如何保证缓存数据一致性
公司技术分享转载
一. WHAT 什么是缓存?
常见缓存有: 计算机内存, CPU缓存, 数据库缓存, Redis缓存, 服务器缓存, CDN, 浏览器缓存…
→ 在近用户端或支持高速读取的位置, 对使用频繁的数据进行冗余存储, 以达到加速读取数据的目的
→ 以加速读取为目的的冗余数据
二. WHY 为什么会有缓存数据一致性问题?
大家应该都听过这样一个段子:
说有个人夸自己口算非常快, 有不信的人就给他出了个复杂的计算题, 这个人想也没想随口就说了一个答案, 并狡辩: “我只是说我算的快, 但并没说我算的准呀!”…哄然
所以速度需要建立在正确性的基础上, 才会有意义
我们继续说缓存, 既然缓存是一种冗余数据, 那就存在与之对立的原始数据, 缓存的加速也同样需要建立在正确性上才更有意义, 也就是需要保证缓存的冗余数据与原始数据的一致性
那如果原始数据变动了, 而冗余数据并未跟着改变, 这就产生了缓存一致性问题
三. HOW 如何保证缓存数据一致性?
我们今天主要基于大家最常用的redis缓存来看, 如何保证Redis缓存与DB数据的一致性
1. 先上结论

- 其他相关结论
- 为什么推荐删缓存而不是更新缓存: 并发场景下, 更新更容易产生数据不一致, 且删除缓存操作可提高缓存利用率
- 延迟双删缺点: 延迟时间难于评估, 不推荐
- 删除重试机制缺点: 需要在业务代码中引入删除失败时触发的逻辑, 存在一定代码侵入性, 不推荐
- 监听binlog补偿机制缺点: 有一定延迟, 高并发写场景下延迟明显, 因此高并发写场景不推荐
- 是否可以做到缓存数据强一致性: 可以, 但性能低, 与引入缓存的初衷相违背
2. 定时更新缓存
即将数据全量写入缓存, 定时更新, 优劣如下:

- 优点:
1. 所有读请求都可以直接命中缓存, 不需要再查数据库, 性能非常高 - 缺点:
1. 缓存利用率低:不经常访问的数据, 还一直留在缓存中
2. 数据不一致:因为是「定时」刷新缓存, 缓存和数据库存在不一致(取决于定时任务的执行频率)
这种方式一般仅用于项目体量不大且数据一致性敏感度不高的场景, 例如企业内部系统中员工入职信息次日生效等
