像素:组成图片的基础单元
现在的多数表征图像的方式都是采用的RGB color space.图片可视为由width*height个像素组成.在RGB颜色空间下每一个像素是一个三元组(r,g,b),分别代表R/G/B的值.对单通道的图像(即灰度图)来说,像素是一个数.

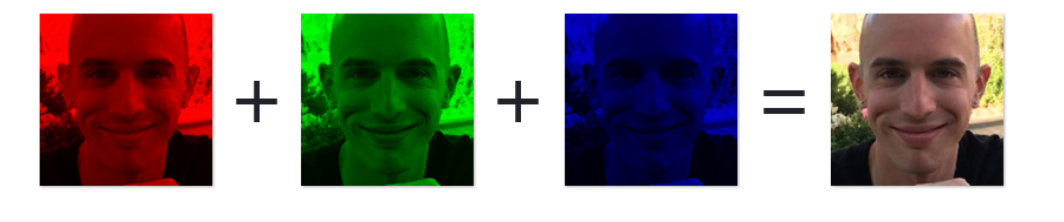
图片由一堆像素组成.[0-255]之间.从0-255由暗到亮.


用numpy array表达图片
通常用(height, width, depth)来表达一个图片.
这种表达方式是为了适应用矩阵表达.矩阵表达我们通常用rows*columns来表达一个矩阵. 对应的就是height width. 对rgb图片而言,depth就是3.
import cv2
image = cv2.imread("example.png")
print(image.shape)
cv2.imshow("Image", image)
cv2.waitKey(0)
##上述代码输出(248,300,3)意味着width是300个像素,height是248个像素.3个channel(RGB).(b, g, r) = image[20, 100] # accesses pixel at x=100, y=20
(b, g, r) = image[75, 25] # accesses pixel at x=25, y=75
(b, g, r) = image[90, 85] # accesses pixel at x=85, y=90
##image[20,100]意味着第20行第100列. x=100,y=20。 x轴的方向是width的方向,y轴的方向是height的方向.
##注意opencv返回的顺序是(b,g,r)而不是(r,g,b).为什么这么设计,不用纠结,历史原因.改变图像尺寸
通常来讲,我们在resize一个image的时候希望不改变其宽高比,因为宽高比的改变会扭曲原图.

但是对深度学习而言,这一原则并不适用.
对处理图像分类任务的神经网络或者卷积神经网络而言,我们通常假定接受的输入是一个fixed size的input.常见的卷积神经网络的输入的尺寸(width*height)有32*32,64*64,224*224,227*227,256*256,299*299.
假设我们的cnn的输入是224*224的image,但是我们的数据集里的image尺寸是312*234,800*600这种,我们要怎么做,是
- 不考虑长宽比,得到一个扭曲的图像?
- 保持长宽比,裁剪部分图像?
如下图所示:

这个没有定论,视你的具体的数据集而定.
图像分类

对上图,人是很容易识别出左边是猫,右边是狗的.但是对计算机而言,它看见的就是2个像素矩阵而已.
传统的图像识别采用特征提取+机器学习的方式,现在大火的深度学习则把特征提取这一步自动化了,自动探索特征.
图像识别的挑战

上图描述了一些常见的挑战,结合图片理解一下.
- viewpoint variation 图一个物体,只是拍摄的角度不同,对不同图片,要能够正确识别.
- scale variation 同一个物品,只是形状不同,对不同图片,要能够正确识别.
- deformation 姿态不同
- occlusion 有遮挡
- illumination 光线明暗差别
- background clutter 背景有很多噪音图片
- intra-class variration 属于同一种类,类内差别 比如图片中6个物体均应该分类为椅子
考虑到这么多复杂性,所以在构建一个图像分类系统的时候,要尽量明确你的分类目标.比如你想做一个系统,能够识别出厨房的所有物品,那将是极端复杂而且准确性很难保证的.但是如果你把系统的目标缩小到"识别出冰箱",这样一个系统更具可操作性,准确率将会更高.
机器学习中的几种不同的学习类型
- 监督学习
- 常见的有逻辑回归,svm,随机森林,神经网络
- 非监督学习
- PCA/K-MEANS
半监督学习
半监督学习很有用,因为很多时候标注数据是及其耗时耗力的. 半监督学习在用较少数据和取得较高准确率之间找到一个平衡.Popular choices for semisupervised learning include label spreading , label propagation , ladder networks , and co-learning/co-training .
其实标准很简单,根据训练集是否已经标识了正确的类别,即对某个训练图片,我是否已经知道其类别是什么.全都标识了,就是监督学习.部分标识,就是半监督,全部无标识,就是非监督学习.
深度学习用于分类
与传统的机器学习不同,深度学习省去了特征提取这一步,模型可以自己学习到特征.
深度学习steps
- 数据收集
注意:各种label的数据要均衡,比如cat图片1张,dog图片1000张.那你训练出来的model肯定对cat的识别能力很差. - 数据集划分
训练集/测试集/验证集 测试集用来测试网络效果.训练集中划分一部分出来做调参.叫做验证集. - 训练
- 模型效果评估
相比于传统的特征提取,CNN能够自动提取特征,但是坏处就是整个过程黑盒化了.你需要花很多时间来获取调参的经验.