好像面试很多面试官都喜欢问这它们的一些问题,所以在这里我稍微总结一下,并把大佬们的文章链接贴在后面。
首先我们借鉴了https://www.cnblogs.com/SnowingYXY/p/6727341.html
最终又借鉴了:http://blog.csdn.net/speedme/article/details/22398395
可以有助于我们的理解:
- 世间上本来没有集合,(只有数组参考C语言)但有人想要,所以有了集合
- 有人想有可以自动扩展的数组,所以有了List
- 有的人想有没有重复的数组,所以有了set
- 有人想有自动排序的组数,所以有了TreeSet,TreeList,Tree**
-
相同点:
1.List,Set,Map将持有对象一律视为Object型别。
2.Collection--List与Set、Map都是接口,不能实例化。
不同点:
1.map是键值对,key总是独一无二的,value允许重复。
2.每个位置存储的元素个数不同,Collection类型者,每个位置只有一个元素。map是键值对。
所属关系:
扫描二维码关注公众号,回复: 5883729 查看本文章
Collection
--List:将以特定次序存储元素。所以取出来的顺序可能和放入顺序不同。
--ArrayList / LinkedList / Vector
--Set : 不能含有重复的元素
--HashSet / TreeSet
Map
--HashMap
--HashTable
--TreeMap----------------------------------------------------------------------------------------------------------------------------------------------------------
下面这张图是黑马的视频里面的截图:

1.Collection(单列):
将Set与List的共性向上抽取成为Collection接口,所以Collection里面的方法是List与Set共有的。
Collection是最基本的集合接口,声明了适用于JAVA集合(只包括Set和List)的通用方法。 Set 和List 都继承了Conllection。
1.1 Collection接口的方法:
可以通过下面的博客来学习。
--(转自:https://blog.csdn.net/speedme/article/details/22398395)【没有问过大佬,如果不希望我引用,请告诉我】
1.2List(列表): extends Collection (java.util.List)
1.List的特点:
a. List是有序的集合,存储元素与取出元素的顺序是一致的。
b. 有索引,包含带有索引的方法。
c. 允许有重复值。
d. 可以存储null值。
2.List的方法:
| 返回值 | 方法 | 说明 |
| void | add(int index,E element) | 添加元素在index位置上 |
| E | get(int index) | 返回指定位置的元素 |
| E | remove(int index,E element) | 删除index位置上的元素,并把元素值返回 |
| E | set(int index,E element) | 替换index位置元素,并把被替换的元素值返回 |
List主要有三种(应该是常被问到的,Vector好像用的比较少):ArrayList、LinkedList与Vector
1.2.1ArrayList:
1.底层实现:数组
数组的特点:查询快,增删慢。
2.ArrayList特点:
a.List接口由可变数组实现。那么问题就来了,如何实现动态扩容。
这篇文章是我学习的动态扩容:https://www.jianshu.com/p/38e3d67bcc26
(大致的步骤应该是:
1.初始化ArrayList,默认初始容量为10。

注:构造方法我就没复制粘贴了,大家一看链接文章或者自己进入到ArryList里的代码就知道了,很好理解。
2.添加元素,添加元素的时候判断ArrayList的数组容量是否还够添加[add()里面带有判断size的方法。]

3.如果需要扩容就增加数组长度的一般,就是上面文章说的1.5倍。

 //这就是1.5倍的由来--建议大家按照代码流程走一遍会有新感受。
//这就是1.5倍的由来--建议大家按照代码流程走一遍会有新感受。
注:文章中的代码截图仔细阅读有助于理解。
)
b.在扩容后会有数组复制。

