MySQL
1、MySQL的架构总览

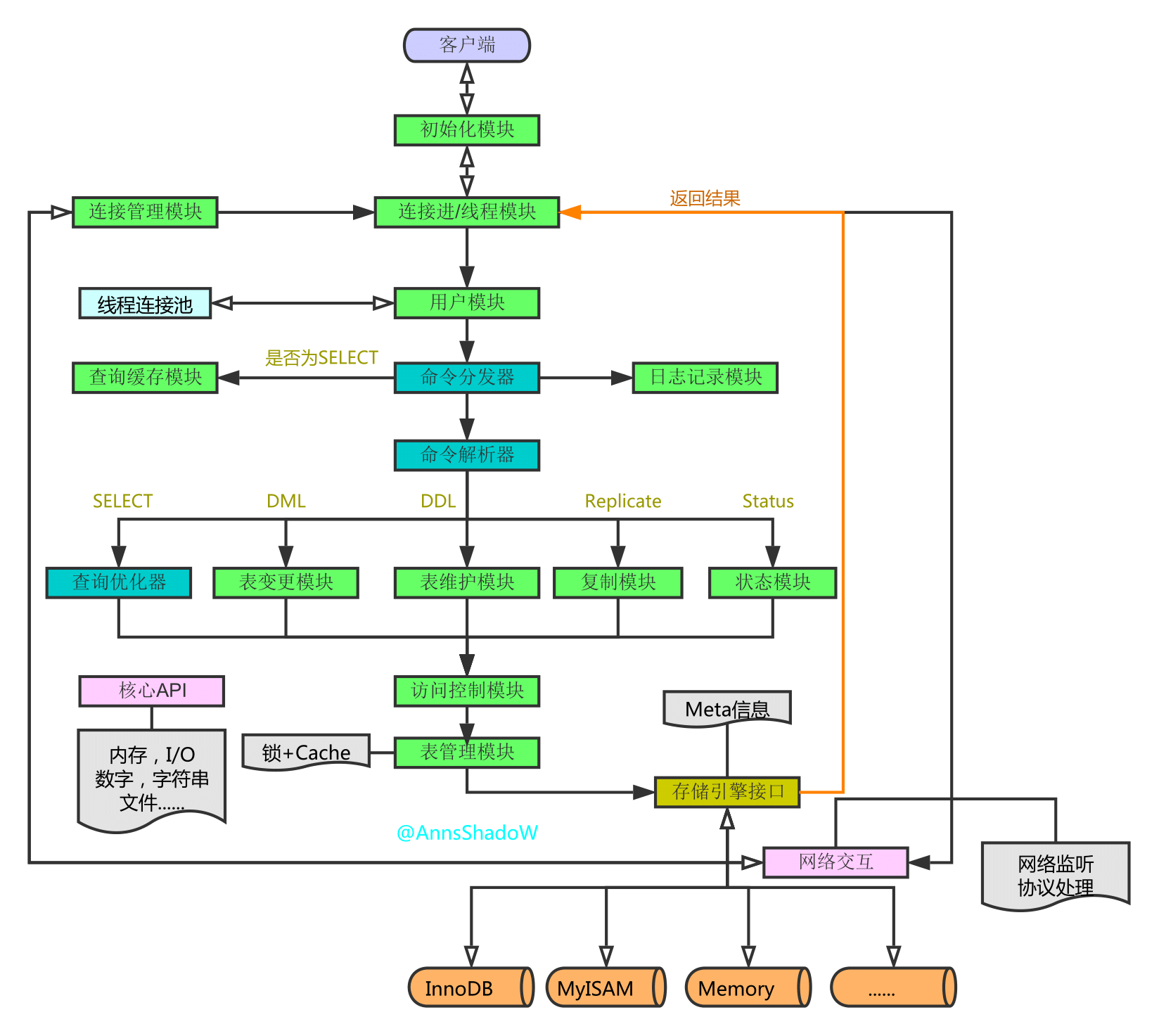
查询优化器 :MySQL会对我们的SQL语句进行优化;
存储引擎
- InnoB:支持事务、行级锁、基于XA协议的分布式事务;适用于高并发场景(5.5的默认存储引擎)
- MyISAM:不支持事务、表级锁;性能优先
查询数据库支持的存储引擎
show engines;SQL优化
- 原因:执行时间长、等待时间长、索引失效、参数设置不合理(缓冲区、线程数)
- SQL优化主要是优化索引
索引
- MySQL用来帮助高效查询的数据结构(B-Tree)
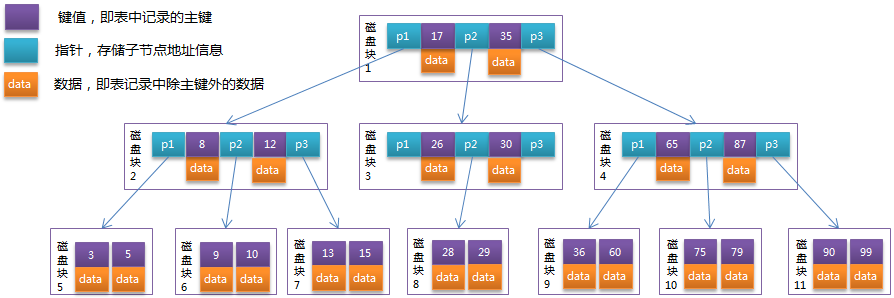
2、B-Tree和B+Tree
B-Tree (平衡多路查找树):可以显著减少定位记录时所经历的中间过程,从而加快存取速度
一个M阶的B-Tree具有的特性
> 每个节点最多有m个孩子
> 根节点的孩子数>=2(前提:树的高度大于一)
> 除了根节点和叶子结点,其他节点的孩子数(ceil(m/2));向上取整
> 所有的叶子结点都在一层
> 各个结点包含n个关键字信息:(P0,K1,P1,K2,P2......Kn,Pn)
其中
- Ki(i=1,2......n)为关键字,且K(i-1)<Ki,即从小到大排序
- 关键字的个数n必须满足:[ceil(m/2)-1,m-1]
- Pi指向子树,且指针P(i-1)所指向的子树结点中所有关键字均小于Ki。即:父结点中任何关键字的左孩子都小于它,右孩子大于它B-Tree示例图:

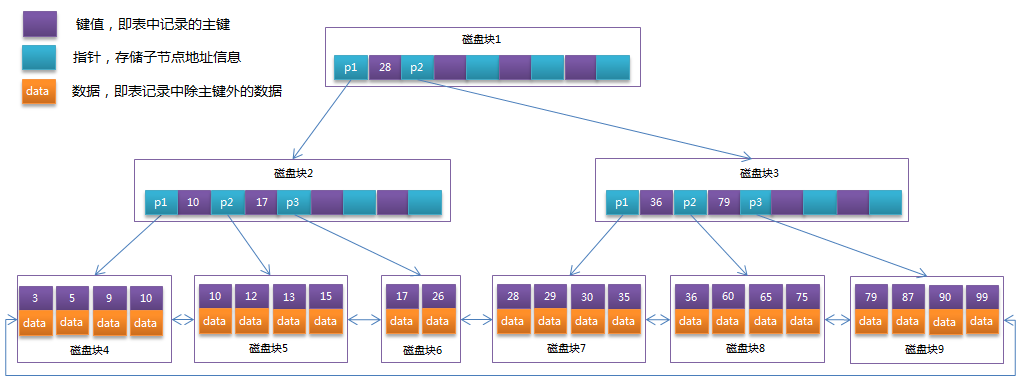
B+Tree :B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构
B+Tree相对于B-Tree有几点不同:
非叶子节点只存储键值信息;
所有叶子节点之间都有一个链指针;
数据记录都存放在叶子节点中;B+Tree示例图:

3、索引
1)单值索引
单列;一个表可以有多个单值索引
创建索引
-- 给users表的name属性创建索引
create index name_index on users(name) ;
alter table users add index name_index(name);
-- 查询索引
show index from users(表名);
-- 删除索引
drop index name_index(索引名) on users(表名);2)唯一索引
