搜索
DFS、BFS、A*启发式
31 | 深度和广度优先搜索:如何找出社交网络中的三度好友关系?
BFS
广度优先搜索,通俗的理解就是,地毯式层层推进,从起始顶点开始,依次往外遍历。广度优先搜索需要借助队列来实现,遍历得到的路径就是,起始顶点到终止顶点的最短路径。
时间复杂度是 O(E),空间复杂度是 O(V)。
例子:水滴波纹
def bfs(graph, start, end):
queue = []
queue.append([start])
visited = set() # 树可省,图不可
visited.add(start)
while queue:
node = queue.pop()
visited.add(node)
process(node)
nodes = generate_related_nodes(node)
queue.push(nodes)
# other processing work
DFS
深度优先搜索用的是回溯思想,非常适合用递归实现。换种说法,深度优先搜索是借助栈来实现的。
时间复杂度是 O(E),空间复杂度是 O(V)。
例子就是“走迷宫”
- 递归(推荐)
def dfs(node):
# 递归写法
visited = set()
visited.add(node)
# process current node here
for next_node in node.children():
if not not next_node in visited:
dfs(next_node)
- 栈
def dfs_stack(self, tree):
if tree.root is None:
return []
visited = set()
stack = [tree.node]
while stack:
node = stack.pop()
visited.add(node)
process(node)
nodes = generate_related_nodes(node)
stack.push(nodes)
# other processing work
如何找出社交网络中的三度好友关系?
这个问题就非常适合用图的广度优先搜索算法来解决因为广度优先搜索是层层往外推进的。首先,遍历与起始顶点最近的一层顶点,也就是用户的一度好友,然后再遍历与用户距离的边数为 2 的顶点,也就是二度好友关系,以及与用户距离的边数为 3 的顶点,也就是三度好友关系。

我们只需要稍加改造一下广度优先搜索代码,用一个数组来记录每个顶点与起始顶点的距离,非常容易就可以找出三度好友关系。
我们通过广度优先搜索算法解决了开篇的问题,你可以思考一下,能否用深度优先搜索来解决呢?
深度优先用于寻找3度好友,可以设定搜索的深度,到3就向上回溯。
学习数据结构最难的不是理解和掌握原理,而是能灵活地将各种场景和问题抽象成对应的数据结构和算法。今天的内容中提到,迷宫可以抽象成图,走迷宫可以抽象成搜索算法,你能具体讲讲,如何将迷宫抽象成一个图吗?或者换个说法,如何在计算机中存储一个迷宫?
类似于欧拉七桥问题,需要将迷宫抽象成图,每个分叉路口作为顶点,顶点之间连成边,构成一张无向图,可以存储在邻接矩阵或邻接表中。
49 | 搜索:如何用A*搜索算法实现游戏中的寻路功能?
Dijkstra 算法 & A* 算法
实际上,像出行路线规划、游戏寻路,这些真实软件开发中的问题,一般情况下,我们都不需要非得求最优解(也就是最短路径)。在权衡路线规划质量和执行效率的情况下,我们只需要寻求一个次优解就足够了。那如何快速找出一条接近于最短路线的次优路线呢?
这个快速的路径规划算法,就是我们今天要学习的A* 算法。实际上,A* 算法是对 Dijkstra 算法的优化和改造。
当我们遍历到某个顶点的时候,从起点走到这个顶点的路径长度是确定的,我们记作 g(i)(i 表示顶点编号)。但是,从这个顶点到终点的路径长度,我们是未知的。虽然确切的值无法提前知道,但是我们可以用其他估计值来代替。
这里我们可以通过这个顶点跟终点之间的直线距离,也就是欧几里得距离,来近似地估计这个顶点跟终点的路径长度(注意:路径长度跟直线距离是两个概念)。我们把这个距离记作 h(i)(i 表示这个顶点的编号),专业的叫法是启发函数(heuristic function)。因为欧几里得距离的计算公式,会涉及比较耗时的开根号计算,所以,我们一般通过另外一个更加简单的距离计算公式,那就是曼哈顿距离(Manhattan distance)。曼哈顿距离是两点之间横纵坐标的距离之和。计算的过程只涉及加减法、符号位反转,所以比欧几里得距离更加高效。
原来只是单纯地通过顶点与起点之间的路径长度 g(i),来判断谁先出队列,现在有了顶点到终点的路径长度估计值,我们通过两者之和 f(i)=g(i)+h(i),来判断哪个顶点该最先出队列。综合两部分,我们就能有效避免刚刚讲的“跑偏”。这里 f(i) 的专业叫法是估价函数(evaluation function)。
A* 算法就是对 Dijkstra 算法的简单改造。A* 算法的代码实现的主要逻辑是下面这段代码。它跟 Dijkstra 算法的代码实现,主要有 3 点区别:
- 优先级队列构建的方式不同。A* 算法是根据 f 值(也就是刚刚讲到的 f(i)=g(i)+h(i))来构建优先级队列,而 Dijkstra 算法是根据 dist 值(也就是刚刚讲到的 g(i))来构建优先级队列;
- A* 算法在更新顶点 dist 值的时候,会同步更新 f 值;
- 循环结束的条件也不一样。Dijkstra 算法是在终点出队列的时候才结束,A* 算法是一旦遍历到终点就结束。
尽管 A* 算法可以更加快速的找到从起点到终点的路线,但是它并不能像 Dijkstra 算法那样,找到最短路线。这是为什么呢?