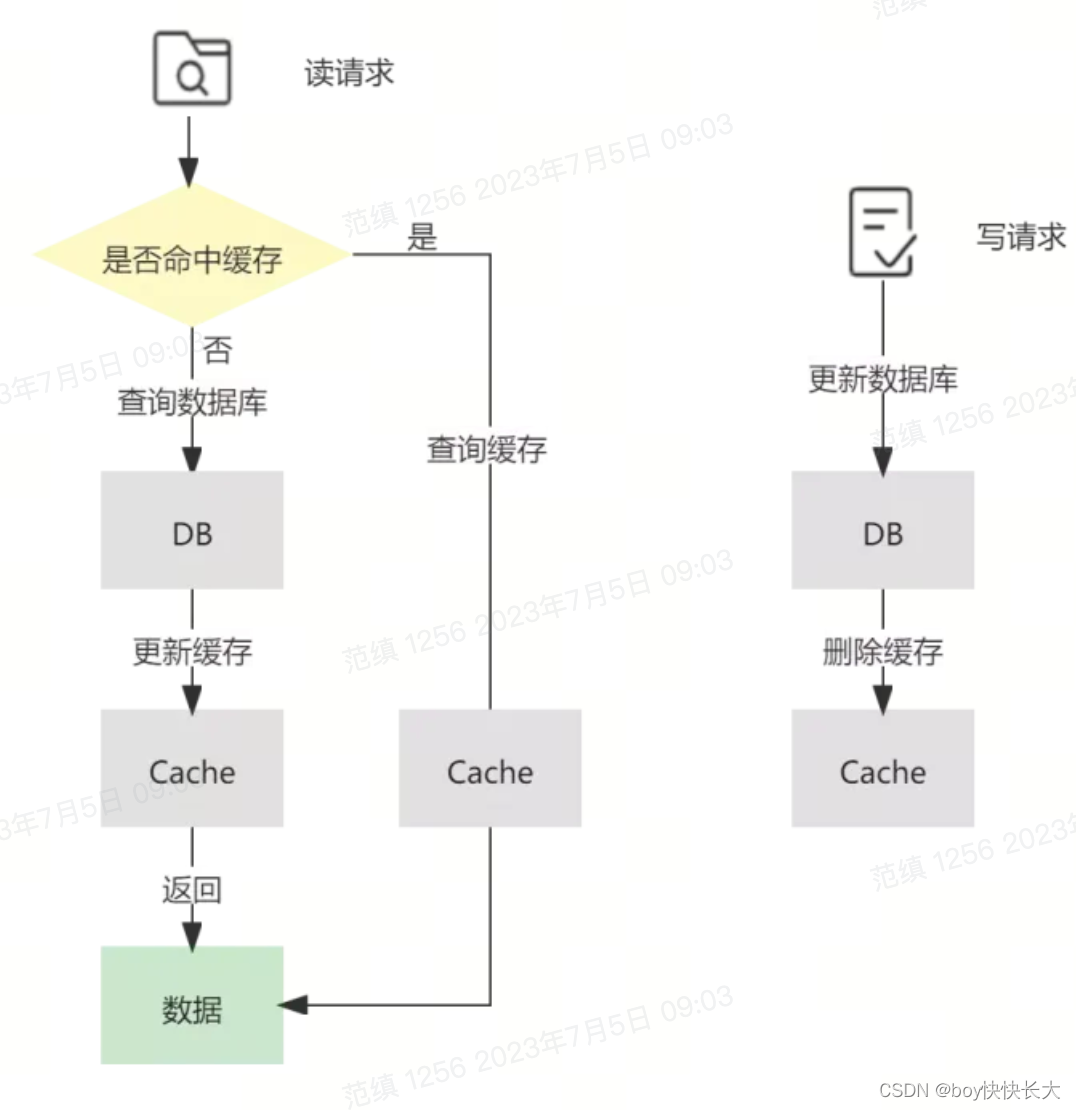
3. Cache-Aside 旁路缓存模式
3.1 介绍
Cache-Aside (旁路缓存模式), 具体操作逻辑如下
- 在读请求中, 首先请求缓存
a. 若缓存命中, 则直接返回缓存中的数据
b. 若缓存未命中, 则查询数据库并将查询结果更新至缓存, 然后返回查询出的数据 - 在写请求中, 先更新数据库, 再删除缓存。
3.2 为什么选择删除缓存, 而不是更新缓存?
- 性能方面: 当缓存计算较耗时, 会增加操作耗时, 降低服务的吞吐量, 同时如果写操作较多, 有可能出现缓存扰动 (刚更新的缓存还未被读取, 又要再次更新), 浪费服务器资源, 读时更新为懒加载思想
- 安全方面, 并发场景中更新缓存会引发数据不一致问题
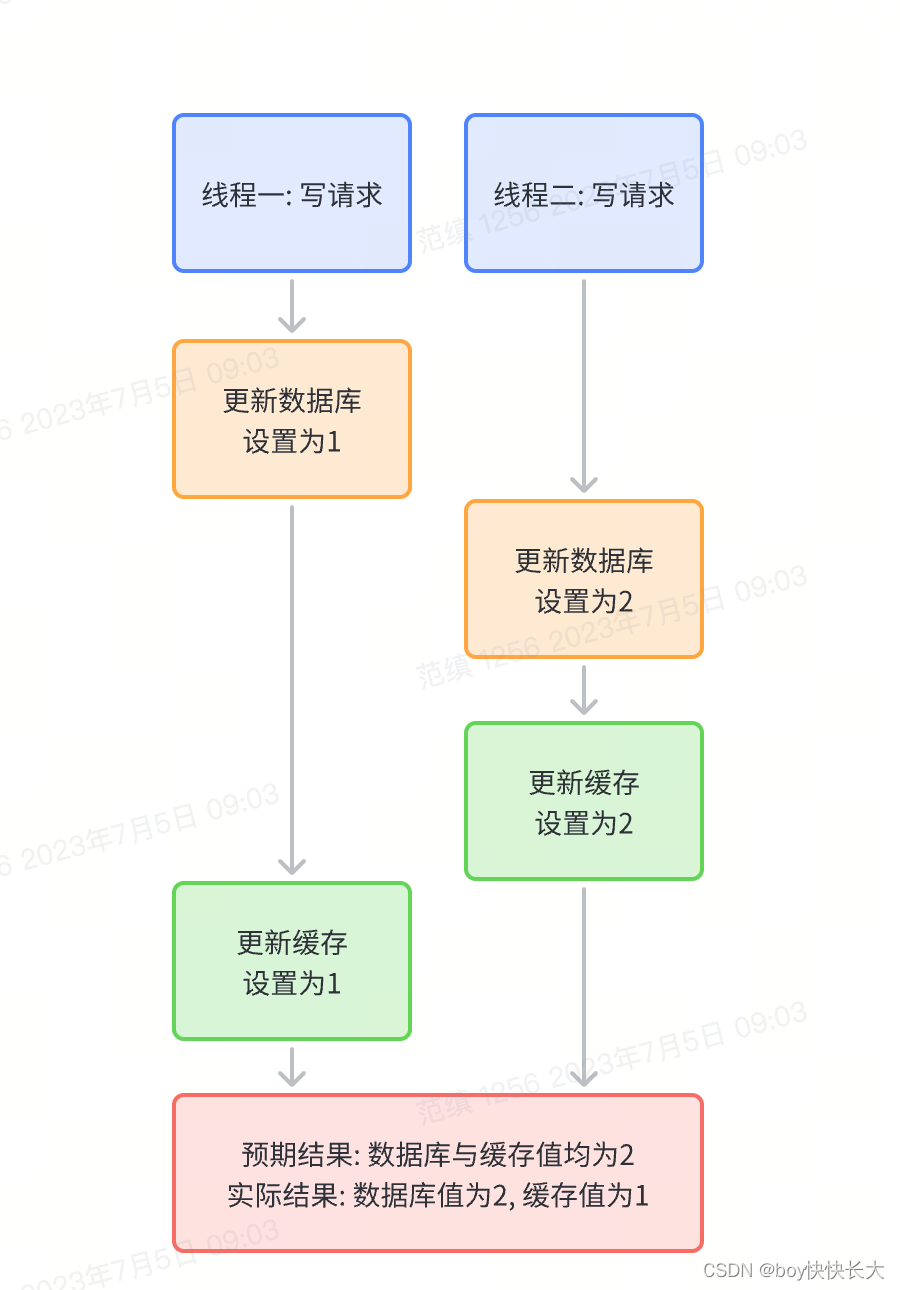
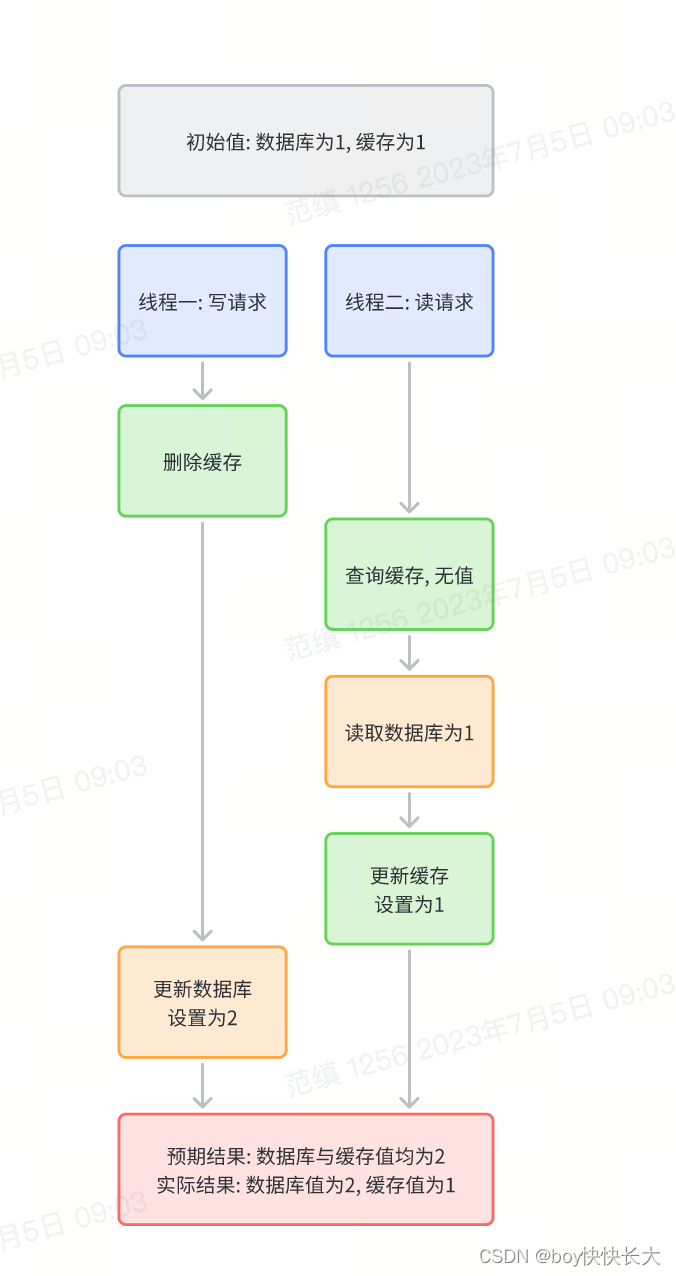
3.3 为什么选择后删缓存, 而不是先删缓存?