单列;一个表只有一个唯一索引;主键默认唯一索引
-- 给users表的id属性创建索引
create unique index id_index on users(id) ;
alter table users add unique index id_index(id);3)复合索引
多列;
-- 给users表的birthday,name属性创建索引
-- 先找birthday,如果birthday相同则再去name找
create index birthday_name_index on users(birthday,name) ;
alter table users add index birthday_name_index(birthday,name);4)主键索引
主键索引不能为null,单值索引可以为null;
4、SQL执行计划
1)分析SQL执行计划
使用关键字explain ,分析分析SQL执行计划
mysql> explain select * from user;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | user | ALL | NULL | NULL | NULL | NULL | 3 | |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+2)准备数据
-- 建表准备数据
CREATE TABLE course(
cid INT(2),
cname VARCHAR(10),
tid INT(2)
);
CREATE TABLE teacher(
tid INT(2),
tname VARCHAR(10),
tcid INT(2)
);
CREATE TABLE teacher_card(
tcid INT(2)teacher_card,
tcdesc VARCHAR(10)
);3)执行计划中的属性详解
-- 查询课程编号为2 或 教师证为3的老师
mysql> explain SELECT *
-> FROM teacher t,course c, teacher_card tc
-> WHERE t.tid=c.tid AND t.tcid= tc.tcid AND (c.cid=2 OR tc.tcid=3);
+----+-------------+-------+------
| id | select_type | table | ...
