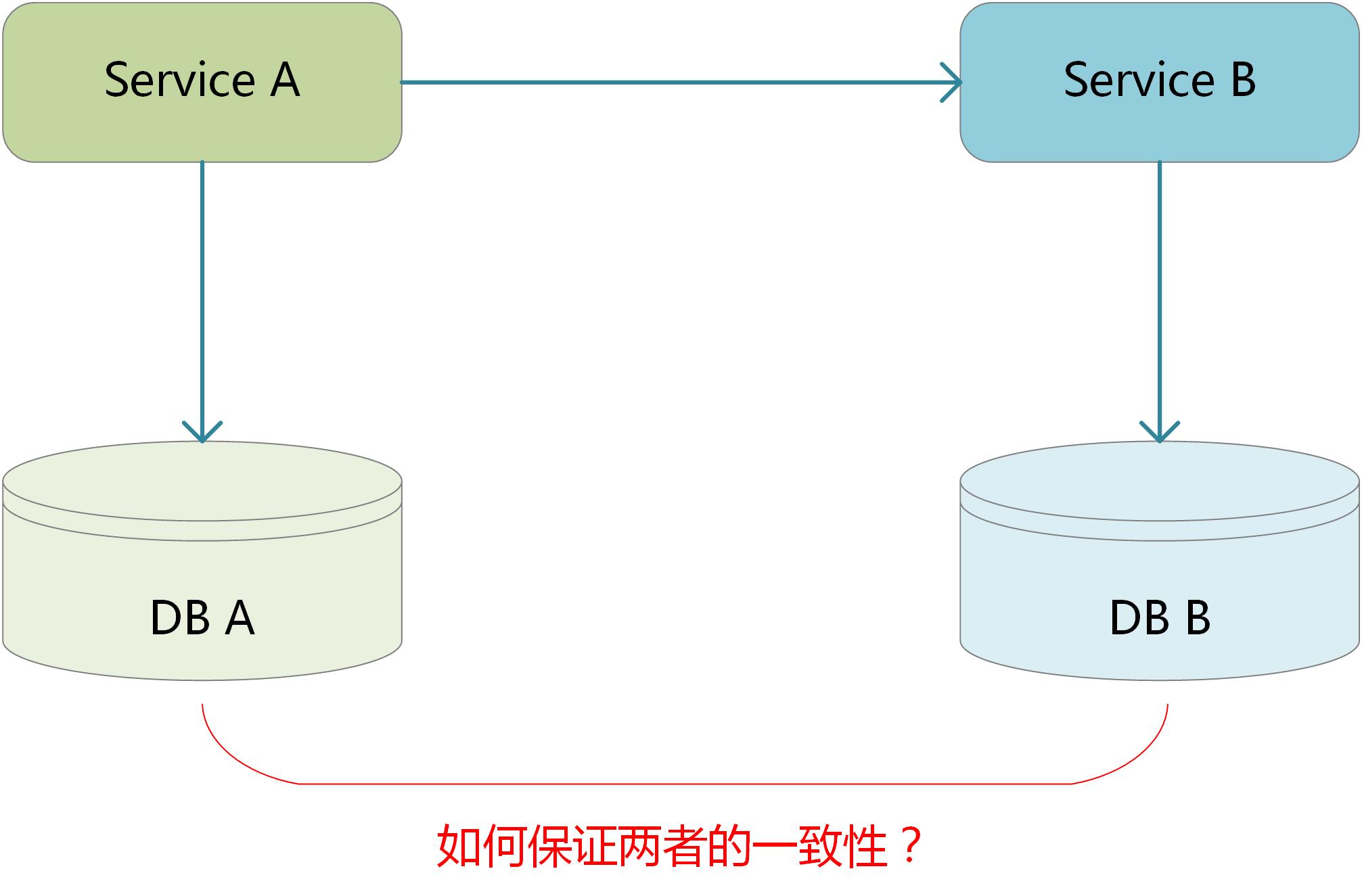
如上图所示场景,服务A通过网络访问服务B,同时两服务分别写数据到DB A、DB B。这样在特殊情况比如网络、机器、数据库等异常下可能导致DB A、DB B之间产生不一致的情况,如下:
第一种情况,DB A成功落库数据后,但是访问服务B失败或服务B写数据失败。就像一笔跨行转账,这边扣了钱,对方却没收到钱,就给用户造成了资损。

第二种情况,访问服务B成功、并且DB B成功落库,但是服务A写数据到DB A时失败了。在跨行转账来说同样严重,对方收到了钱,这边却没扣钱,银行就出现了资损。
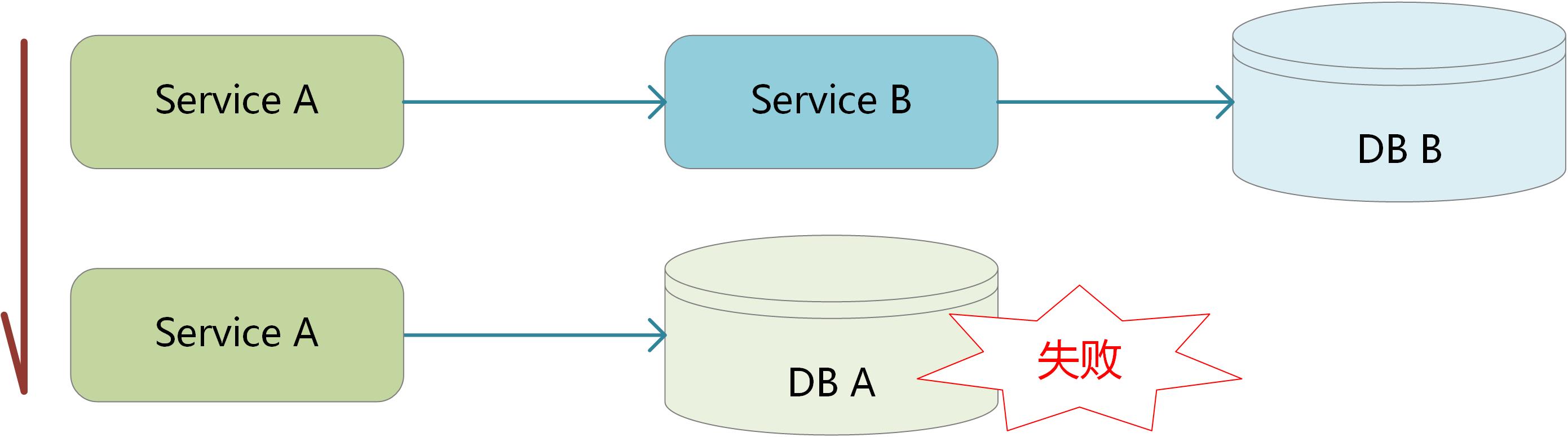