先删缓存会存在数据一致性问题, 产生场景:
此场景可以通过延时双删方式进行解决:
![[图片]](https://img-blog.csdnimg.cn/588ec90c62fe4521994fb4d9a451b95e.png)
在更新数据库之后, 延迟一段时间再次删除缓存, 但为了保证第二次删除缓存的时间点在读请求更新缓存之后, 这个延迟时间的经验值通常应稍大于业务中读请求的耗时。延迟的实现可以在代码中sleep或采用延迟队列。显而易见的是, 无论这个值如何预估, 都很难和读请求的完成时间点准确衔接, 这也是延时双删被诟病的主要原因。
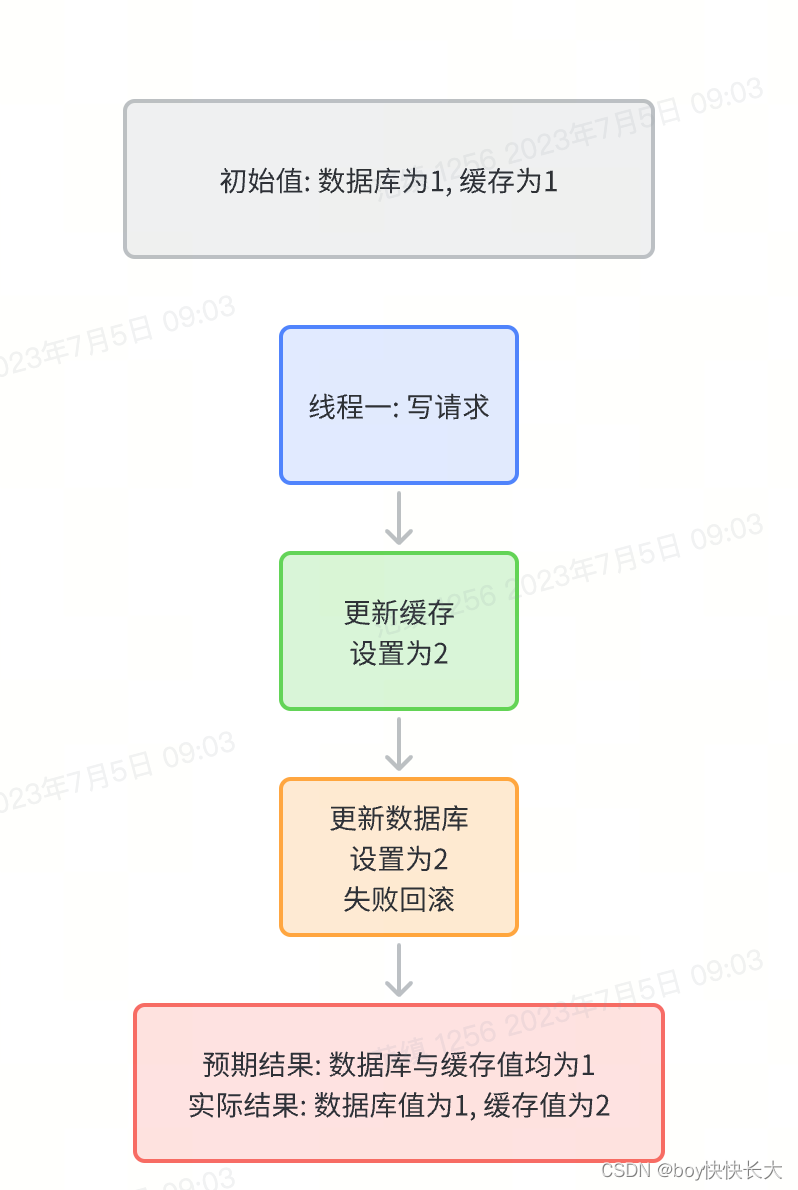
3.4 先更新缓存, 再更新数据库是否可行?
不行, 先更新缓存的话极易存在数据不一致问题
3.5 Cache-Aside是否完美?
3.5.1 仍然存在数据不一致的可能性
tips: 以下场景均建立在删除缓存成功的条件下
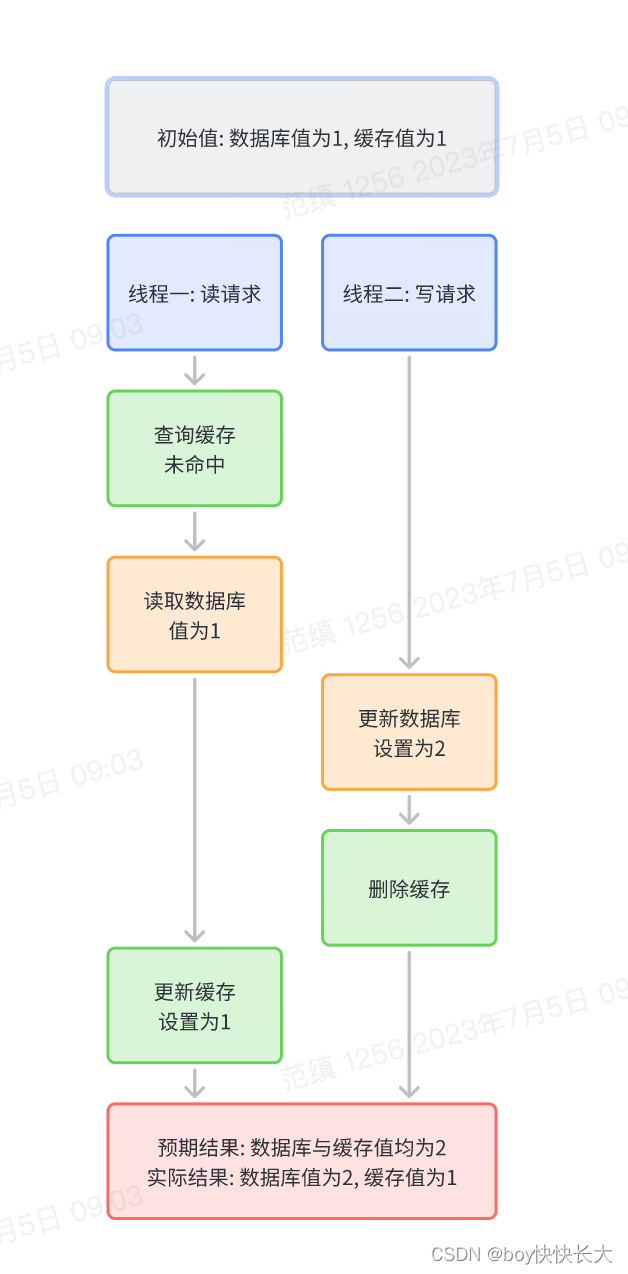
不一致场景1:
此场景需要读请求耗时比写请求更长才会发生, 例如查询语句较慢或计算缓存逻辑耗时较长, 需要尽可能避免
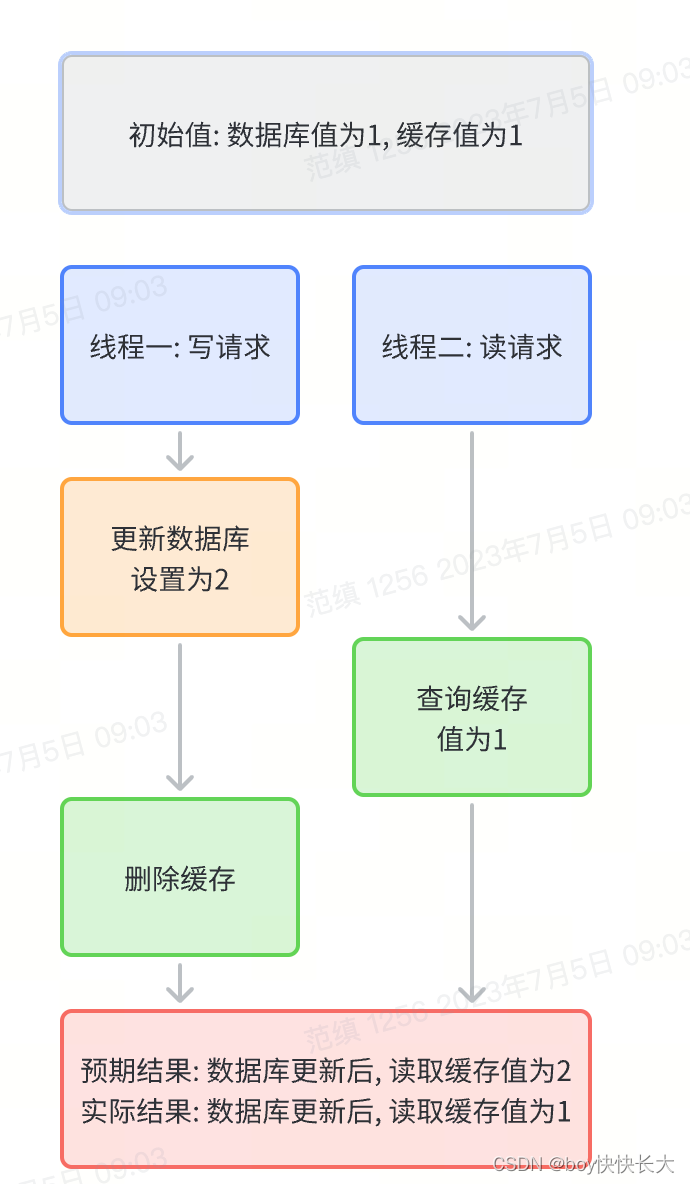
不一致场景2:
此场景只是一时的不一致, 最终是一致的, 如果业务对上述场景容忍度很低, 可通过加锁方式处理, 即在写请求中进行加锁, 读请求在写请求结束后才能执行, 当然加锁操作会损耗部分性能
3.5.2 删除缓存后易产生缓存击穿问题
3.6 Cache-Aside补偿机制
针对Cache-Aside的不一致场景1及删除缓存失败导致数据不一致的问题, 需要延迟再次删除缓存, 以实现最终一致性
3.6.1 延迟双删
解决Cache-Aside的不一致场景1, 但也会有上面提到的延迟时间选择的问题
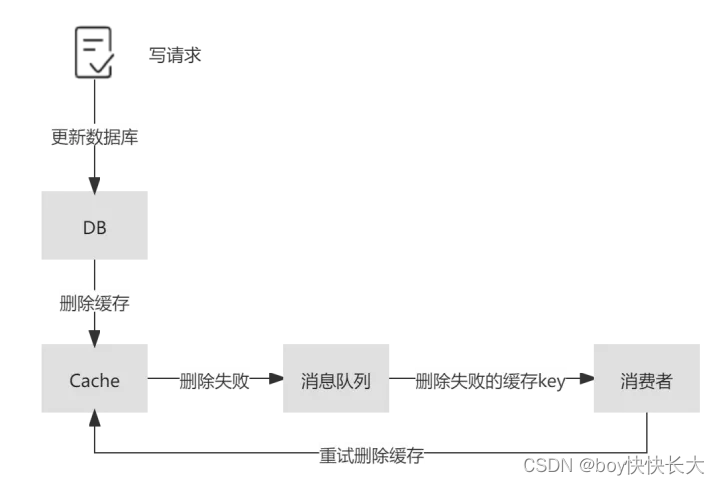
3.6.2 删除重试机制
由于同步重试删除在性能上会影响吞吐量, 所以常通过引入消息队列, 将删除失败的缓存对应的key放入消息队列中, 在对应的消费者中获取删除失败的key, 异步重试删除。
这种方法在实现上相对简单, 但由于删除失败后的逻辑需要基于业务代码来触发, 对业务代码具有一定入侵性。
此方式只解决了删除失败的情况
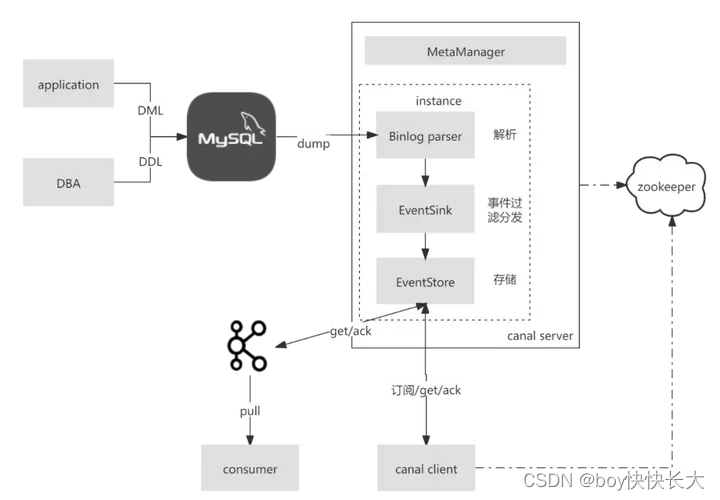
3.6.3 基于数据库日志(MySQL binlog)增量解析、订阅和消费
鉴于上述方案对业务代码具有一定入侵性, 所以需要一种更加优雅的解决方案, 让缓存删除失败的补偿机制运行在背后, 尽量少的耦合于业务代码。
基于MySQL数据库增量日志进行解析和消费, 这里较为流行的是阿里的canal, 基于其监听mysql的binlog日志, 实现有序增量地感知数据的变化, 以触发缓存的删除操作
这样, 结合Cache-Aside模型以及数据库日志增量解析消费的方案, 在写请求更新数据库后删除缓存, 并基于binlog日志再来补偿数据库更新时可能的缓存删除失败问题, 在绝大多数场景下, 可以有效的保证缓存的最终一致性。
如果Cache-Aside的不一致场景1中缓存更新时间晚于了基于binlog的延迟删除时间, 则仍然不一致, 但这种场景就极少了
另外需要注意的是, 需确保数据库入库后再进行缓存的删除操作。在数据库的主从架构读写分离场景下, 需让canal监听从库, 避免过早删除缓存而从库数据还未更新, 导致读取到旧值的问题
4. Read-Through & Write-Through 读写穿透模式
此模式多用于服务端把Cache视为主要数据源, 通过建立Cache服务或组件作为访问控制层, 封装缓存与数据库的交互, 服务端只关注业务逻辑即可
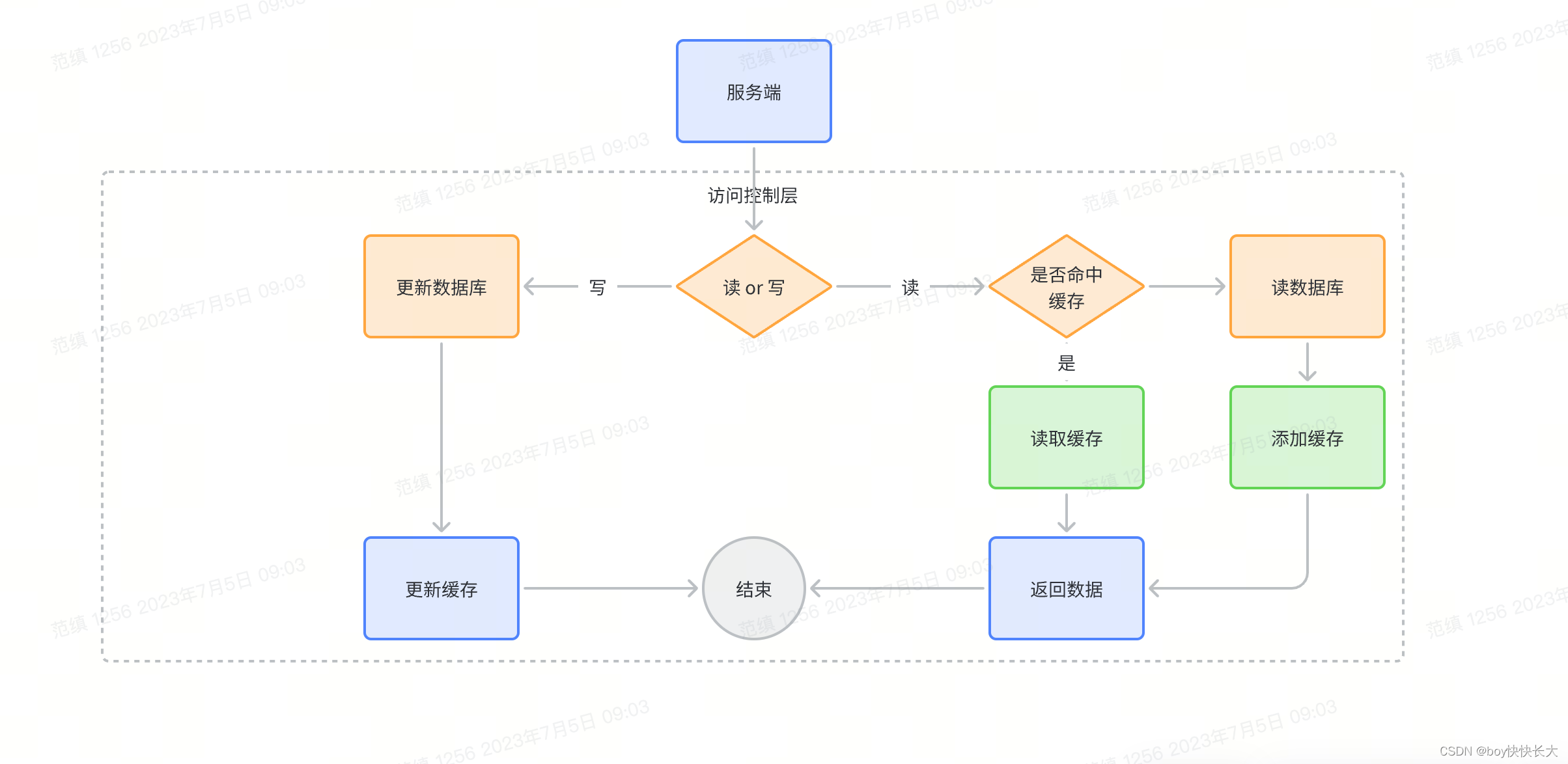
要使用这种方案, 必须做到以下几点:
- 写操作时, 更新数据库和更新缓存操作统一作为事务处理, 同时失败或者同时成功, 支持回滚
- 为防止并发环境的不一致问题, 需要对整个写操作加分布式锁处理, 保证对数据库和缓存的操作仅能由同一个线程完成。
5. Write-Behind 异步回写模式
Write behind意为异步回写模式, 它也具有类似Read-Through/Write-Through的访问控制层, 不同的是, Write behind在处理写请求时, 只更新缓存而不更新数据库, 对于数据库的更新, 则是通过批量异步更新的方式进行的, 批量写入的时间点可以选在数据库负载较低的时间进行。
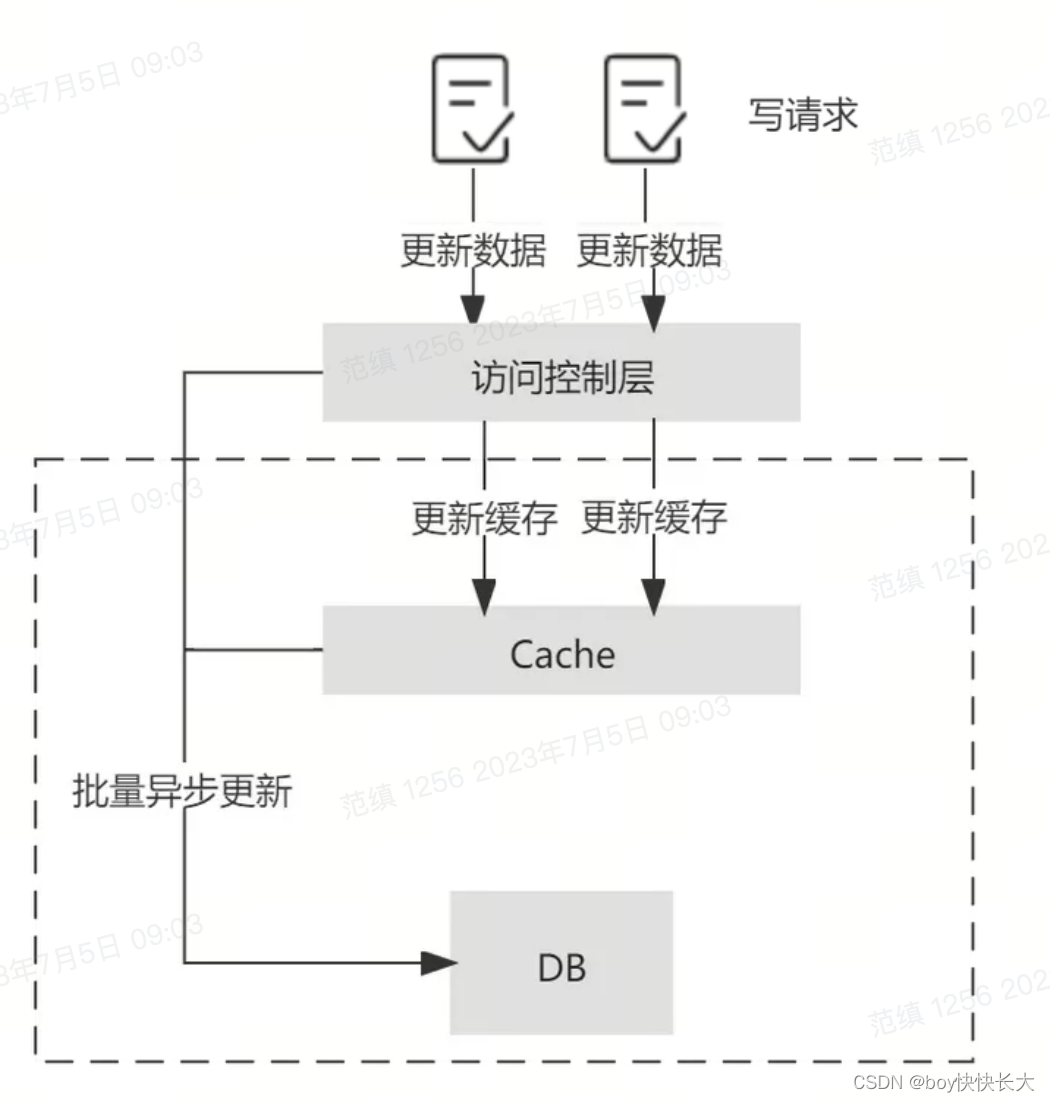
在Write-Behind模式下, 写请求延迟较低, 减轻了数据库的压力, 具有较好的吞吐性。
但数据库和缓存的一致性较弱, 比如当更新的数据还未被写入数据库时, 直接从数据库中查询数据是落后于缓存的。同时, 缓存的负载较大, 如果缓存宕机会导致数据丢失, 所以需要做好缓存的高可用。
显然, Write behind模式下适合大量写操作的场景, 常用于电商秒杀场景中库存的扣减。
6. Write-Around 乱写模式
如果一些非核心业务, 对一致性的要求较弱, 可以选择在Cache-Aside读模式下增加一个缓存过期时间, 在写请求中仅仅更新数据库, 不做任何删除或更新缓存的操作, 这样, 缓存仅能通过过期时间失效。这种方案实现简单, 但缓存中的数据和数据库数据一致性较差, 往往会造成用户的体验较差, 应慎重选择。