| 1 | SIMPLE | t | ...
| 1 | SIMPLE | tc | ...
| 1 | SIMPLE | c | ...
-- 在连接查询中,id值相同
-- t - tc - c 已知记录数顺序 3- 3- 4;==>执行顺序:记录数少的先执行;
-- 1- 查询产生的笛卡尔积
-- > 3 * 3 = 9 ;9 * 4 = 36
-- 2- 如果记录数多的先执行
-- > 4 * 3 = 12 ; 12 * 3= 36
-- 虽然最后的笛卡尔积数量不变,但是中间产生笛卡尔积数量不一样,第一种中间记录数少,占用的资源少;
-- 查询教英语的老师描述
mysql> EXPLAIN SELECT tc.tcdesc
-> FROM teacher_card tc
-> WHERE tc.tcid = (SELECT t.tcid FROM teacher t
-> WHERE t.tid = (SELECT c.tid FROM course c WHERE c.cname = '英语'));
+----+-------------+-------+------+
| id | select_type | table | ...
| 1 | PRIMARY | tc | ...
| 2 | SUBQUERY | t | ...
| 3 | SUBQUERY | c | ...
-- 在子查询中,id有 3-2-1 执行顺序 c-t-tc
-- 越内层的子查询,越先执行id : id值相同 ,从上往下顺序执行 ;id值不同,从大到小顺序执行;
select_type
- SIMPLE:简单查询(不包括连接查询,子查询)
- PRIMARY :最外层的查询
- SUNQUERY:非最外层查询
- DERIVED:衍生查询(在查询的时候用到了临时表)
- UNION RESULT:连接查询时产生的表
type
SYSTEM>CONST> EQ_REF> REF>RANGE>IANDEX> ALL(要对type优化,前提是有索引)
SYSTEM:只有一条数据的系统表、主查询的衍生表只有一条数据;(查询结果只有一条)
-- 例如,这条SQL的主查询满足条件为system类型 mysql>ALTER TABLE teacher ADD INDEX tid_index(tid); mysql> EXPLAIN SELECT * -> FROM (SELECT * FROM teacher t WHERE t.tid = 1) t_derived; +----+-------------+------------+--------+---------------+-----------+---------+------+-- | id | select_type | table | type | possible_keys | key | key_len | ref | +----+-------------+------------+--------+---------------+-----------+---------+------+--- | 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | | 2 | DERIVED | t | ref | tid_index | tid_index | 5 | | +----+-------------+------------+--------+---------------+-----------+---------+------+--CONST:在主键索引或唯一索引的情况下,只查询一条数据;(查询结果只有一条)
mysql> ALTER TABLE teacher ADD PRIMARY KEY tid_primary(tid); -- 主键索引是tid,type是const mysql> EXPLAIN SELECT * FROM teacher t WHERE t.tid = 1; +----+-------------+-------+-------+-------------------+---------+---------+-------+------ | id | select_type | table | type | possible_keys | key | key_len | ref | rows +----+-------------+-------+-------+-------------------+---------+---------+-------+------ | 1 | SIMPLE | t | const | PRIMARY,tid_index | PRIMARY | 4 | const | 1 +----+-------------+-------+-------+-------------------+---------+---------+-------+----- -- 查询tcid ,type 是 all mysql> EXPLAIN SELECT * FROM teacher t WHERE t.tcid = 1; +----+-------------+-------+------+---------------+------+---------+------+------+------- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra +----+-------------+-------+------+---------------+------+---------+------+------+------- | 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 3 | Using +----+-------------+-------+------+---------------+------+---------+------+------+-------EQ_REF:唯一性索引; 对于每个索引键的查询,必须返回有且只有一条数据; (查询结果多条)