因为存在两个数据库操作,就无法保证两者间的强一致性。按照BASE理论(Basically Available:基本可用、Soft state:软状态、Eventually consistent:最终一致性),可以降低一定的级别,通过增加软状态来保证其最终一致性。即其中一方作为主逻辑,另一方采用TCC机制来适配:
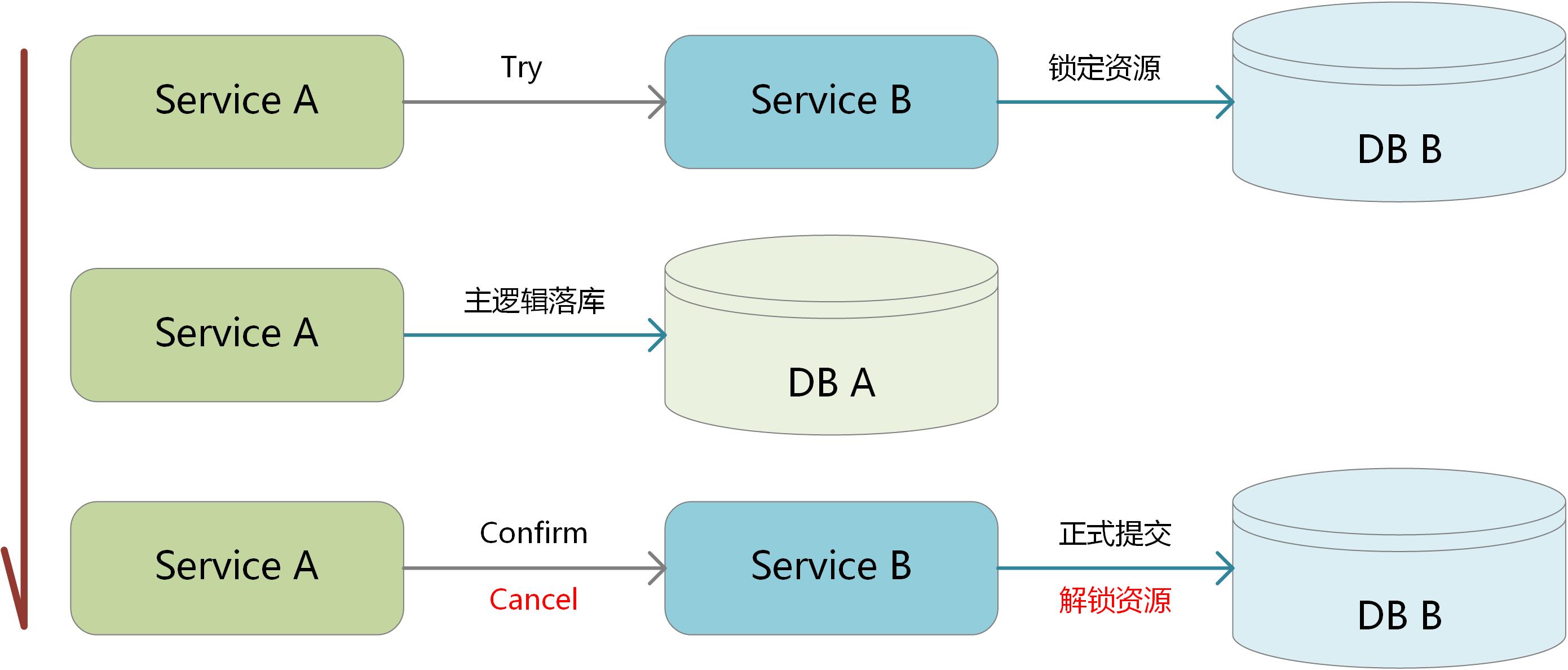
T:Try,锁定所有需要消耗的资源。可能出现锁定失败的情况
C:Confirm,将T阶段锁定的资源执行正式扣减,因为没有资源抢占的情况,该步骤理论上一定能成功
C:Cancel,将T阶段锁定的资源解锁恢复原样,理论上也一定能成功
服务A作为主逻辑,服务B增加软状态
服务B增加状态:初始、成功、失败。
| 初始 | Try,锁定所有需要的资源,要消耗的资源(钱)则先冻结,要增加的资源则不需要处理 |
| 成功 | Confirm,将初始阶段冻结的资源实际扣减掉 |
| 失败 | Cancel,将初始阶段冻结的资源解冻恢复正常状态 |
3步,每一步都要依赖上一步的执行结果,第3步要根据第2步的结果决定是Confirm、还是Cancel。另外当需要拦截业务时则应尽可能早的拦截,所以可以调整为Service A 先检测开启本地事物并检测各项逻辑,通过后才Try Service B:
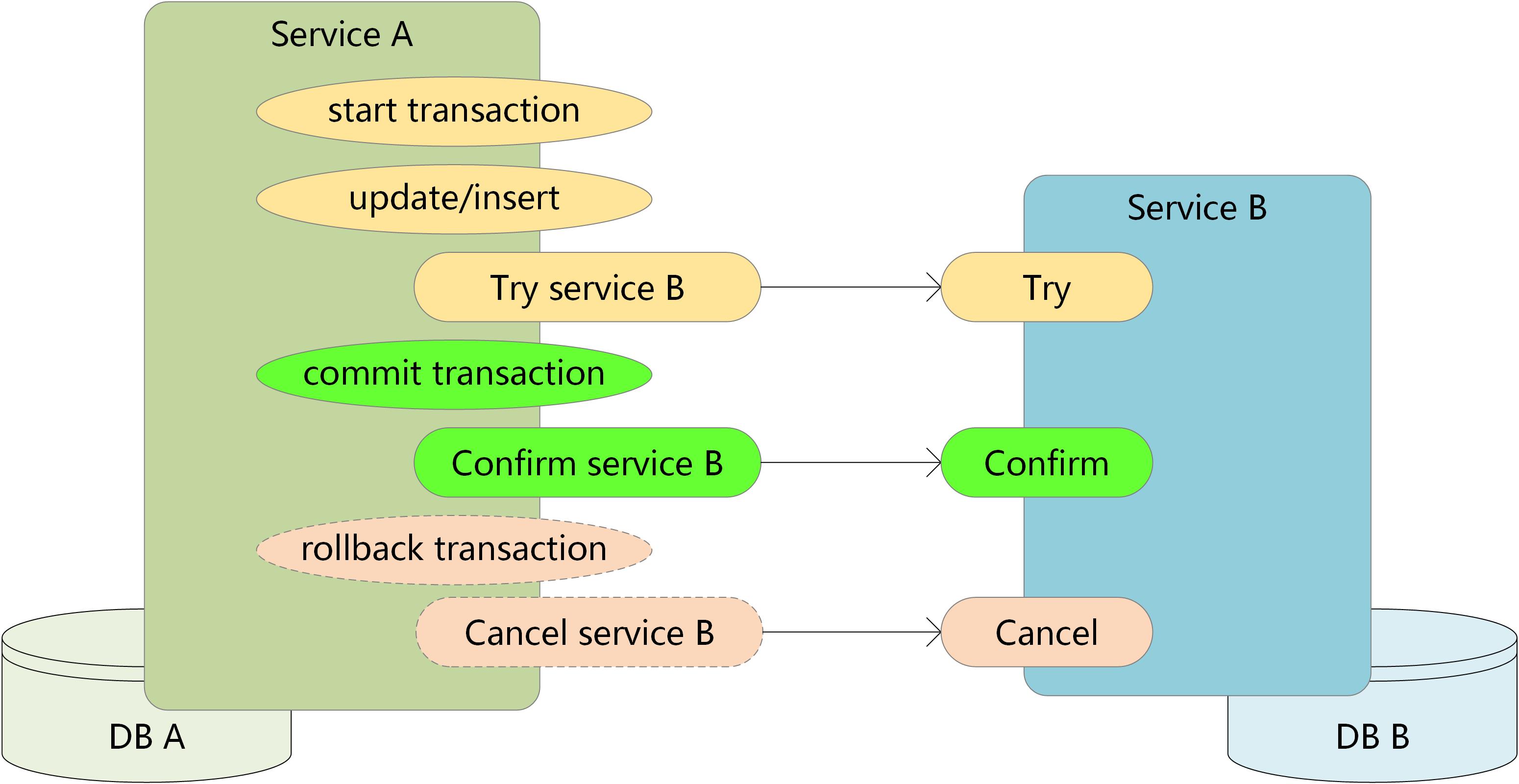
特殊情况很可能最后一步因为网络异常、机器异常等原因执行失败了,也就是流程中断了,需要有一种机制继续执行剩余的流程,这个机制就是补单。
补单:排查DB B内所有状态为初始(Try)的流程,然后检测DB A的主逻辑是否已成功落库,若已落库则调用Service B的Confirm接口;若不存在则调用Service B的Cancel接口。
服务B作为主逻辑,服务A增加软状态
服务A增加状态机:初始、成功、失败。
| 初始 | 服务A已成功落库数据,但是可能还未访问服务B、或已访问服务B但是未成功记录状态到本地,需要再次访问服务B以确定结果 |
| 成功 | 到达终态,已成功访问服务B |
| 失败 | 到达终态,访问服务B明确失败,并且本地已回滚处理(比如曾经扣掉用户的钱,再给人家加回去) |

第1步成功,第2、3步若出现失败的话,同样也需要通过补单逻辑来继续执行未完成的流程。
补单:捞取DB A内所有为初始(Try)状态的流程,通过直接访问Service B的接口(需支持幂等)确定Service B状态,根据具体状态执行Service A的正式提交或解锁资源。