c.在强调一遍:可以存储null值。
d.ArrayList非线程安全,实现不是同步的。
3.ArrayList方法:
https://blog.csdn.net/u010890358/article/details/80515284(有大佬写了我就不用再费事了)
1.2.2LinkedList:
1.底层实现:是一个双向链表。
链表特点:查询慢,增删快。
2.LinkedList特点:
a.LinkedList由链表实现。
b.可以存储null值。emmm(我是话唠,再强调一遍)
c.LinkedList非线程安全,实现不是同步的。
2.LinkedList方法:
https://blog.csdn.net/maihilton/article/details/80886655
值得注意的是:add()方法实际等效于addLast()方法;
addFirst()等效于push()方法;
removeFirst()等效于pop()方法。
1.2.3Vector:
底层也是数组实现的,与ArrayList不同,Vector是同步的,所以Vector效率低,使用的也比较少。
1.3Set(集合): extends Collection (java.util.Set)
Set特点:
a.是一个不包含重复元素的集合
b.无索引方法
c.不能使用for循环。
1.3.1HashSet:
1.HashSet特点:
a.底层是一个哈希表(用了哈希表的key),查询速度快。
b.不能保证顺序。
c.允许有null值。
d.实现是不同步的。
e.确保不重复的方法:调用add方法时,add方法调用hashCode方法与equals方法,来判断是否重复。
学好了哈希表的结构,HashSet就可以学会了。
2.LinkedHashSet:
底层是哈希表+链表实现。
实际上就是哈希表的基础上多了一条链表,这条链表用来记录仪元素的存储顺序。(有顺序就可以索引)
1.3.2TreeSet:
1.TreeSet特点:
a. TreeSet中不允许使用null元素!在添加的时候如果添加null,则会抛出NullPointerException异常。
b. TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
c. TreeSet是非同步的方法。 它的iterator 方法返回的迭代器是fail-fast的。
d. TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
----------------------------------------------------------------------------------
HashSet与TreeSet的具体方法可以看下面大佬的文章:https://blog.csdn.net/u010648555/article/details/60573808
注:HashSet与TreeSet在学习的时候应该与HashMap与TreeMap联合在一起看。
2.Map(双列key-value):
Map的特点:
a.Map是双列集合。
b.key与value的类型任意。
c.key不允许重复,value允许重复。
d.key与value一一对应。
常用子类:HashMap与TreeMap
2.1HashMap:
1.底层实现:
jdk1.8之前:数组+链表
jdk1.8起:数组+链表/红黑树
假如红黑树是为了提高查询速度的。
数组结构:把元素进行了分组(相同哈希值是一组)。初始容量为16
链表/红黑树:吧相同的哈希值的元素连接到一起。当链表长度大于8时,转换为红黑树。
本图是数组+链表/红黑树示意图

本图是每个位置存值的示意图(我最开始一直不了解数组里到底有没有存key-value):
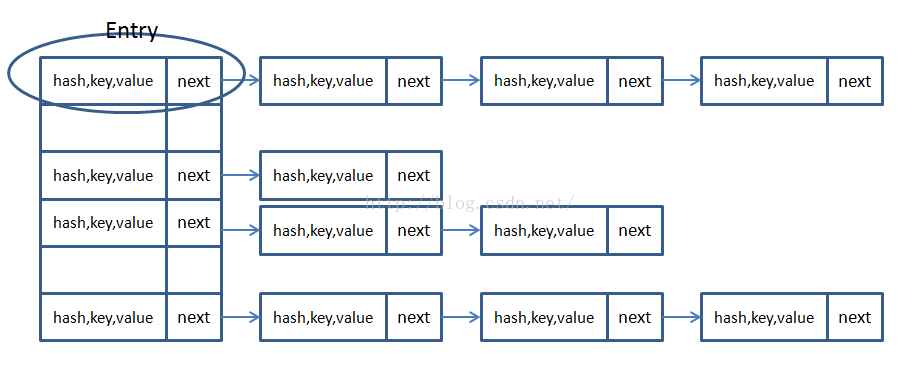
图片来源:https://www.cnblogs.com/little-fly/p/7344285.html
HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,依次来解决Hash冲突的问题。

哈希表的数组是一个Entry数组。
Entry数组里面有的变量和构造函数如下:

一个Entry实际上就是一个节点。指向后面的链表。
hash值的计算我就不截图了,大家可以参考:https://www.jianshu.com/p/70f6207e7bf0
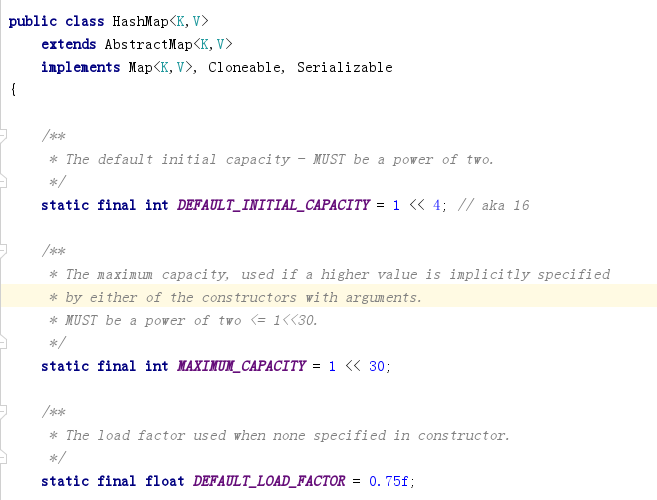
HashMap的默认值:
比如数组默认长度16:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
2.常用方法:
1.添加元素put
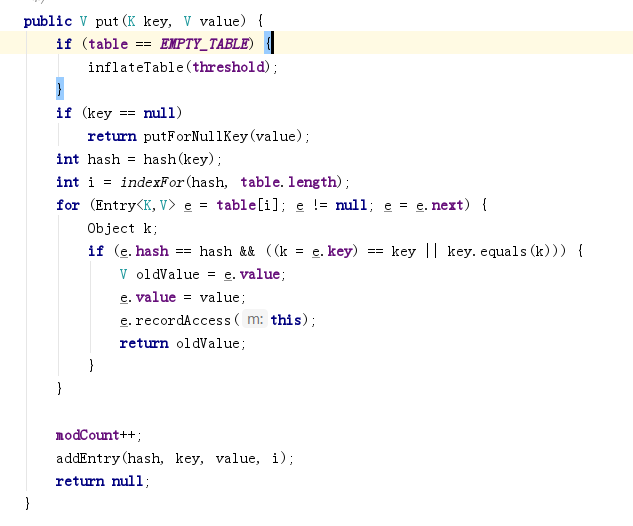
注意这一句:
if(key==null) //如果key为null,则放入数组0号索引位置。
return putForNullKey(Value);
想要更具体的了解一些方法可以参考:https://www.jianshu.com/p/3bf097f4cf0a
在put这里有一个面试问题就是问你put()与get()的工作原理:
理解了它自身的实现流程就可以很好的答出这个问题了。
不过我觉得大家可以参考这篇文章:https://blog.csdn.net/mbshqqb/article/details/79799009
看完了就会有更深的体会。对于HashMap讲解的很全面。真的真的写的非常好。
2.遍历:
一种是使用keySet方法,另一种就是用entrySet。。。
keySet:
1.把Map中所有key取出来存储到Set集合中
Set<String> set=map.keySet();
2.使用迭代器/增强for循环 遍历set集合
Iterator<String> it=set.iterator();
while(it.hashNext){
String key=it.next();
String value=map.get(key);
System.out,println(key+"---"+value);
}
entrySet:
1.使用entrySet方法,把map中的entry对象取出放到set中。
1 Map<String,String> map=new HashMap<>(); 2 Set<Map.Entry<String,String>> set=map.entrySet();
2.遍历set集合,获取entry对象。
1 Iterator<Map.Entry<String,String>> it=set.iterator(); 2 while(it.hasNext()){ 3 Map.Entry<String,String> entry =it.next(); 4 String key=entry.getKey(); 5 String value=entry.getValue(); 6 }
3.entry对象中有getKey()与getValue()两种方法获取键值。
3.HashMap、HashTable与CurrentHashMap的区别:
HashMap线程不安全,但是效率高。允许存储null值(键值都可以)-----继承AbstractMap类
HashTable能够保证线程安全,但是效率低(使用了synchronized保证方法线程安全)。不允许存储null(键值都不可以)------继承Dictionary类
CurrentHashMap就是保证在二者之间的一个改进。
(后面再写吧 这篇文章写的太多了,也可以参考:https://www.cnblogs.com/-new/p/7496323.html)
2.2TreeMap:
直接引用大佬的文章:全面讲解,无需多嘴。