-- 将列改为唯一性索引 mysql> ALTER TABLE teacher ADD UNIQUE INDEX tcid_index(tcid); mysql> ALTER TABLE teacher_card ADD PRIMARY KEY tcid_primary(tcid); -- 此时teacher和teacher_card的数据条数为3 -- 查询索引键,若两边数据条数一致(必须是唯一性索引) mysql> EXPLAIN SELECT t.tcid FROM teacher t,teacher_card tc WHERE t.tcid = tc.tcid; +----+-------------+-------+--------+---------------+------------+---------+------------- | id | select_type | table | type | possible_keys | key | key_len | ref +----+-------------+-------+--------+---------------+------------+---------+------------- | 1 | SIMPLE | t | index | tcid_index | tcid_index | 5 | NULL | 1 | SIMPLE | tc | eq_ref | PRIMARY | PRIMARY | 4 | mydb3.t.tcid +----+-------------+-------+--------+---------------+------------+---------+-------------REF:非唯一性索引; 对于每个索引键的查询,返回n条数据(可以n=0);(查询结果多条)
-- 给teacher添加一条数据 -- 查询索引键,若两边数据条数不一致(可以为非唯一性索引) mysql> EXPLAIN SELECT t.tcid FROM teacher t,teacher_card tc WHERE t.tcid = tc.tcid; +----+-------------+-------+--------+---------------+------------+---------+------------- | id | select_type | table | type | possible_keys | key | key_len | ref +----+-------------+-------+--------+---------------+------------+---------+------------- | 1 | SIMPLE | t | index | tcid_index | tcid_index | 5 | NULL | 1 | SIMPLE | tc | ref | PRIMARY | PRIMARY | 4 | mydb3.t.tcid +----+-------------+-------+--------+---------------+------------+---------+-------------RANGE:检索指定范围的行的索引键 (关键字in有时候会失效);(查询结果多条)
mysql> EXPLAIN SELECT t.tcid FROM teacher t WHERE t.tcid > 1; +----+-------------+-------+-------+---------------+------------+---------+------+------+- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | +----+-------------+-------+-------+---------------+------------+---------+------+------+- | 1 | SIMPLE | t | range | tcid_index | tcid_index | 5 | NULL | 3 | +----+-------------+-------+-------+---------------+------------+---------+------+------+-INDEX:查询数据的索引键;
ALL:查询所有数据;
possible_keys:预测用到的索引(实际可能发生索引失效)
key:实际用到的索引
key_len :索引的计算长度
# char和varchar类型key_len计算公式 varchr(N)变长字段且允许NULL =\ N * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段) varchr(N)变长字段且不允许NULL = \ N * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段) char(N)固定字段且允许NULL = N * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL) char(N)固定字段且允许NULL = N * ( character set:utf8=3,gbk=2,latin1=1) # 与数据类型长度无关 # 数值数据的key_len计算公式: TINYINT允许NULL = 1 + 1(NULL) TINYINT不允许NULL = 1 SMALLINT允许为NULL = 2+1(NULL) SMALLINT不允许为NULL = 2 INT允许为NULL = 4+1(NULL) INT不允许为NULL = 4 # 日期时间型的key_len计算:(针对mysql5.5) DATETIME允许为NULL = 8 + 1(NULL) DATETIME不允许为NULL = 8 TIMESTAMP允许为NULL = 4 + 1(NULL) TIMESTAMP不允许为NULL = 4ref:指明当前表参照的字段(null,const常量,参照的字段)
-- tc 表参照了mydb3.t.tcid 字段 mysql> EXPLAIN SELECT t.tcid FROM teacher t,teacher_card tc WHERE t.tcid = tc.tcid; +----+-------------+-------+--------+---------------+------------+---------+------------- | id | select_type | table | type | possible_keys | key | key_len | ref +----+-------------+-------+--------+---------------+------------+---------+------------- | 1 | SIMPLE | t | index | tcid_index | tcid_index | 5 | NULL | 1 | SIMPLE | tc | ref | PRIMARY | PRIMARY | 4 | mydb3.t.tcid +----+-------------+-------+--------+---------------+------------+---------+-------------rows:实际查询的记录数
