本文为翻译的文章,作者ovais.tariq,原文:http://www.ovaistariq.net/708/on-covering-indexes-and-their-impact-on-performance/
这篇文章的目的是描述覆盖索引是什么,以及如何使用它们来提升查询的性能。人们主要使用索引来对结果进行过滤或者排序,但没有更多地思考如何通过使用恰当的索引来减少磁盘读取。所以我会向你展示,如何通过正确地利用索引来减少磁盘读取,从而提升查询的性能。
顺便说明一下,这篇文章中的例子都基于employees表,建表脚本在文末。
什么是覆盖索引
覆盖索引是一种优化的名字,用户查询的结果直接从索引返回,而不用从数据文件中去读取数据。
假定你有一个查询,并且在字段emp_no上有索引:

该查询访问的字段emp_no有索引,因而索引包含了那个字段的值,所以没有必要去访问数据文件来取值,这种优化就被称为覆盖索引。
在这个查询上运行explain:

会输出下面的结果:
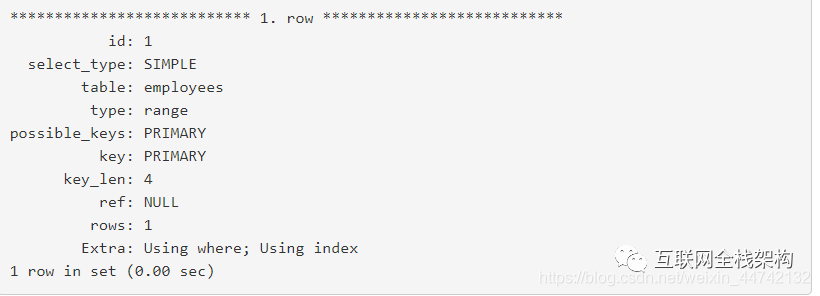
如果你看一眼Extra字段你能看到using index,它意味着MySQL仅仅通过索引就可以满足查询,因而它是一个覆盖索引优化的例子。
所以需要记住的重要原则是,sql中所有的字段都要匹配索引中的列,因为这样的话覆盖索引就可以派上用场。
让我们来理解覆盖索引如何影响性能。
覆盖索引如何影响性能
要理解覆盖索引如何来提升性能,让我们看看查询中的索引查找是如何不能从索引本身中来满足的。
执行查询的时候,在索引上会执行一次从根结点到叶结点的查找。那么,要么是叶子结点上的值本身就满足了查找(这种情况就是覆盖索引),要么必须执行随机的I/O操作从磁盘读取数据。所需要的读操作次数依赖于索引的类型:
-
如果是在一个主键索引或者唯一索引进行查找,那么最多需要一次随机读取,因为主键/唯一索引的值对应单独的一行记录。
-
如果是在一个非唯一索引上执行查找,那么可能一共可能需要N次随机读取,N是索引值对应的行数。
随机读取对性能不利,你总是想要找到减少它们的办法。覆盖索引很好,因为你不需要额外的磁盘读取来取值,因为它们就在索引上。
你应该记住一些重要的关于索引和InnoDB的考虑。InnoDB中的辅助索引需要两次索引查找,所以覆盖索引就更重要了,因为它们节省了2xN随机读操作。而且,InnoDB中的辅助索引自动包含了主键索引值,所以在某些场景下,他们能自动扮演覆盖索引的角色。
现在理论已经够了,让我们来看看实战中的覆盖索引。
实例
假定你想找到在2000年第一个月入职的员工:

下面是exlain的输出:
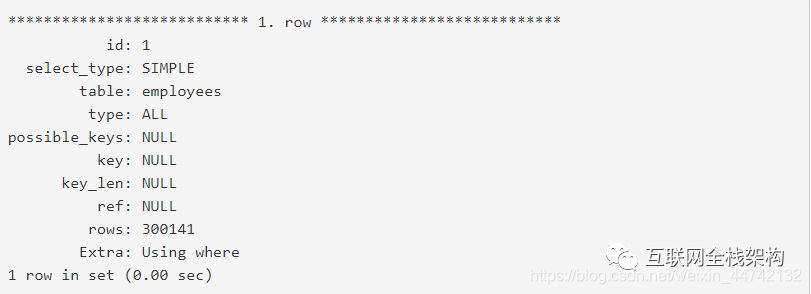
查询用了0.12秒
让我们在hire_date上加一个索引(记住这是一个InnoDB的表,emp_no字段会自动成为索引的一部分):

再次运行explain,输出结果如下:
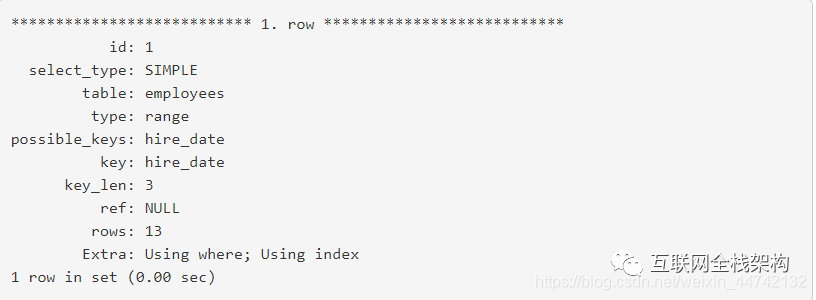
现在查询用了0.00秒。
我希望你理解覆盖索引是怎么提升查询的性能的,但确保没有添加过多的不必要的索引,因为在插入/更新操作的时候,索引增加了更多的开销。
建表脚本:
CREATE TABLE employees (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
)
ENGINE=InnoDB;
欢迎关注微信公众号,获取更多信息。