要找出起点 s 到终点 t 的最短路径,最简单的方法是,通过回溯穷举所有从 s 到达 t 的不同路径,然后对比找出最短的那个。不过很显然,回溯算法的执行效率非常低,是指数级的。
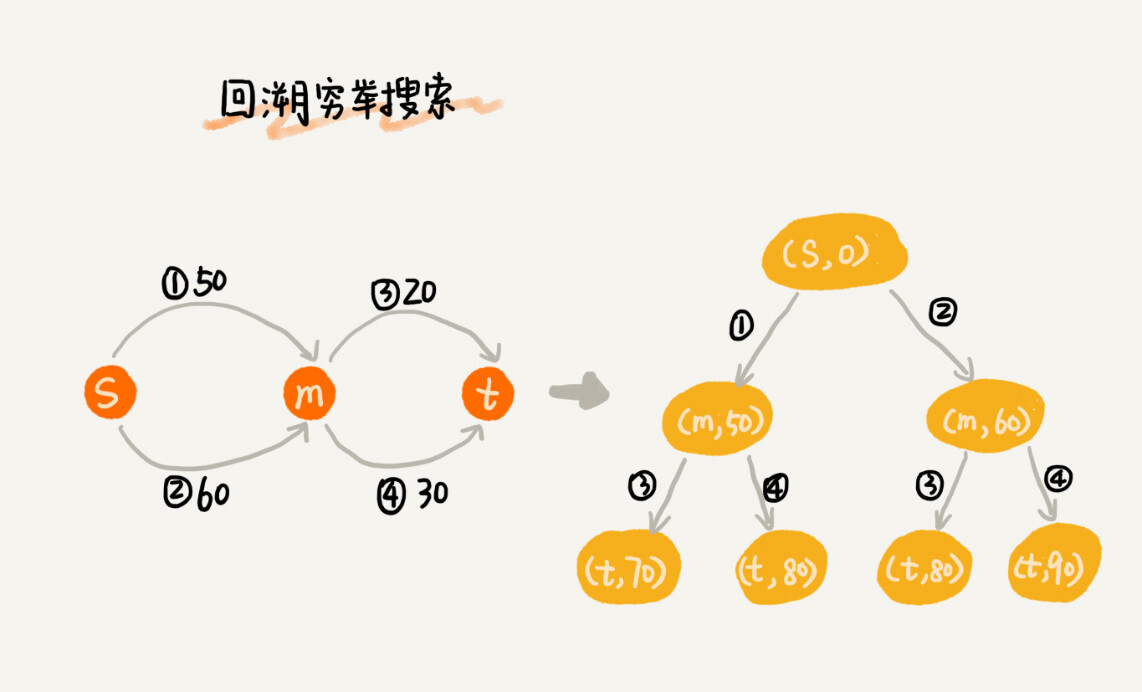
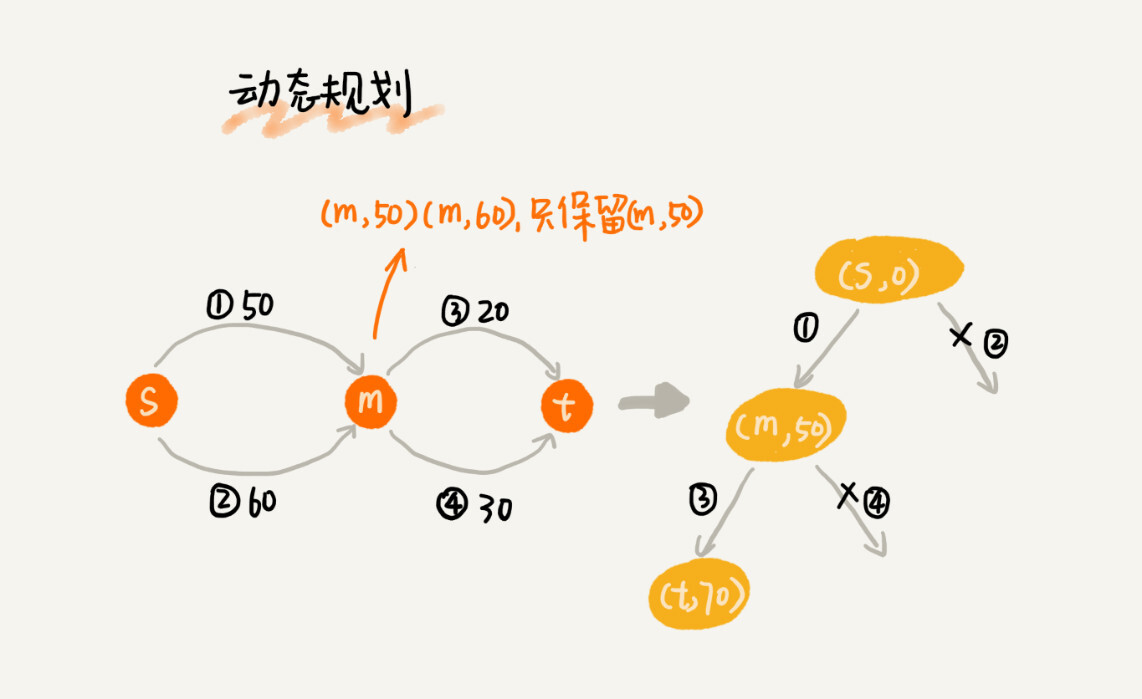
Dijkstra 算法在此基础之上,利用动态规划的思想,对回溯搜索进行了剪枝,只保留起点到某个顶点的最短路径,继续往外扩展搜索。动态规划相较于回溯搜索,只是换了一个实现思路,但它实际上也考察到了所有从起点到终点的路线,所以才能得到最优解。
A* 算法之所以不能像 Dijkstra 算法那样,找到最短路径,主要原因是两者的 while 循环结束条件不一样。刚刚我们讲过,Dijkstra 算法是在终点出队列的时候才结束,A 算法是一旦遍历到终点就结束*。对于 Dijkstra 算法来说,当终点出队列的时候,终点的 dist 值是优先级队列中所有顶点的最小值,即便再运行下去,终点的 dist 值也不会再被更新了。对于 A* 算法来说,一旦遍历到终点,我们就结束 while 循环,这个时候,终点的 dist 值未必是最小值。
A* 算法利用贪心算法的思路,每次都找 f 值最小的顶点出队列,一旦搜索到终点就不在继续考察其他顶点和路线了。所以,它并没有考察所有的路线,也就不可能找出最短路径了。
如何借助 A* 算法解决今天的游戏寻路问题?
