版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Stream_who/article/details/86320275
一、存储引擎基本概念
1. 存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式
2. 存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型
3. Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎
4. InnoDB的选择场景
1)更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求
2)事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎
3)自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复
4)外键约束。MySQL支持外键的存储引擎只有InnoDB
5)支持自动增加列AUTO_INCREMENT属性
二、InnoDB
1. 从MySQL5.5.8,InnoDB成为MySQL默认的存储引擎。MySQL从3.23.34a开始支持InnoDB
2. 特性
1)InnoDB支持事务,主要面向OLTP(联机事务处理过程)数据库应用
2)支持行锁,支持外键,并支持类似于Oracle的行锁定读,即默认读取操作不会产生锁
3)InnoDB存储引擎中支持自动增长列AUTO_INCREMENT。自动增长列的值不能为空,且值必须唯一,且必须为主键。在执行插入操作时,若不指定自动增长列的值,或自动增长列的值为0或NULL,则插入的值为自动增长后的值
4)InnoDB存储引擎中,创建的表的结构存储于.frm文件中。数据和索引存储在innodb_data_home和innodb_data_path表空间中
5)对于表的数据存储,InnoDB存储引擎采用了聚集的方式,每张表的存储都是按主键顺序进行存放。若没有显示地在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
6)InnoDB通过多版本并发控制(MVCC)来获得高并发性,并实现了SQL标准的4种隔离机制,默认为REPEATABLE级别。同时使用一种被称为next-key locking的策略来避免幻读。InnoDB还提供了插入缓冲、二次写、自适应哈希索引、预读等高性能和高可用的功能
三、索引
1. 基本概念
1)索引的原理是因为使用了B+树结构,InnoDB的聚簇索引是索引(主键)和数据在一起。
2)索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
3)索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间
2. 索引的优点与缺点
1)优点
(1)所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
(2)大大加快数据的查询速度
2)缺点
(1)创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
(2)索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
(3)当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度
3. 索引分类
1)单列索引(一个索引只包含单个列,但一个表中可以有多个单列索引)
(1)普通索引 MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点
(2)唯一索引 索引列中的值必须是唯一的,但是允许为空值
(3)主键索引 不允许有空值
2)组合索引
(1)在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合
3)全文索引
(1)在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行
(2)全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引
4)空间索引
(1)空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON
(2)在创建空间索引时,使用SPATIAL关键字
4. 聚簇索引与非聚簇索引
1)聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引
2)除了聚簇索引,其他都是非聚簇索引,需要先查自己某个字段的索引顺序,再查聚簇索引(数据顺序)
四、InnoDB的锁
1. 悲观锁和乐观锁
1)悲观锁
(1)每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁
(2)传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁
(3)它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态
(4)悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)
2)乐观锁
(1)不会加锁, 但是更新的时候会进行判断, 判断跟原始的数据一不一样,返回受影响行数, 如果不一样,他会返回受影响的行数为0, 如果一样,会返回受影响的具体数量, 我们可以通过返回值,来采取对应的措施,比如回滚还是从新执行一遍
(2)每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制
(3)乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁
2. 按粒度大小分类
1)表级锁(开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突概率高,并发度最低)
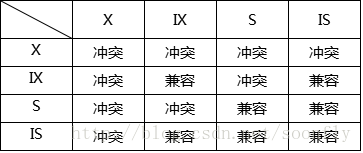
意向锁是InnoDB自动加的,不需用户干预
(1)意向共享锁(IS)
(2)意向排它锁(IX)
2)行级锁(开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高)
(1)共享锁(S锁)
a. 也叫读锁,用于所有的只读数据操作。共享锁是非独占的,允许多个并发事务读取其锁定的资源
b. 多个事务可封锁同一个共享页
c. 任何事务都不能修改该页
d. 通常是该页被读取完毕,S锁立即被释放
(2)排它锁(X锁)
a. 也叫写锁,表示对数据进行写操作。如果一个事务对对象加了排他锁,其他事务就不能再给它加任何锁了
b. 仅允许一个事务封锁此页
c. 其他任何事务必须等到X锁被释放才能对该页进行访问
d. X锁一直到事务结束才能被释放
3)页级锁(开销和加锁速度介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发度一般)
4)间隙锁(Next-key锁)
(1)当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁
(2)对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁
(3)它的作用是防止幻读
3. 显式加锁(事务可以通过以下语句显式给记录集加共享锁或排他锁)
1)共享锁(S): SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
2)排他锁(X): SELECT * FROM table_name WHERE ... FOR UPDATE
4. 死锁
参考网址
注:文章是经过参考其他的文章然后自己整理出来的,有可能是小部分参考,也有可能是大部分参考,但绝对不是直接转载,觉得侵权了我会删,我只是把这个用于自己的笔记,顺便整理下知识的同时,能帮到一部分人。
ps : 有错误的还望各位大佬指正,小弟不胜感激