说明
散列的概念属于查找,它不以关键字的比较为基本操作,采用直接寻址技术。在理想情况下,查找的期望时间为O(1)。
简单的说,hash函数就是把任意长的输入字符串变化成固定长的输出字符串的一种函数。输出字符串的长度称为hash函数的位数。(下图来源于维基百科)
散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来,比如我们自定义密码的存储。
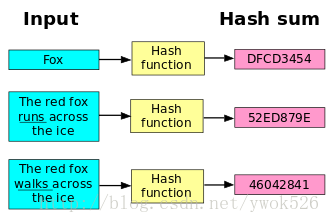
一句话:散列(Hashing)通过散列函数将要检索的项与索引(散列,散列值)关联起来,生成一种便于搜索的数据结构(散列表)。
应用
目前应用最为广泛的hash函数是SHA-1和MD5,大多是128位和更长。hash函数在现实生活中应用十分广泛。很多下载网站都提供下载文件的MD5码校验,可以用来判别文件是否完整,在一些BitTorrent下载中,软件将通过计算MD5检验下载到的文件片段的完整性,etc.

解释
散列函数的性质:
同一函数的散列值不相同,那么其原始输入也不相同,上图中k1,k3和k4。(确定性)
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是不相同的,上图中的k2,k5这种情况称为“哈希碰撞”。(不确定性)
所以,安全避免冲突的条件,一是|U|的上限为m,(实际上很难满足);二是选择合适的Hash函数。
Q:冲突是不是可以避免的?
否。根据鸽巢原理可得,哈希表的重复问题(冲突)是不可避免的,因为键的数目总是比索引的数目多,不管是多么高明的算法都不可能解决这个问题。就算键的数目比索引的数目少,必有一个输出串对应多个输入串,冲突还是会发生。
hash函数的构造准则:简单、均匀
1、 散列函数的计算简单,快速;
2、 散列函数能将关键字集合K均匀地分布在地址集{0,1,…,m-1}上,使冲突最小。
hash函数的构造方法:
1、直接定址法:
取关键字或关键字的某个线性函数值为哈希地址:H(key)=key 或 H(key)=a·key+b
其中a和b为常数,这种哈希函数叫做自身函数。
例:有一个从1岁到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。这样,若要询问25岁的人有多少,则只要查表的第25项即可。
由于直接定址所得地址集合和关键字集合的大小相同。因此,对于不同的关键字不会发生冲突。但实际中能使用这种哈希函数的情况很少。
2、 相乘取整法
该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:

该方法最大的优点是m的选取比除余法要求更低。比如,完全可选择它是2的整数次幂。虽然该方法对任何A的值都适用,但对某些值效果会更好。Knuth建议选取

3、平方取中法
取关键字平方后的中间几位为哈希地址。
通过平方扩大差别,另外中间几位与乘数的每一位相关,由此产生的散列地址较为均匀。这是一种较常用的构造哈希函数的方法。
例:将一组关键字(0100,0110,1010,1001,0111)
平方后得(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。
4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法(folding)。
如国际标准图书编号0-442-20586-4的哈希地址分别如

5、除余法:
取关键字被数p除后所得余数为哈希地址:H(key)=keyMOD p (p≤m)
这是一种最简单,也最常用的构造哈希函数的方法。它不仅可以对关键字直接取模(MOD),也可在折迭、平方取中等运算之后取模。值得注意的是,在使用除留余数法时,对p的选择很重要。一般情况下可以选p为质数或不包含小于20的质因素的合数。
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random (key),其中random为随机函数。通常,当关键字长度不等时采用此法构造哈希函数较恰当。
处理冲突的方法:
1、开放定址法(不好理解啊)
基本思想:前者是将所有结点均存放在散列表[0..m-1]中。
当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址 (即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的地址则表明表中无待查的关键字,即查找失败。
注意:用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
怎么用:
装填因子:a,a一般取0.5到0.9之间。目的是为了确定合适的表长。
探查序列:
Hi=(H(key)+di)MOD m i=1,2,…,k (k≤m-1) ,其中:H(key)为哈希函数;m为哈希表表长;di为增量序列,可有下列三种取法:
(1) di=1,2,3,…,m-1,称线性探测再散列;
(2) di=12,-12,22,-22,33,…,±k2,(k≤m/2)称二次探测再散列;
(3) di=伪随机数序列,称伪随机探测再散列。
例:利用探测法构造散列表:
已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
这里关键字个数n=10,不妨取m=13,此时α≈0.77,散列表为T[0..12],散列函数为:h(key)=key%13。
由除余法的散列函数计算出的上述关键字序列的散列地址为
(0,10,2,12,5,2,3,12,6,12)。
步骤:
1、前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。
2、当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。
3、当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。
4、类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
参见动画演示
2、链地址法
基本思想:将互为同义词的结点链成一个单链表,而将此链表的头指针放在散列表[0..m-1]中。
例:已知一组关键字为(19,14,23,01,68,20,84,27,55,11,10,79),则按哈希函数H(key)=key MOD13和链地址法处理冲突构造所得的哈希表为:
