1. 索引基础
索引:存储引擎用于快速找到记录的数据结构
1.1 索引类型
1.1.1 B+ Tree
B+ 树: 多路搜索树

B+树能加快访问数据速度, 不需要访问全表来查询数据,而是从根节点中进行搜索, 根节点中保存了子节点的指针(并且包含子节点的上限与下限),选择正确的子节点进行查找,既可以找到对应值。
可以使用B-Tree 查询类型:
使用如下表说明查询类型
Create Table People{ f_name varchar(50) not null, l_name varchar(50) not null, birth date not null, gender enum('m','f') not null, key(f_name, l_name, birth) }
- 全值匹配: 和索引中所有列匹配(所有列有 f_name, l_name, birth), 如: 查找 f_name 为‘Allen’ l_name 为 ‘Cuba’ 生日是 '1990-01-01'的
- 匹配最左前缀: 匹配所有的前几列(一定要从左到右, 依次选,不能跳跃), 如 查找 f_name 为‘Allen’ l_name 为 ‘Cuba’ 的
- 匹配列前缀:匹配某一列值的开头, 如 查找f_name 为 ‘Allen’ 并且 l_name 中第一个字为 ‘C’ 的人
- 匹配范围值:用于查找 f_name 在 'Allen' 和 'Barrymore' 之间的
索引的限制:
- 如果不是从索引的最左列开始(第一列)则无法使用索引(如:无法查找生日为某一天的特定生日的人)
- 不能跳过索引中的列
- 如果查询中某个列有范围查询,则右边的索引都无法使用
哈希索引
哈希索引采用Hash表实现, 只有精确匹配才有效, 存储引擎为每一列添加一个索引列计算得到的索引值,并且不同的值得到的索引不一样,hash存储在索引中,也在hash表中保存指向每个数据行的指针
限制
- 索引自身只需要存储 hash值,所以不能使用索引中的值来避免读取行
- 不能排序(按照hash读取的)
- 不支持匹配查找,只支持等值查找
- 存在hash冲突
全文索引
一种特殊的索引,查找文中关键词,而不是比较索引的值,类似于搜索引擎,需要注意:停用词、词干和复数、布尔搜索等
1.2 索引优缺点
- 减少了服务器需要扫描的数据量
- 避免了排序和临时表
- 将随机I/O改变为顺序I/O
索引类别
唯一索引:加速查询 + 列值唯一(null)
主键索引: 加速查询 + 列值唯一(null)
组合索引:多列值构成索引
覆盖索引:索引包含了查询的所有列,查询时候只需要执行一次查询就可以得到结果数据
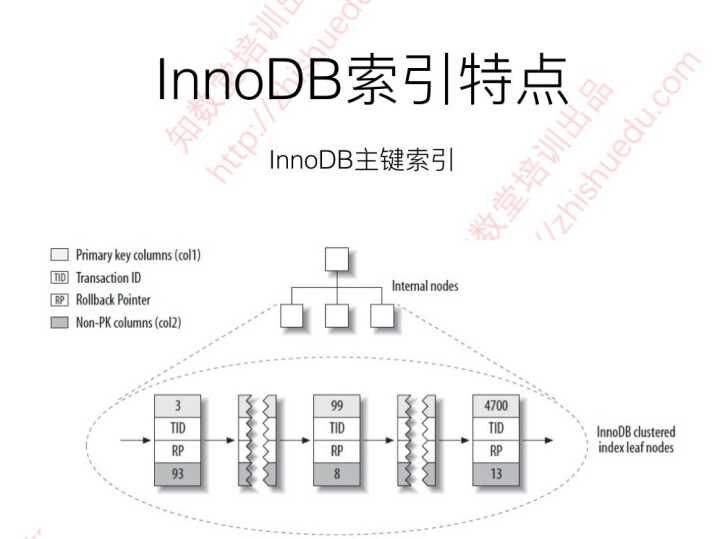
聚簇索引
叶子结点是数据而非数据指针(InnoDB)
优点:
- 把数据保存在一起
- 数据访问快
- 使用覆盖索引可以直接找到主键值
缺点:
- 插入速度依赖于插入速度
- 更新代价高
- 在表中插入新行,或者主键被更新需要移动时候,可能面临页分裂
- 全表扫描变慢(行比较稀疏,或者页分裂导致数据不连续)
- 二级索引较大,在二级索引的叶子结点包含了主键的值, 需要再一次IO

非聚簇索引
叶子结点为数据指针而非数据

InnoDB 和 myisam 对比
数据分布
InnoDB
myisam
