文章目录
本文涉及到的一些内容如有不懂的话,可以先看一下我的另一篇文章:
《【mysql知识点整理】 — mysql索引底层数据结构》
1 回表查询、覆盖索引概念简介
这两个概念其实在我前两篇文章 《【mysql知识点整理】 — mysql索引底层数据结构》、《【mysql知识点整理】— mysql执行计划详解》里提到过,这里再强调一下。
首先应该知:
- InnoDB的主键索引底层使用了B+树的数据结构,它的叶子节点包含了所有的索引以及相应索引对应的整行数据,且从左到右是按索引值由小到大进行有序排列的 — > 主键索引又称为
聚簇索引; - InnoDB的非主键索引(这里不考虑HASH索引和全文索引)也使用了B+树的数据结构,叶子节点也包含了所有的索引值,但是与主键索引或者说聚簇索引不同的是它并没有存储索引对应的整行数据,而是存储了相应索引对应的主键值;
对应的数据结构可以用下面的图进行表示,其中:
- Primary Key 对应主键索引
- Secondary Key 对应一个单列非主键索引
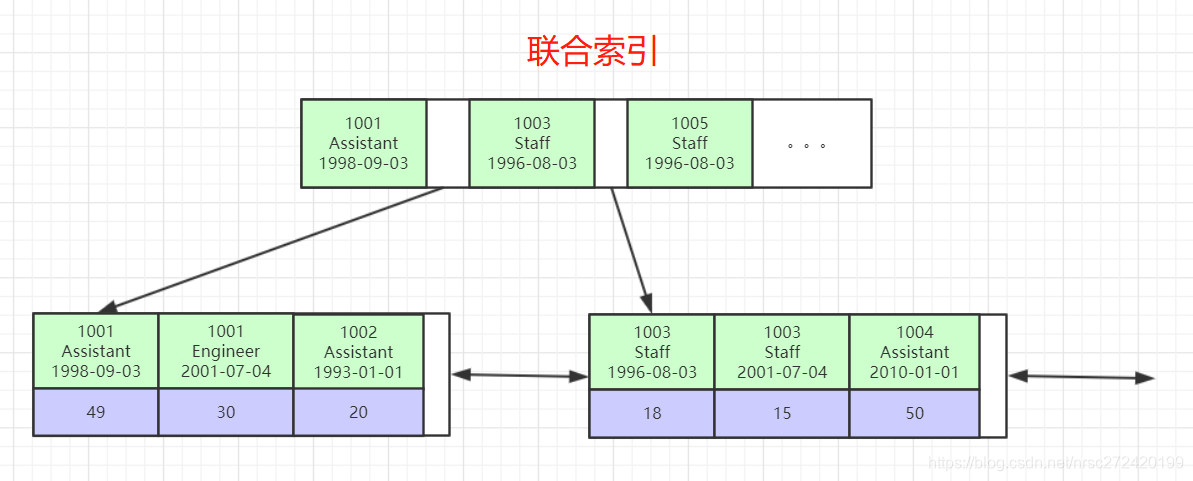
- 最后一张图为多列组成的联合索引
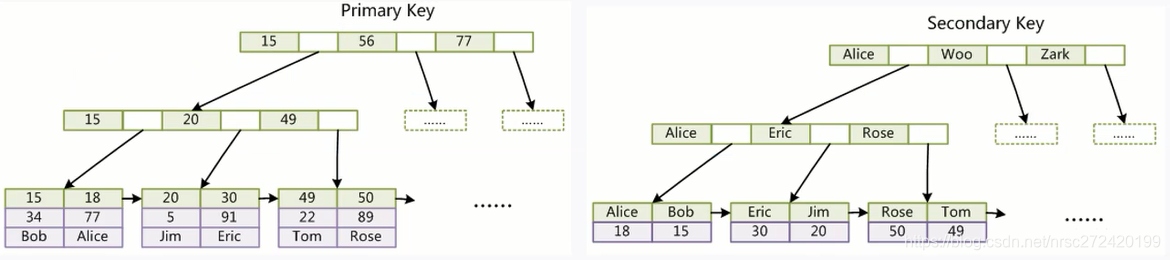
如上图所示,使用InnoDB引擎进行创建的表,其实表中的所有数据是和主键索引放在一起的。因此:
- 如果查询条件为主键列,那么就可以直接遍历主键索引对应的B+树,然后从主键索引中取出想要的数据。
- 但是假如查询条件为非主键列,且在查询条件所涉及的列上建立了索引,
并用到了该索引(有可能会用不到,尤其看到上面联合索引的数据结构图,你能不能想到为什么有时候会用不到???)那就会出现如下两种情况:- 情况1:
想要查询的数据,如果就在该索引的索引树中—> 那就可以直接通过遍历该非主键索引树获得想要的数据- 比如下面的语句,id为主键,且在name列上加了索引,由于name列对应的索引树上,不仅存了各个name的值,还存了各个name所对应的主键列的值,因此直接通过遍历name所在的索引树就可以取出id和name两个属性.
