秒钟,与RCNN相比要好得多。 但是当我们考虑大型真实数据集时,即使是快速RCNN也不再那么快了。
但还有另一种物体检测算法胜过Fast RCNN。 有些东西告诉我你不会对它的名字感到惊讶。
4. Understanding Faster RCNN
4.1. Intuition of Faster RCNN
更快的RCNN是Fast RCNN的修改版本。 它们之间的主要区别在于,快速RCNN使用选择性搜索来生成感兴趣的区域,而更快的RCNN使用“区域提议网络”,即RPN。 RPN将图像特征映射作为输入,并生成一组对象提议,每个对象提议都以对象分数作为输出。
以下步骤通常采用更快的RCNN方法:
- 我们将图像作为输入并将其传递给ConvNet,后者返回该图像的特征图。
- 区域提议网络应用于这些要素图。 这将返回对象提议及其对象分数。
- 对这些提案应用RoI池层,以将所有提案降低到相同的大小。
- 最后,将提议传递到完全连接的层,该层在其顶部具有softmax层和线性回归层,以对对象的边界框进行分类和输出。
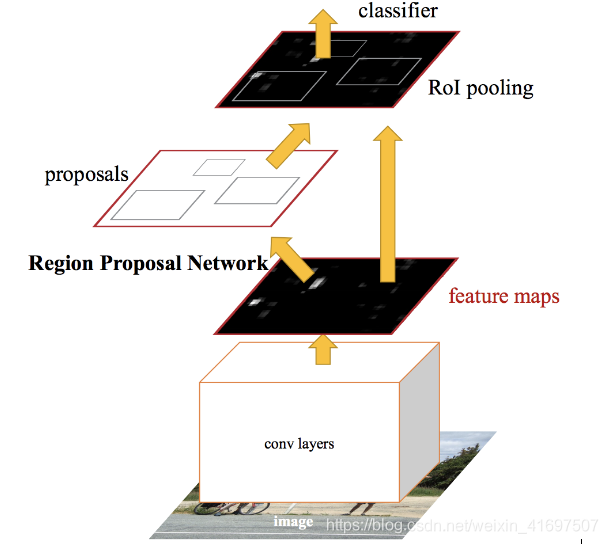
让我简要解释一下这个区域提案网络(RPN)实际上是如何运作的。
首先,更快的RCNN从CNN获取特征图并将它们传递到区域提议网络。 RPN在这些特征图上使用滑动窗口,并在每个窗口生成不同形状和大小的k个锚框:

锚箱是固定尺寸的边界箱,其放置在整个图像中并具有不同的形状和尺寸。 对于每个锚,RPN预测两件事:
- 第一个是锚是一个对象的概率(它不考虑对象属于哪个类)
- 第二个是用于调整锚点以更好地适合物体的边界框回归器
我们现在有不同形状和大小的边界框,它们被传递到RoI池层。 现在有可能在RPN步骤之后,有没有分配给它们的类的提议。 我们可以采用每个提案并对其进行裁剪,以便每个提案都包含一个对象。 这就是RoI池层所做的事情。 它为每个锚提取固定大小的要素图:
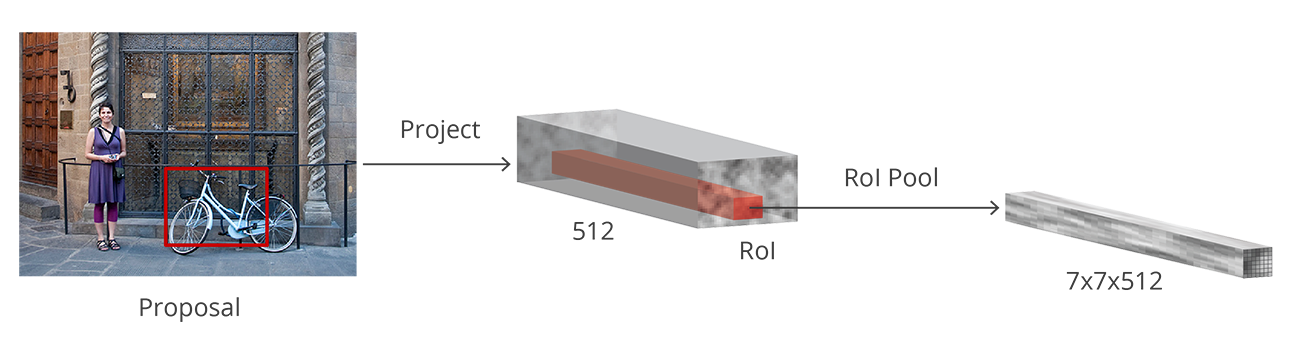
然后将这些特征图传递到完全连接的层,该层具有softmax和线性回归层。 它最终对对象进行分类并预测已识别对象的边界框。
4.2 Problems with Faster RCNN
到目前为止,我们讨论过的所有对象检测算法都使用区域来识别对象。 网络不会一次查看完整图像,而是依次关注图像的某些部分。 这产生了两个复杂性:
- 该算法需要多次通过单个图像来提取所有对象
- 由于不同的系统一个接一个地工作,系统的性能进一步取决于先前系统的执行方式
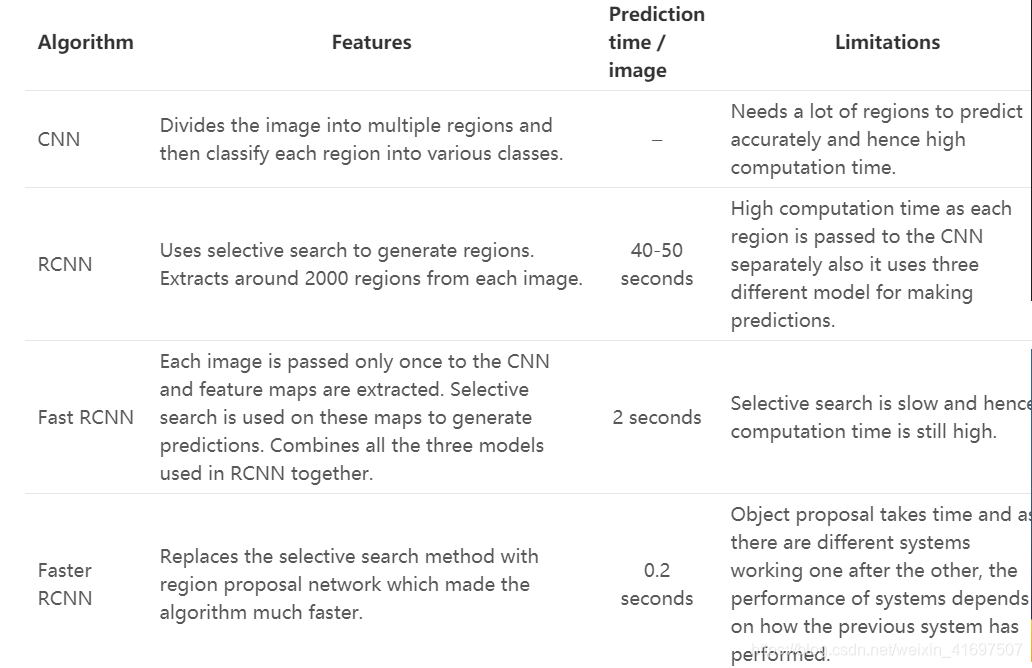
5. Summary of the Algorithms covered
下表是我们在本文中介绍的所有算法的一个很好的总结。 我建议下次你正在进行物体检测挑战时保持这个方便!
End Notes
物体检测是一个令人着迷的领域,并且在商业和研究应用中正确地看到了大量的牵引力。 由于现代硬件和计算资源的进步,这一领域的突破已经快速而突破。
本文只是我们的对象检测之旅的开始。 在本系列的下一篇文章中,我们将遇到现代对象检测算法,如YOLO和RetinaNet。 敬请期待!
我总是感谢您对我的文章提出任何反馈或建议,所以请随时在下面的评论部分与我联系。