mysql> EXPLAIN SELECT t.tcid FROM teacher_card tc,teacher t WHERE t.tcid = tc.tcid; +----+-------------+-------+--------+---------------+------------+---------+------------- | id | select_type | table | type | possible_keys | key | key_len | ref +----+-------------+-------+--------+---------------+------------+---------+------------- | 1 | SIMPLE | t | index | tcid_index | tcid_index | 5 | NULL | 1 | SIMPLE | tc | ref | PRIMARY | PRIMARY | 4 | mydb3.t.tcid +----+-------------+-------+--------+---------------+------------+---------+------------- +------+--------------------------+ | rows | Extra | +------+--------------------------+ | 3 | Using index | | 1 | Using where; Using index | +------+--------------------------+ mysql> SELECT t.tcid FROM teacher_card tc,teacher t WHERE t.tcid = tc.tcid; +------+ | tcid | +------+ | 1 | | 2 | | 3 | +------+extra
- Using index,使用到索引
- Using where,表示优化器需要通过索引回表查询数据;
Using filesort:无法利用索引来完成的排序
-- 单列索引 CREATE TABLE a( a INT, b INT, c INT, INDEX a_index(a), INDEX b_index(b), INDEX c_index(c) ); -- 查询的 a 但是额外用b排了序,如果用a排序则不会出现Using filesort mysql> EXPLAIN SELECT * FROM a WHERE a='' ORDER BY b; +------+--------------------------+ | rows | Extra | +------+--------------------------+ | 1 | Using where; Using filesort | +------+--------------------------+ -- 复合索引 不能跨列 要满足最佳左前缀,否则出现Using filesort DROP INDEX a_index ON a; DROP INDEX b_index ON a; DROP INDEX c_index ON a; ALTER TABLE a ADD INDEX a_b_c_index(a,b,c); -- 满足最佳左前缀,没有跨列 mysql> EXPLAIN SELECT * FROM a WHERE a='' ORDER BY b; +------+--------------------------+ | rows | Extra | +------+--------------------------+ | 1 | Using where; Using index | +------+--------------------------+ -- 跨列 mysql> EXPLAIN SELECT * FROM a WHERE a='' ORDER BY c; +------+--------------------------+ | rows | Extra | +------+--------------------------+ | 1 | Using where; Using index; Using filesort | +------+--------------------------+ -- 不满足最佳左前缀 mysql>EXPLAIN SELECT * FROM a WHERE b='' ORDER BY c; +------+--------------------------+ | rows | Extra | +------+--------------------------+ | 1 | Using where; Using index; Using filesort | +------+--------------------------+(补充: 回表查询:指的是在索引中没有要查询的数据,需要回到表中查询)
5、优化示例
1)单表优化
-- 单表优化
-- 创建表
CREATE TABLE book(
bid INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
authorid INT NOT NULL,
publicid INT NOT NULL,
typeid INT NOT NULL
);
-- 查询authorID=1,typeid=2或3的 bid
mysql> EXPLAIN SELECT bid FROM book WHERE typeid IN (2,3) AND authorid = 1 ORDER BY typeid DESC;
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| 1 | SIMPLE | book | ALL | NULL | NULL | NULL | NULL | 5 |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------+
Extra
------------------+
Using where; Using filesort
------------------+
-- 优化 1 添加索引,(消除了Using filesort,提高了type等级index)
ALTER TABLE book ADD INDEX b_t_a_index(bid,typeid,authorid);
mysql> EXPLAIN SELECT bid FROM book WHERE typeid IN (2,3) AND authorid = 1 ORDER BY typeid DESC;
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| 1 | SIMPLE | book | index | NULL | NULL | 12 | NULL | 5 |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
------------------+
Extra
------------------+
Using where; Using index;Using filesort
------------------+
-- 优化2
-- 修改索引顺序(提高了type等级 ref)
-- 含IN 的查询放到后面,避免可能的失效
ALTER TABLE book ADD INDEX atb_index(authorid,typeid,bid);
mysql> EXPLAIN SELECT bid FROM book WHERE authorid = 1 AND typeid IN (2,3) ORDER BY typeid DESC;
+----+-------------+-------+------+---------------+-----------+---------+-------+------+-----
| id | select_type | table | type | possible_keys | key | key_len | ref | rows |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+-----
| 1 | SIMPLE | book | ref | atb_index | atb_index | 4 | const | 2 |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
Extra |
---------------------+
Using where; Using index |
---------------------+2)多表优化
EXPLAIN SELECT * FROM teacher t , course c WHERE t.tid = c.tid AND c.cname = '语文';
-- 或者
EXPLAIN SELECT * FROM teacher t LEFT JOIN course c ON t.tid = c.tid WHERE c.cname = '语文';
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| id | select_type | table | type | possible_keys | key | key_len | ref | rows |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------
| 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 3 |
| 1 | SIMPLE | c | ALL | NULL | NULL | NULL | NULL | 4 |
+----+-------------+-------+------+---------------+------+---------+------+------+--------------------------------+
Extra
--------------------+
Using where; Using join buffer |
--------------------+
-- 优化 1 添加索引
-- 给哪张表添加索引 --> 满足原则"小表驱动大表";
-- --> 索引经常使用,不常改变3)避免索引失效原则
- 复合索引需要满足最佳左前缀;
- 复合索引尽量使用全索引匹配;
- 复合索引不能使用(不等于、和 IS NULL);
- 索引上不要进行一些运算操作;
- 范围查询是不使用关键字IN;
- 模糊查询尽量以"常量"开头不以"%"开头;
- 不要使用OR;
- 不要使用字段的类型转换;
4)常见的优化方法
IN和EXIST的使用:
- 如果主查询的数据很大,用IN
- 如果子查询的数据很大,用EXIST
order by 的使用
Using filesort 分为双路排序[1扫描排序字段,2扫描其它字段]、单路排序[扫描全度字段](根据磁盘IO次数)
可以通过切换排序方法和增大排序使用的
buffer大小保证排序的一致性
避免使用
SELECT *
5) 慢查询日志
记录mysql中超过阀值(long query time)默认10秒;
-- 查看慢查询日志是否开启
show variables like "%slow_query_log%";
-- 临时开启
set globle slow_query_log = 1;
-- 永久开启
-- 修改mysql的配置文件
-- slow_query_log = 1
-- slow_query_log_file = /var/mysql/slow.log 制定一个路径寻访日志
-- 查看阀值大小
show variables like "%long_query_time%";
-- 临时设置大小(重启生效)
set globle long_query_time = 时长(s);
-- 永久设置大小(重启生效)
-- 修改mysql的配置文件
-- long_query_time = 时长
-- 查询超过阀值的SQL
show globle status like "%slow_queris%"; -- 数量
-- mysql的工具,查看慢日志记录
mysqldumpslow6、分析数据
1)使用profiles
分析执行SQL的在各环节的执行时间
-- 查看执行SQL的时间和query_id
show profiles
--
show variables like "%profiling%";
-- 开启profiling属性
set profiling = on;
-- 分析执行SQL的在各环节的执行时间
show profile all for query 1; -- 1是查出来的query_id
2)使用全局日志
可以记录所有执行的SQL
-- 查看是否开启全局日志
show variables like "%general_log%";
-- 开启全局日志,记录到mysql.general_log表中
set globle general_log = 1;
set globle log_output = 'table';7、锁机制
解决资源共享造成的并发问题 参考[mydddfly]博客;
- 读锁(共享锁):读操作,一个资源可以被多个访问读取;
- 写锁(互斥锁):写操作,一个资源在进行写操作时,独占;
1)MySQL的锁机制
| 开销 | 加锁速度 | 死锁 | 粒度 | 并发性能 | |
|---|---|---|---|---|---|
| 行级锁 | 小 | 快 | 不会死锁 | 大(锁冲突概率高) | 低 |
| 表级锁 | 大 | 慢 | 会出现死锁 | 小(锁冲突概率低) | 高 |
| 页面锁 | 中 | 中 | 会出现死锁 | 中 | 中 |
2)存储引擎使用的锁
- INNODB:默认使用行级锁,也支持表级锁
- MyISAM:默认使用表级锁
- MEMORY:默认使用表级锁
3)表锁
MySQL的表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁;
-- 通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺情况;
-- 值越大争夺越严重
mysql> show status like 'table%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Table_locks_immediate | 46 |
| Table_locks_waited | 0 |
+-----------------------+-------+如何给表加锁
-- lock table 表名 read/write 给表加上读/写锁
mysql> lock table teacher read;
-- 查看表是否使用锁
mysql> show open tables;
+--------------------+----------------------------------------------+--------+-------------+
| Database | Table | In_use | Name_locked |
+--------------------+----------------------------------------------+--------+-------------+
| mysql | time_zone_transition_type | 0 | 0 |
| mydb3 | teacher | 1 | 0 |
+--------------------+----------------------------------------------+--------+-------------+4)行锁
- InnoDB实现了以下两种类型的行锁。
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁
(为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁)
- 如何给行加锁
-- 可以通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况:
show status like 'innodb_row_lock%';
Show innodb status;
-- 共享锁
select * from teacher where tid = 1 lock in share mode;
-- 排它锁
select * from teacher where tid = 1 for update;8、主从复制
1)mysql 的主从复制原理

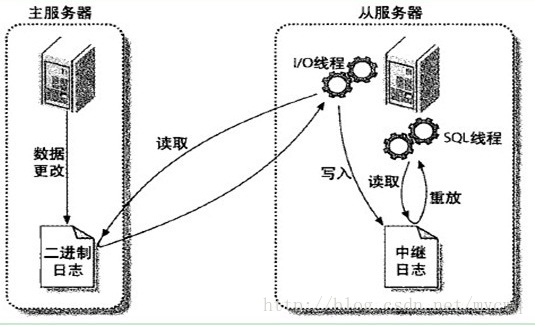
MySQL之间数据复制的基础是二进制日志文件(binary log file)。一台MySQL数据库一旦启用二进制日志后,其作为master,它的数据库中所有操作都会以“事件”的方式记录在二进制日志中,其他数据库作为slave通过一个I/O线程与主服务器保持通信,并监控master的二进制日志文件的变化,如果发现master二进制日志文件发生变化,则会把变化复制到自己的中继日志中,然后slave的一个SQL线程会把相关的“事件”执行到自己的数据库中,以此实现从数据库和主数据库的一致性,也就实现了主从复制;
2)实现主从复制
主服务器配置
-- 修改配置文件
[mysqld]
log-bin = mysql-bin
server-id = 1
-- 创建用户并授权
mysql> CREATE USER 'flynn'@'localhost' IDENTIFIED BY '123456';#创建用户
mysql> GRANT REPLICATION SLAVE ON *.* TO 'flynn'@'localhost';#分配权限
mysql>flush privileges; #刷新权限
-- 查看master状态,记录二进制文件名和位置:
show master status;从服务器配置、
-- 配置文件
server-id = 2
-- 重启mysql,打开mysql会话,执行同步SQL语句
mysql> CHANGE MASTER TO
-> MASTER_HOST='',
-> MASTER_USER='',
-> MASTER_PASSWORD='',
-> MASTER_LOG_FILE='二进制文件名',
-> MASTER_LOG_POS='位置';
-- 启动slave 同步
mysql> start slave;
-- 查看状态
mysql> show slave status对主服务器配置约束
[mysqld]
# 不同步哪些数据库
binlog-ignore-db = ''
# 只同步哪些数据库,除此之外,其他不同步
binlog-do-db = '' 9、思考
1)为什么索引是默认是B-Tree,而不是hash、二叉树、红黑树
- hash:可以快速定位但是没有顺序IO复杂度高;
- 二叉树:树的高度不均匀,不能自平衡,存储的数据越大则树的高度越高,IO代价越高;
- 红黑树:存储的数据越大则树的高度越高,IO代价越高;
2)为什么建议使用自增长的主键作为索引
自增的主键是连续的在插入过程中尽量减少页分裂,即使进行页分裂,也只会分裂很少的一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率