这种情况下相当于该非主键索引包含了(或覆盖了)想要查询的所有数据 — 》 因此可以称为select id, name from employee where name = 'Lily';索引覆盖,但也有资料称这种索引就叫覆盖索引。
- 比如下面的语句,id为主键,且在name列上加了索引,由于name列对应的索引树上,不仅存了各个name的值,还存了各个name所对应的主键列的值,因此直接通过遍历name所在的索引树就可以取出id和name两个属性.
- 情况2: 想要查询的数据,有一部分不在该非主键索引的索引树中 —> 其实很好理解,这种情况下,肯定是要先通过该非主键索引树定位到要查询数据的主键索引值,再拿着主键索引值去主键索引树中真正定位到要查询的数据。 —> 这样就出现了要遍历两个索引树的情况 —>这种情况就是所谓的
回表查询。- 工作中应该尽量避免出现回表查询
- 在使用联合索引时应格外注意
- 情况1:
2 InnoDB引擎数据存储方式猜想
本部分为自己猜想的,不一定是对的,欢迎批评指正。
2.1 非叶子节点 — 怎么会就正好每次都能读取到4页的索引数据?
首先我们应该知道 : 默认情况下,每个节点存放的索引值加起来大小为16K (4页),即mysql每次I/O能读取的数据量。
根据该值加上我们索引字段所占的字节数可以计算出每个节点究竟能存多少个索引值。可以参考我下面这篇文章:
《从B+树的角度聊一聊为什么阿里的《JAVA开发手册》强制要求mysql表的主键应为bigint unsigned类型》---- 但这不是我主要想表达的重点。
不知道在这里你会不会有这样的想法? —》 哟,这么巧?每次I/O只能读4页的内容,你这4页就正好全是索引!!! —》 那你这4页的内容就肯定都在一个磁盘的扇区喽 —》 也就是这些索引的内存地址肯定是连续的喽。
这就有意思了?随着数据量由少变多 , B+树的结构肯定是会被破坏的? — 》 但是你却每次I/O还是能获取到当前节点对应的4页的索引值 —》 这说明什么呢? —》我猜肯定是:
B+树的结构被破坏后,InnoDB引擎会依据重新构建的B+树为每个节点(也许是涉及到的会变的节点)重新申请4页的连续内存空间
2.2 聚簇索引叶子节点存储方式猜想 — 我真正最想聊的内容★★★
读完2.1不知道你会不会有这样的想法? —》为了能在读取非叶子节点时,每次I/O读到的数据都为索引数据 —》 InnoDB引擎有可能专门为这些节点重新申请分配过连续的内存空间,那这种操作会不会也在聚簇索引的叶子节点进行?
即随着索引树结构的破坏与重建,动态的为数据库表里的数据重新申请连续的内存空间 或者说还有一种可能:因为主键索引通常都是递增的,在叶子节点的表现就是从左到右依次增大---》也就是说后插入的数据肯定在右边,那InnoDB引擎就可以在存储数据时,先申请一个数据块,大小就为4页,插入数据时就往这个数据块里插。如果这个数据块里存储的数据满4页了,就再申请一个这样的数据块。。。这样就可以保证每个叶子节点(即我说的数据块)里数据的内存地址就是连续的了 。
如果真是这样,那在遍历到聚簇索引的叶子节点时,每次I/O就可以读取到的全是这个数据库表里的数据了。
但是这样应该会降低插入、删除或更新数据时的效率。。。
之所以有这种疑问,是因为我们都知道,在实际生成中,当一张数据库表建好后,里面的数据往往是在不同时间点进行插入的,因此每张表里一行行的数据在磁盘中应该肯定不是按照顺序依次排列的。也就是说对于一张数据库表而言,它每一行的内存地址都是随机的,如下图所示:
但是到底是不是这样呢??? — 欢迎留言讨论。。。
我觉得应该肯定是
但要注意,我说的不是每行记录的内存都是连续的,而是每个聚簇索引的叶子节点中的数据,内存地址应该是连续的,也就是遍历到聚簇索引的叶子节点时,每次I/O应该读取的都是该表对应的数据。
有兴趣的可以再读读我的另一篇文章《【mysql知识点整理】 — mysql索引底层数据结构》,或许你会有跟我一样的认识。
其实说实话之所以写这篇文章就是我感觉我脑子里一直有两个声音在折磨着我:
(1) InnoDB表中每一行的地址基本不可能是连续的 ;
(2)通过聚簇索引进行查询,遍历到叶子节点时可以通过一次I/O读取到4页的表数据 —》 即表中有部分数据内存地址应该是连续的。
具体怎样,或者官网哪里有介绍??希望有知道的可以在评论区里告诉我。。。多谢!!!