要利用 A* 算法解决这个问题,我们只需要把地图,抽象成图就可以了。不过,游戏中的地图跟我们平常用的地图是不一样的。因为游戏中的地图并不像我们现实生活中那样,存在规划非常清晰的道路,更多的是宽阔的荒野、草坪等。所以,我们没法把岔路口抽象成顶点,把道路抽象成边。
实际上,我们可以换一种抽象的思路,把整个地图分割成一个一个的小方块。在某一个方块上的人物,只能往上下左右四个方向的方块上移动。我们可以把每个方块看作一个顶点。两个方块相邻,我们就在它们之间,连两条有向边,并且边的权值都是 1。所以,这个问题就转化成了,在一个有向有权图中,找某个顶点到另一个顶点的路径问题。将地图抽象成边权值为 1 的有向图之后,我们就可以套用 A* 算法,来实现游戏中人物的自动寻路功能了。
总结引申
我们今天讲的 A* 算法属于一种启发式搜索算法(Heuristically Search Algorithm)。实际上,启发式搜索算法并不仅仅只有 A* 算法,还有很多其他算法,比如 IDA* 算法、蚁群算法、遗传算法、模拟退火算法等。如果感兴趣,你可以自行研究下。
启发式搜索算法利用估价函数,避免“跑偏”,贪心地朝着最有可能到达终点的方向前进。这种算法找出的路线,并不是最短路线。但是,实际的软件开发中的路线规划问题,我们往往并不需要非得找最短路线。所以,鉴于启发式搜索算法能很好地平衡路线质量和执行效率,它在实际的软件开发中的应用更加广泛。实际上,地图 App 中的出行路线规划问题,也可以利用启发式搜索算法来实现。
思考
我们之前讲的“迷宫问题”是否可以借助 A* 算法来更快速地找到一个走出去的路线呢?如果可以,请具体讲讲该怎么来做;如果不可以,请说说原因。