如何理解hash(又名哈希,或者散列)
实现hash的数据结构示意图
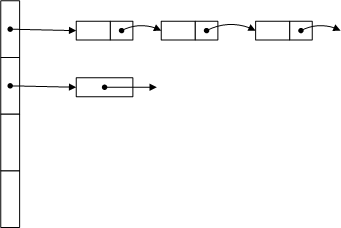
由图可知,哈希表其实就是一个一维数组,而数组中的每一个元素都是一个单向链表而已。这样的数据结构解决了数组的增删元素的不足和链表的查询效率的不足。
哈希原理
通过哈希算法(md4 md5 sha1 …)将任意长度的数据映射成固定长度,较少位数的二进制数据。以映射后的二进制数据为依据进行存储,构造成哈希表。在后续查找时,也是根据原来的二进制数据,和哈希算法,计算出一个二进制数据,然后在哈希表中找到计算得到那个二进制数据。找到之后,在按照依据的哈希算法进行反操作,即可得到原始的二进制数据。
哈希过程
整个散列过程其实就是两步。(1) 在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该记录。(2) 当查找记录时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。由于存取用的是同一个散列函数, 因此结果当然也是相同的。
所以说,散列技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向查找的存储结构。
哈希优点
1,节约空间。哈希之后的二进制数据位数更少,节约空间;
2,查找快速。根据得到的二进制数据进行查找的过程,类似于根据数组下标来查找,时间复杂度是o(1);但实际上,哈希算法的时间复杂度往往会大于o(1),因为哈希之后的二进制数据可能对应于多个原始的二进制数据,这种情况叫做哈希冲突;
解决哈希冲突的方法
1,线性探测:将哈希值相同的数据,以链表的形式存储,即先通过哈希值锁定范围,然后再依次解析出原始数据,进行查找;
2,连地址法:即在分配哈希表时,多分配一些空间,对于哈希冲突的情况,在哈希表中依次记录。
如何设置需要分配的哈希表的大小:
在使用哈希的时候,要考虑你存的数据个数的大小,然后再确定数组的大小,一般数组的大小是数据个数的两倍(好像)。
哈希应用
(1) 文件校验
我们比较熟悉的校验算法有奇偶校验和CRC校验,这2种校验并没有抗数据篡改的能力,它们一定程度上能检测并纠正数据传输中的信道误码,但却不能防止对数据的恶意破坏。
MD5 Hash算法的“数字指纹”特性,使它成为目前应用最广泛的一种文件完整性校验和(Checksum)算法,不少Unix系统有提供计算md5 checksum的命令。
(2) 数字签名
Hash 算法也是现代密码体系中的一个重要组成部分。由于非对称算法的运算速度较慢,所以在数字签名协议中,单向散列函数扮演了一个重要的角色。 对 Hash 值,又称“数字摘要”进行数字签名,在统计上可以认为与对文件本身进行数字签名是等效的。而且这样的协议还有其他的优点。
(3) 鉴权协议
如下的鉴权协议又被称作挑战–认证模式:在传输信道是可被侦听,但不可被篡改的情况下,这是一种简单而安全的方法。